摘 要
当代社会的知识已呈爆炸性增长,其中最常见的知识蕴含在非结构化的自然语言文本当中。信息抽取(Information Extraction)技术通过一组被提及的实体、这些实体之间的关系以及这些实体参与的事件来表达非结构化文本其中的语义知识。作为信息抽取中关键的一环,关系抽取(Relation Extraction)技术,通过判断给定实体之间所属关系,为文本知识理解提供了重要的理论依据和使用价值。
目前基于监督学习的关系抽取需要大量已标记样本,随机选择部分数据标记不仅是对数据资源的浪费,还会直接影响到分类模型最终的准确率。事实上,随着数据收集和储存技术的发展,获取大量未标记自然语言文本变得十分容易,因此设计一种能够有效利用未标记样本集进行关系抽取的算法具有重要的实际价值。
为了解决上述问题,本文以主动学习为切入点,实现了多种采样算法,主要有不确定性,多样性,代表性等算法,在验证主动学习适用于关系抽取任务的基础上,通过融合多种采样标准最终获得一个可以在多个数据集和多种学习模型下仍具有效性的主动学习样本选择策略。
实验证明,本文提出的多标准融合采样策略是一个具有有效性、健壮性的策略,与多个单策略采样算法相比,在多个数据集上都能够取得相当或者更高的分类精度。
关键词:主动学习,深度学习,关系抽取,多标准
ABSTRACT
Knowledge in contemporary society has been growing explosively. The most common knowl- edge is contained in unstructured natural language texts. Most of its semantic knowledge can be expressed by a group of mentioned entities, the relationship between these entities and the events that these entities participate in. As a key part of information extraction, relationship extraction has important theoretical significance and practical application.
At present, a large number of labeled samples are needed in relation extraction based on supervised learning. Random annotation is not only a waste of data resources, but also affects the performance of classifier. In fact, with the development of data collection and storage technology, it is very easy to obtain a large amount of unlabeled natural language text. It is of great practical value to design an algorithm that can effectively use the unlabeled sample set.
In order to solve the above problems, the paper takes active learning as the starting point, designs and implements a variety of sample selection algorithms, including uncertainty, representativeness, diversity, etc. On the basis of verifying the applicability of active learning to relation extraction tasks, an active learning sample selection strategy which can be effective in multiple datasets and learning models is finally obtained by integrating multiple sampling standards.
Experiments show that the multi-standard fusion sampling strategy proposed in this paper is an effective and universal strategy. Compared with multiple single strategy sampling algorithms, it can achieve comparable or higher classification accuracy on multiple datasets.
KEY WORDS: Active Learning, Deep Learning, Relation Extraction, Multi-Criteria
ii
目 录
第一章 引言 1
1.1 研究背景 1
1.2 国内外研究现状 2
1.2.1 关系抽取研究现状 2
1.2.2 主动学习研究现状 3
1.3 研究目标与内容 4
1.4 本文组织结构 4
1.5 本章小结 5
第二章 相关工作 6
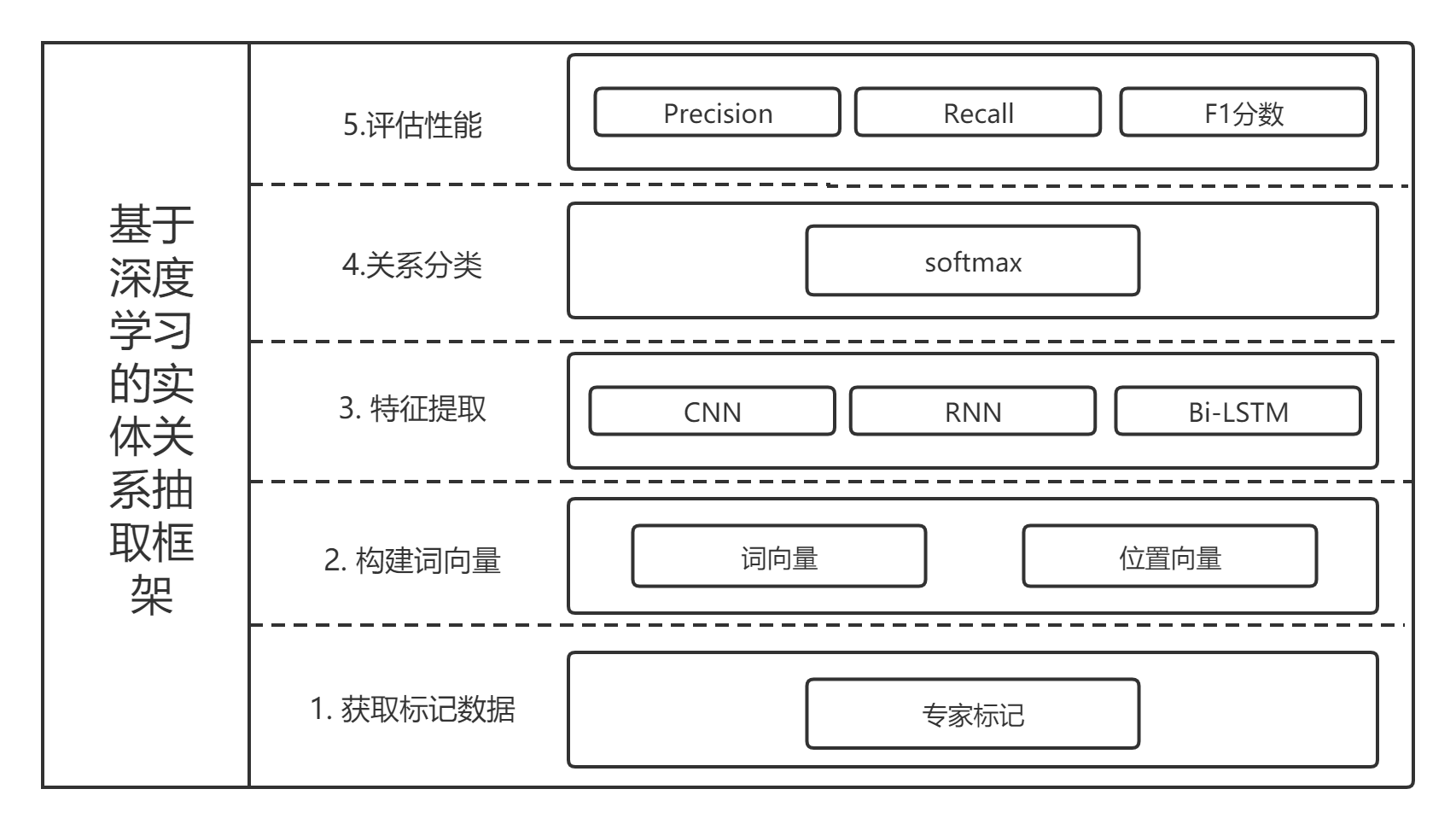
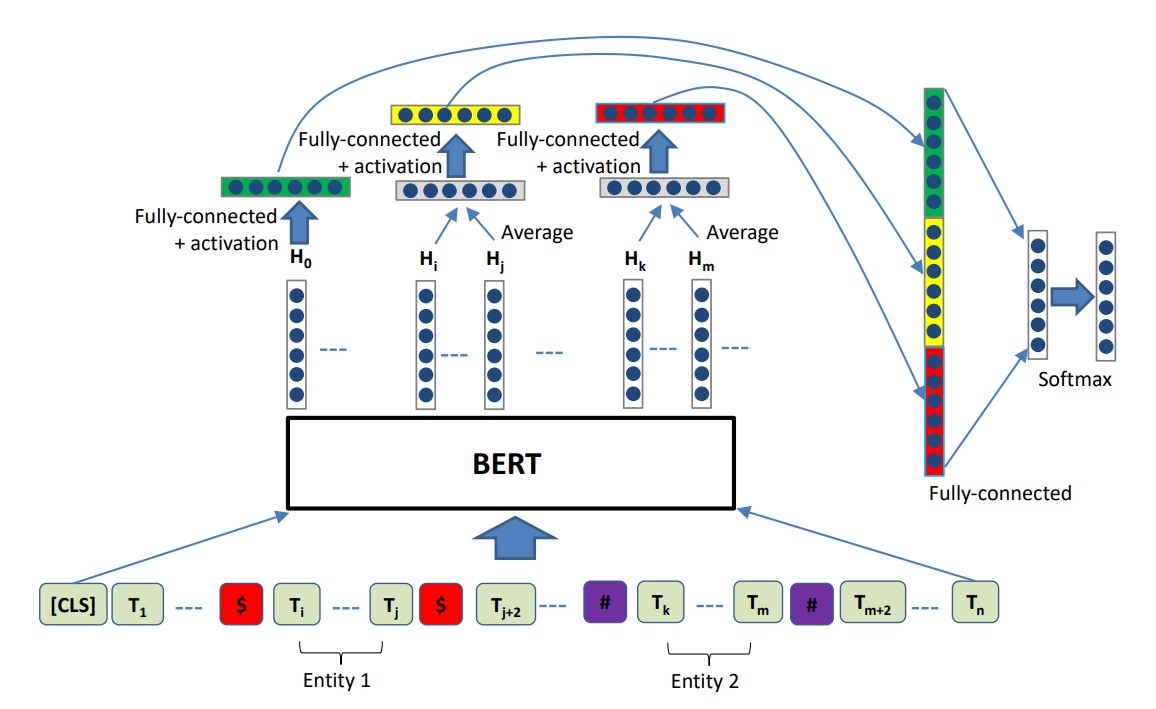
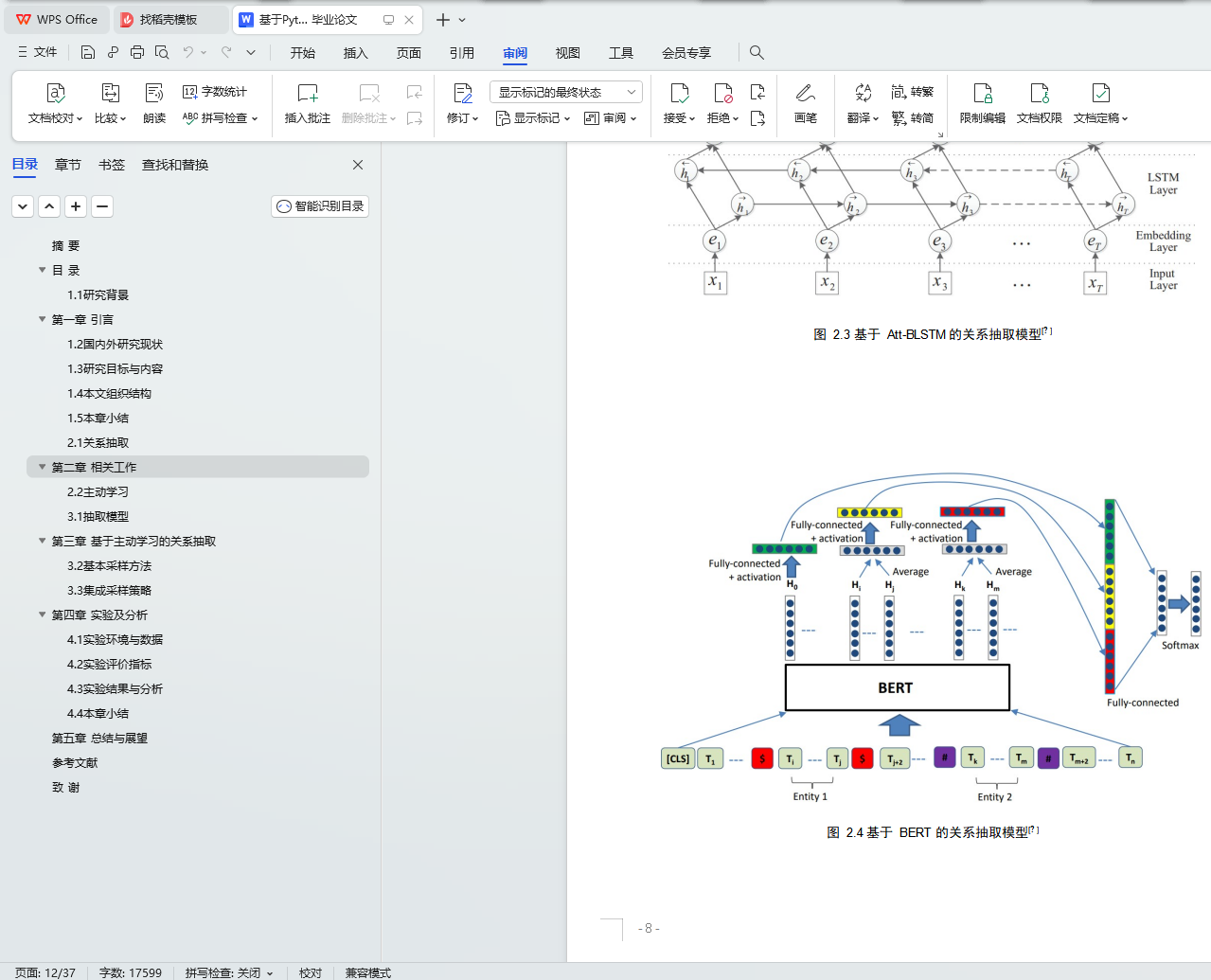
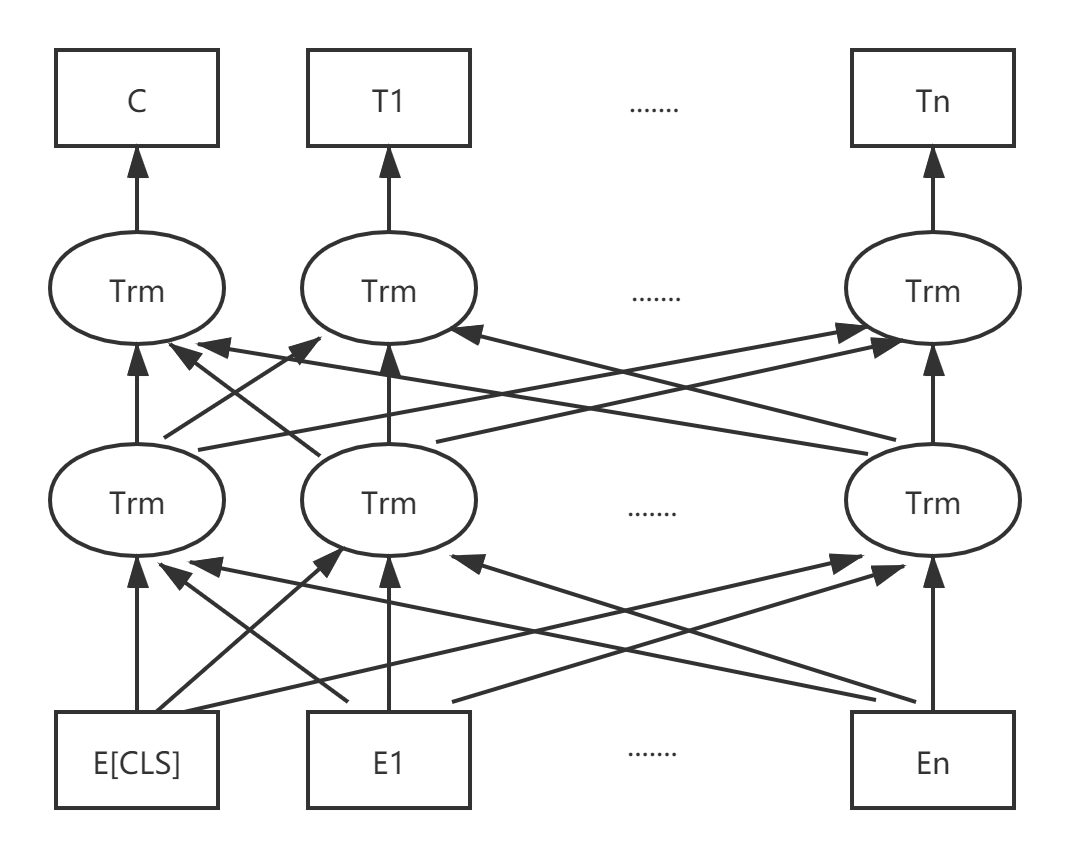
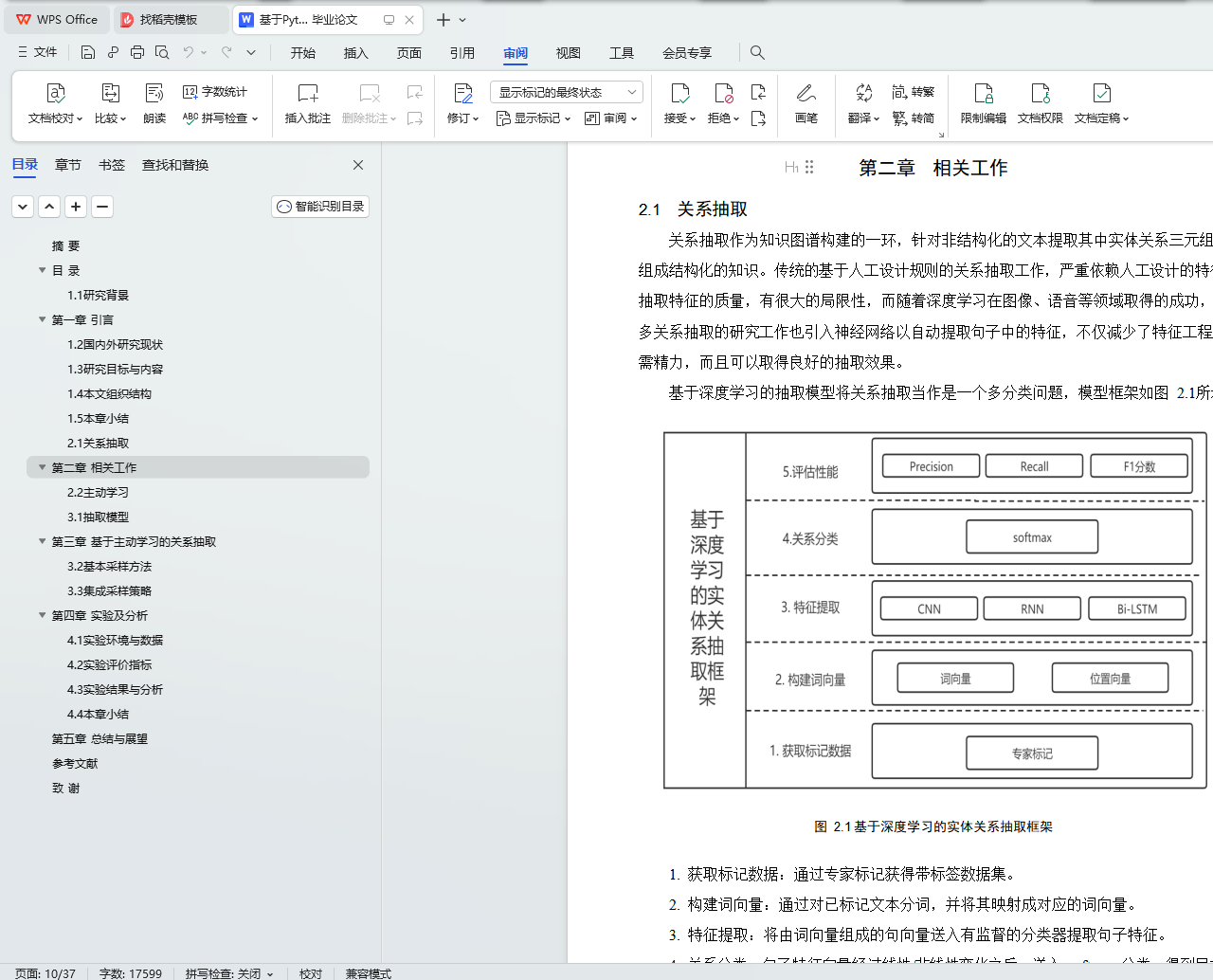
2.1 关系抽取 6
2.2 主动学习 9
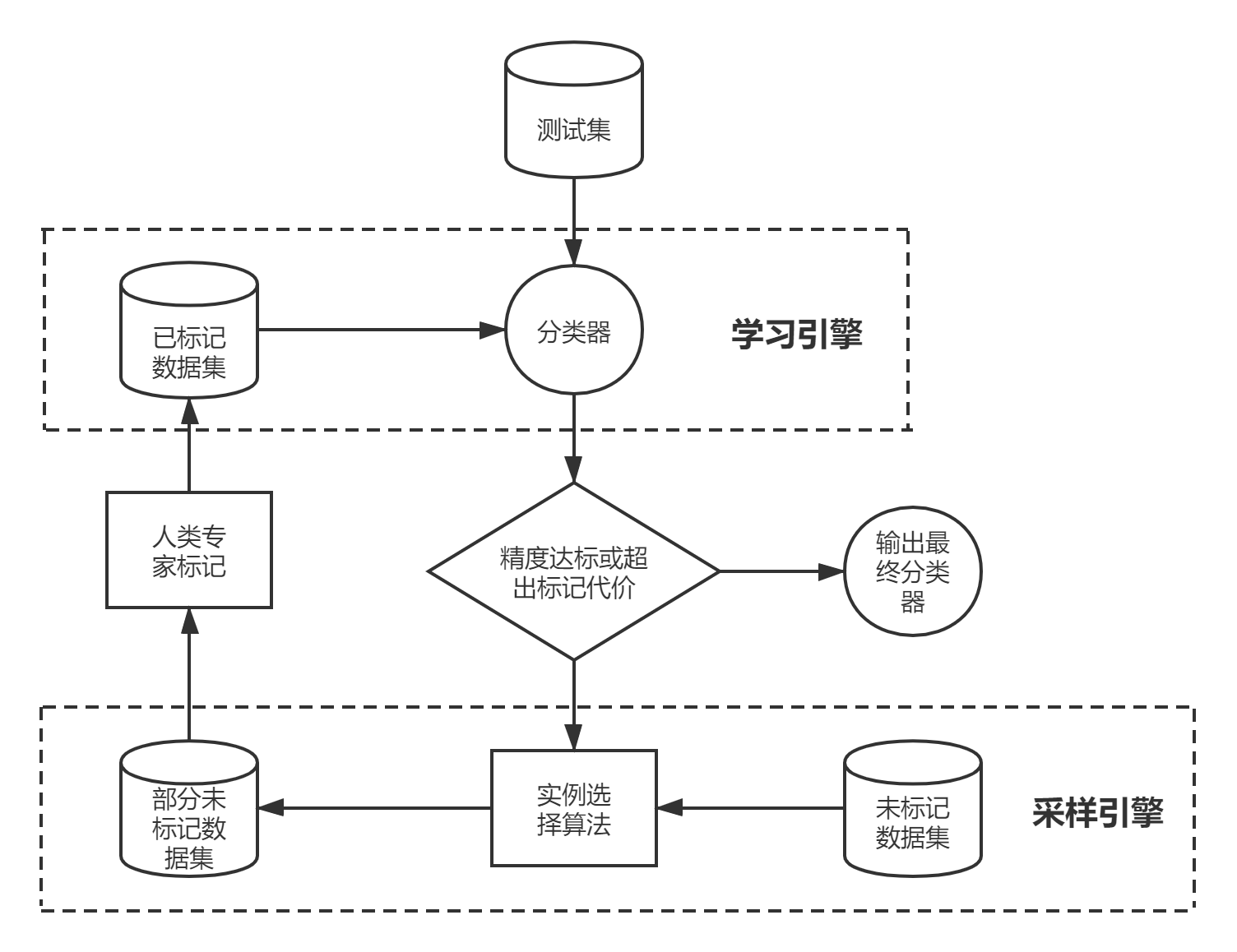
2.2.1 主动学习算法模型 9
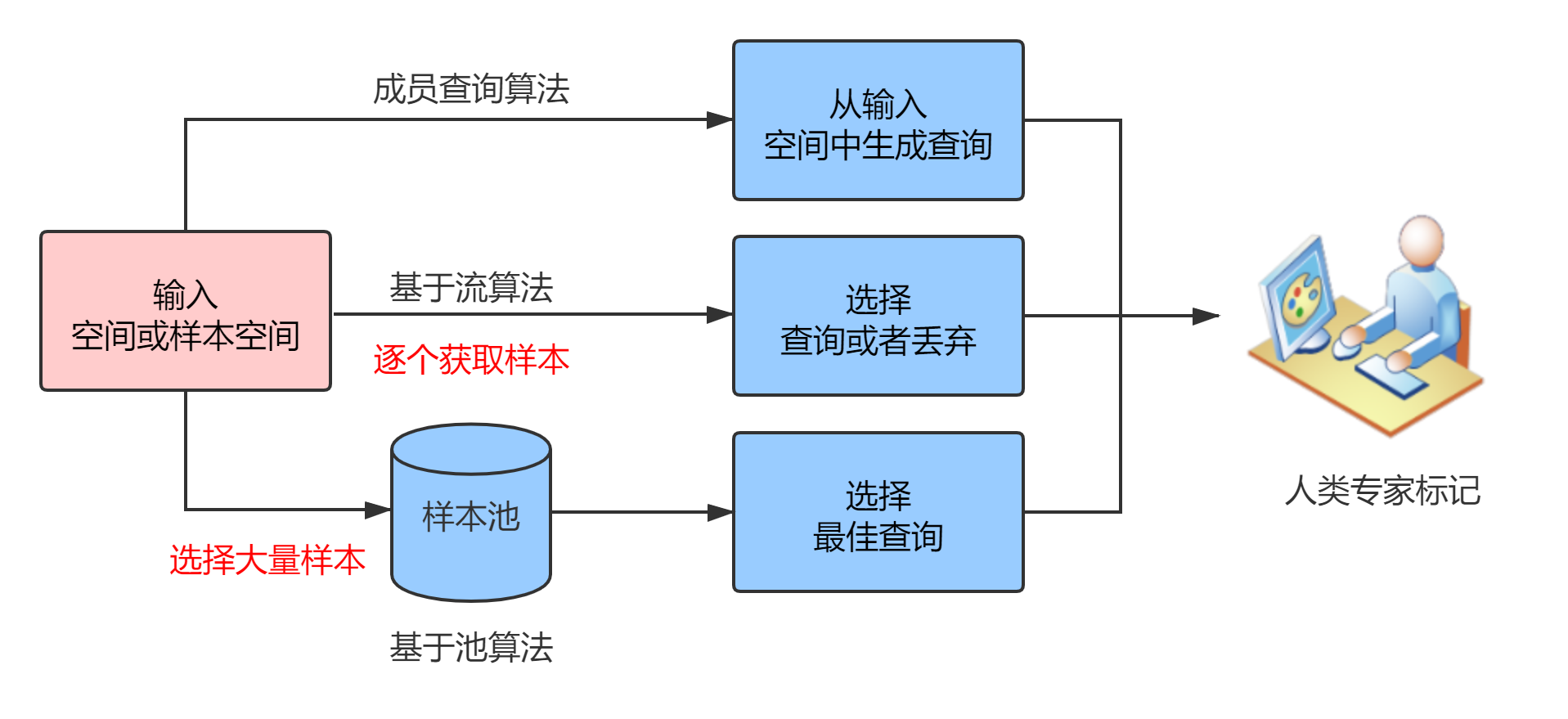
2.2.2 主流主动学习介绍 10
2.3 本章小结 11
第三章 基于主动学习的关系抽取 12
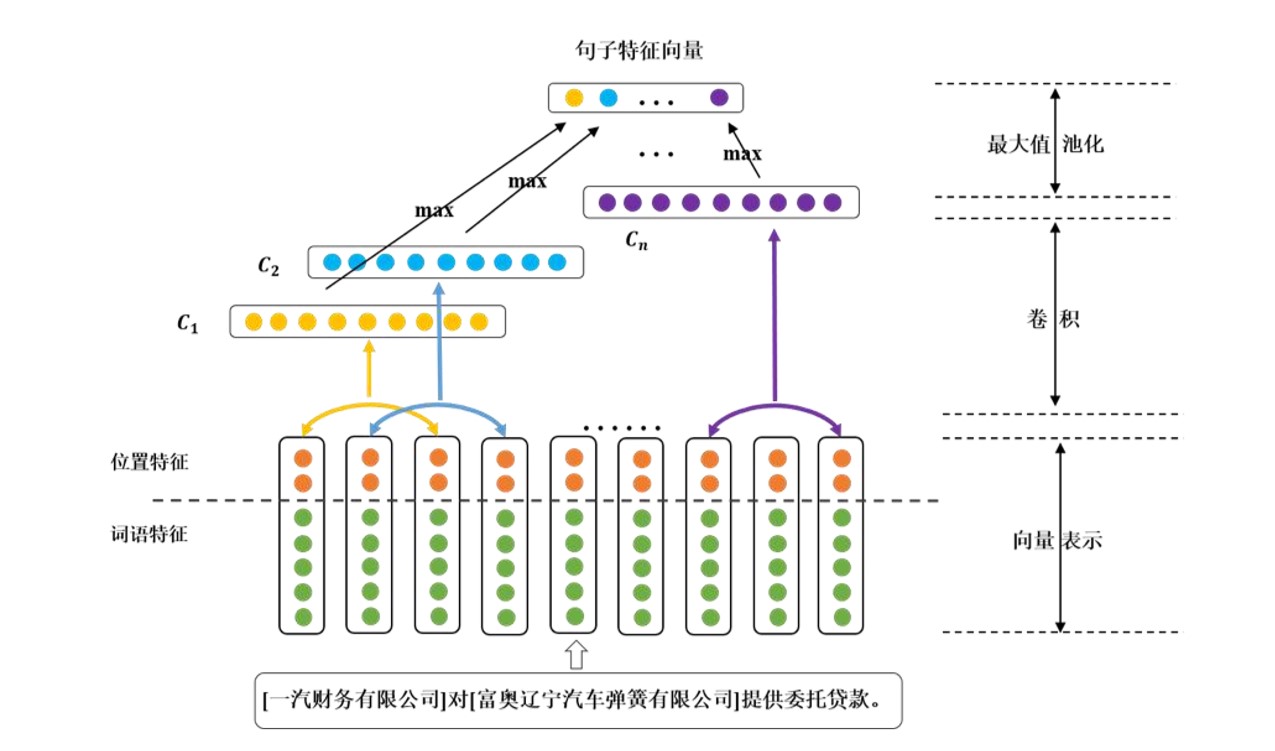
3.1 抽取模型 12
3.2 基本采样方法 14
3.2.1 基于不确定性的采样方法 14
3.2.2 基于多样性的采样方法 15
3.2.3 基于代表性的采样方法 16
3.3 集成采样策略 16
3.3.1 基于多标准的赋权采样策略 17
3.3.2 基于多标准的逐层采样策略 18
3.4 本章小结 19
第四章 实验及分析 20
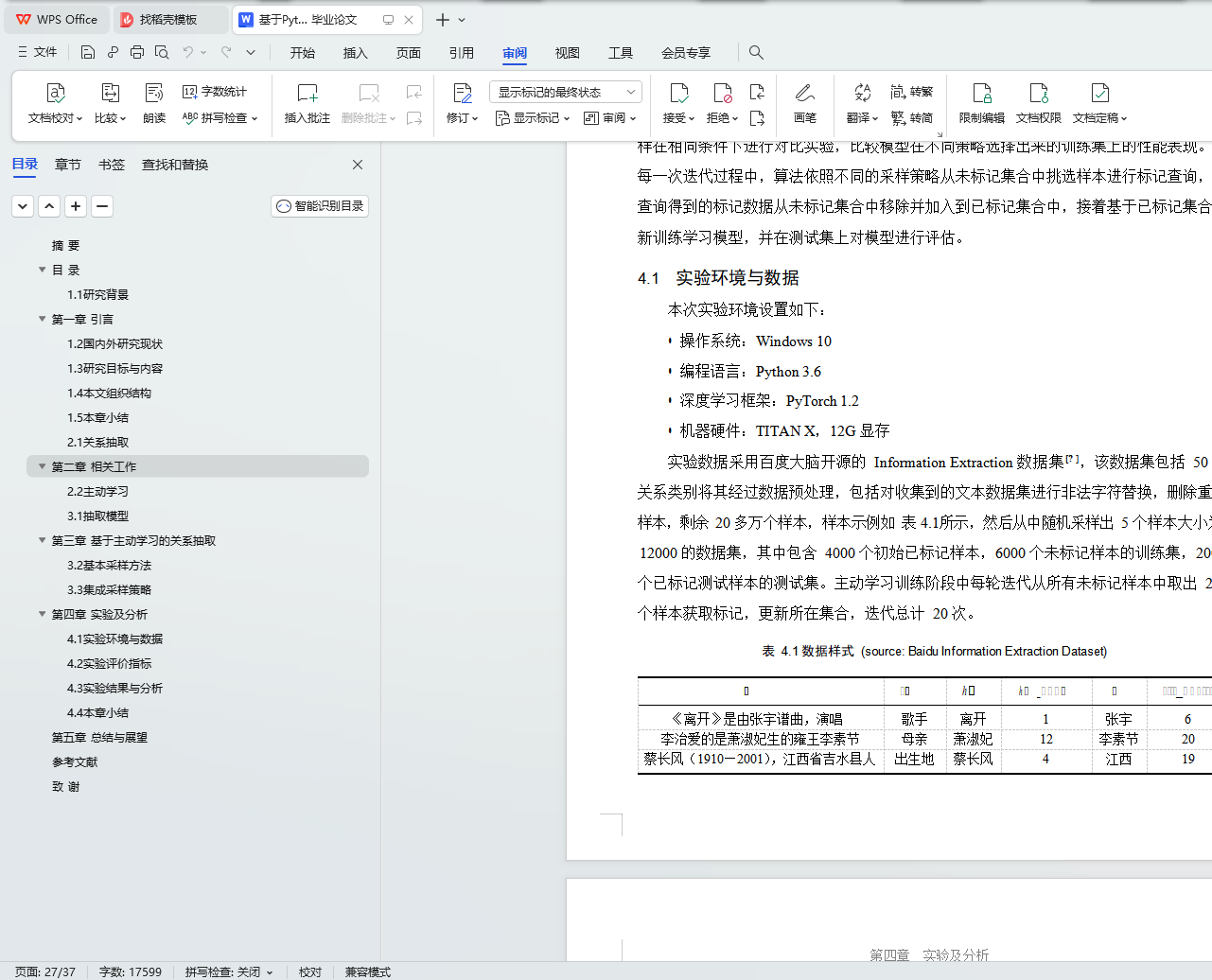
4.1 实验环境与数据 20
4.2 实验评价指标 21
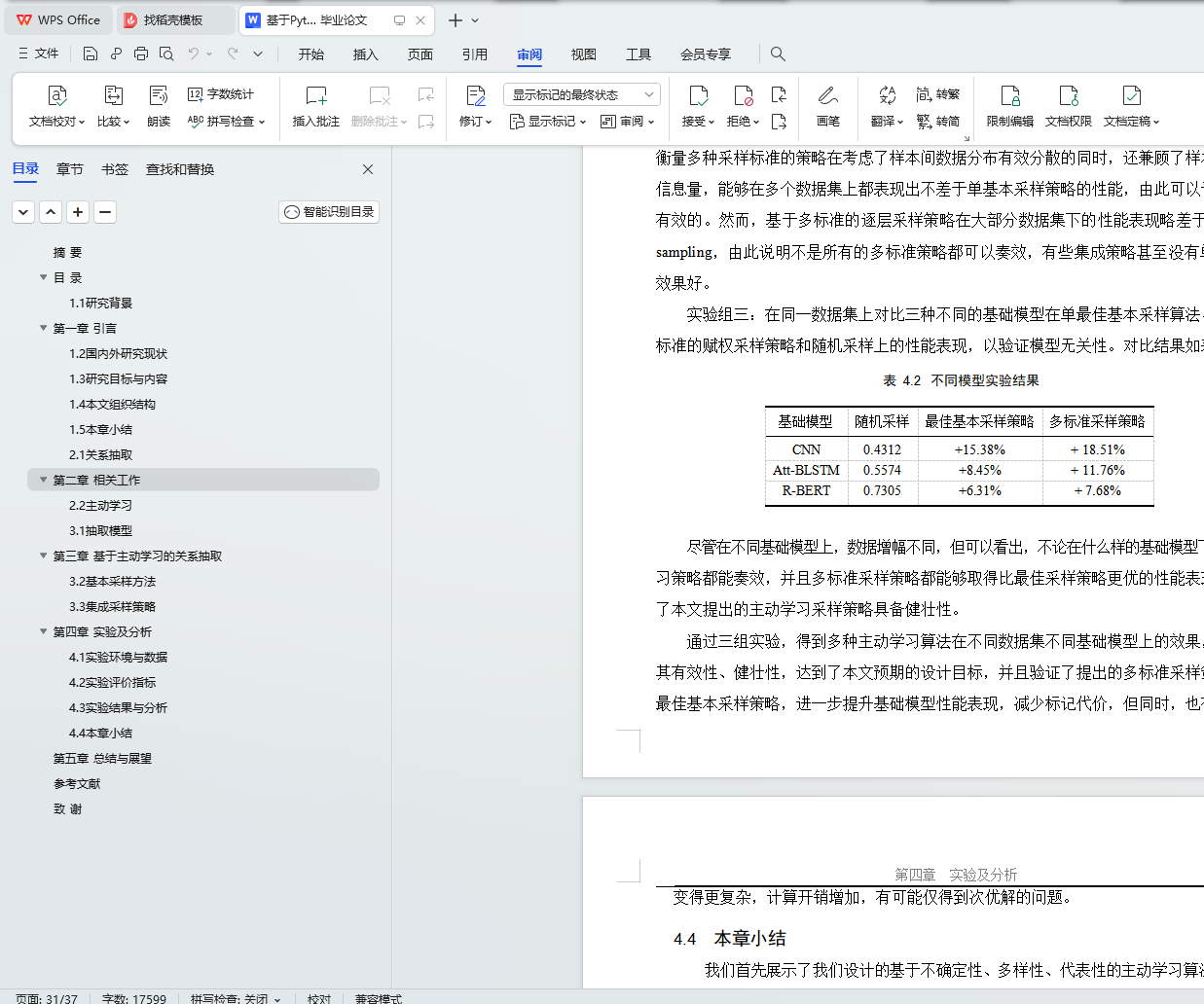
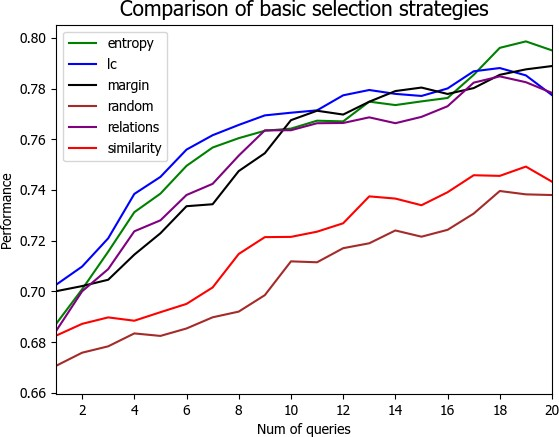
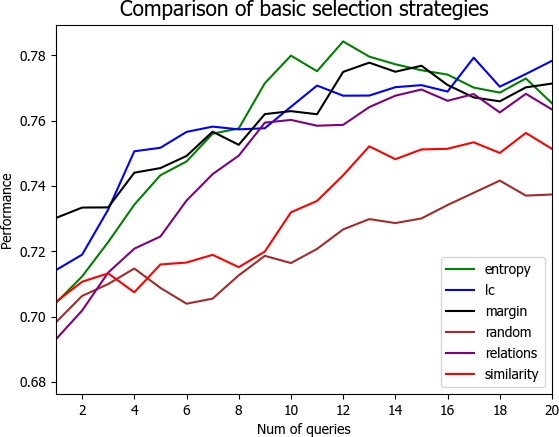
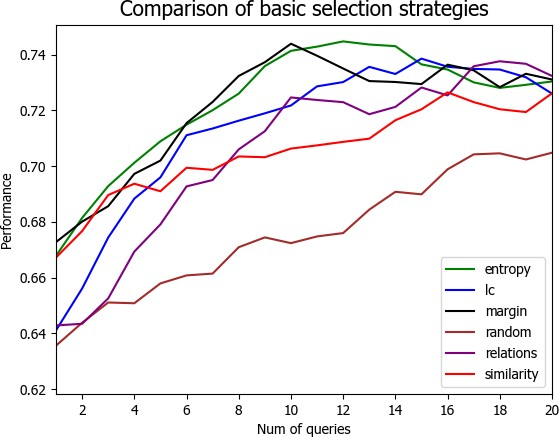
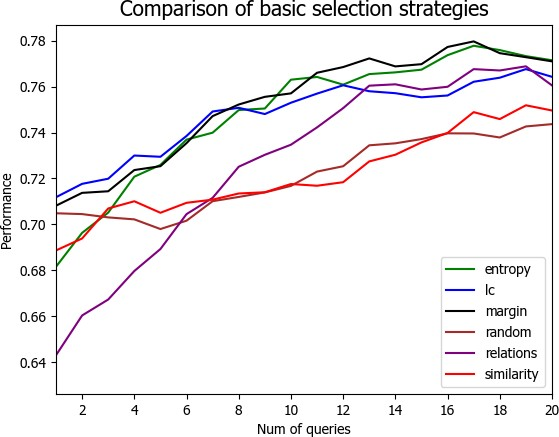
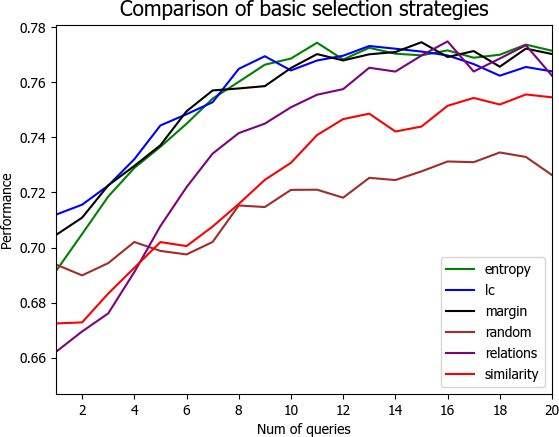
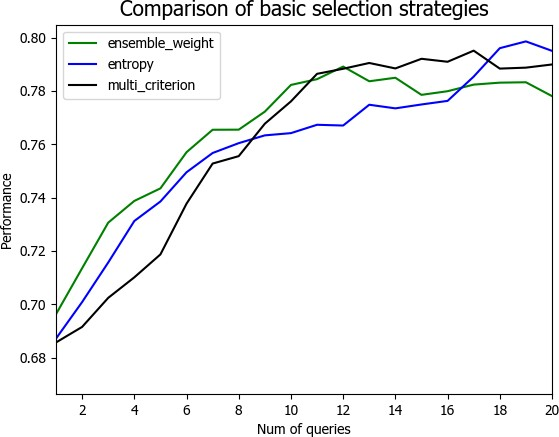
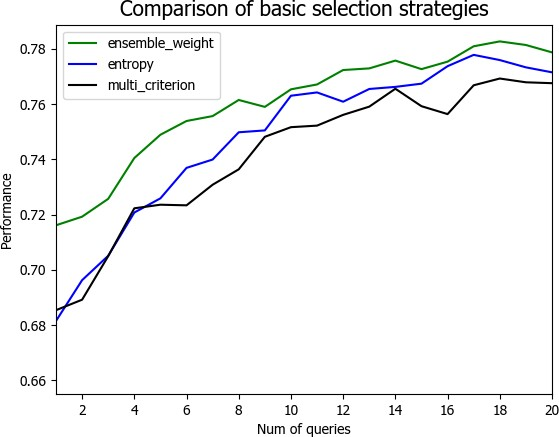
4.3 实验结果与分析 21
4.4 本章小结 25
第五章 总结与展望 26
致谢 27
参考文献 27