一、网络爬虫的背景
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了,人们对信息的获取逐渐被网络所取代。目前,人们大多通过搜索引擎获得有用的信息,因此,搜索引擎技术的发展将直接影响人们获得所需信息的速度和质量。
作为搜索引擎技术核心元素之一,网络爬虫源于上个世纪90年代的Google等搜索引擎,爬虫用于抓取互联网上的Web页面,再由搜索引擎进行索引和存储,从而为我们提供检索服务。网络爬虫位于搜索引擎的后台,并未直接与用户接触,属于幕后技术,因此在较长的时间内并未被广大开发人员所关注。
人们对网络爬虫技术的关注度快速上升。其中,很大的推动力来自于各种个人、中小型爬虫。爬虫是一个实践性很强的技术活,互联网上爬虫数量的增长速度剧增。爬虫技术历经20多年的发展,技术已日趋多样。
二、网络爬虫的研究现状
随着网络信息资源的指数化增长和网络信息资源的动态变化,传统搜索引擎提供的信息检索服务已不能满足人们对个性化服务日益增长的需求,正面临着巨大的挑战。以什么样的网络接入策略,提高搜索效率,已成为近年来专业搜索引擎网络爬虫研究的主要问题之一。
网络爬虫是搜索引擎的重要组成部分,目前比较流行的搜索引擎有百度、谷歌、雅虎、必应等,可以说没有网络爬虫的存在,就可能没有搜索引擎的存在,出于商业保密的考虑,各种搜索引擎使用的爬虫系统的技术内部人员一般不公开,现有文献仅限于摘要介绍。在很大程度上,Web搜索引擎、数字图书馆和其他Web应用都依赖于网络爬虫获取的HTML文档信息。例如为了提供多种搜索引擎服务,谷歌、雅虎和MSN的爬虫定期遍历数十亿网页,网络购物智能代理通过价格比较未用户推荐价格优惠的产品。
本文通过爬取影视数据通过分析让为用户观影时提供决策支持。
三、研究主要主要内容
本文主要基于Python的Scrapy框架,设计并实现对豆瓣电影网上海量影视数据的采集,清洗,保存到本地。并用Pandas,Numpy库对影评进行处理,使用WordCloud对处理的影评进行词云展示,让用户对电影有一个认知。用Matplotlib、Pygal展示口碑+人气电影。
四、运行环境和系统结构
运行环境:Windows操作系统下的Python3环境。
系统结构:本爬虫系统分为数据爬取模块(爬取豆瓣TOP250排行榜以及电影详细数据)、数据分析模块(数据预处理及分析)、数据可视化模块(词云展示以及绘图展示),如图3.1所示。
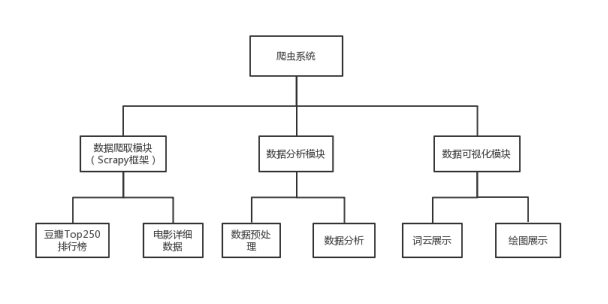
图3.1 系统结构
五、设计思路
用Python的Scrapy框架编写爬虫程序抓取了Top250排行榜的影片榜单信息,爬取电影的短评、评分、评价数量等数据,并结合Python的多个库(Pandas、Numpy、Matplotlib),使用Numpy系统存储和处理大型数据,中文Jieba分词工具进行爬取数据的分词文本处理,wordcloud库处理数据关键词,最终通过词云图、网页动态图展示观众情感倾向和影片评分统计等信息。流程如图4.1所示。
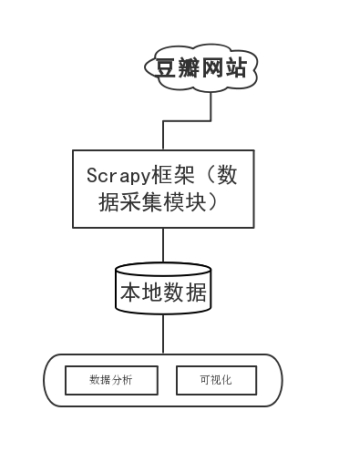
图4.1 流程图
六、电影数据可视化及分析
6.1 影评数据词云可视化
用词云展示影评,根据影评中词语出现频率设计不同大小已形成视觉上的不同效果,形成“关键词云层”或“关键词渲染”,从而使读者只要“一瞥”即可领略文本的主旨。这种展示方式已经成为文本展示的样板。
具体思路:先循环遍历出影评文件,用正则表达式匹配单词符,去除换行符,转换成字符串,用jieba分词进行中文分词,由于中文分词不会把那些虚词去掉什么的,这些虚词又会占高频次,需要下载个停用词文本,把那些虚词去掉,统计词频,用词云展示,为了用下载好的图片作词云背景,还需要用PIL处理图像,最后词云化。
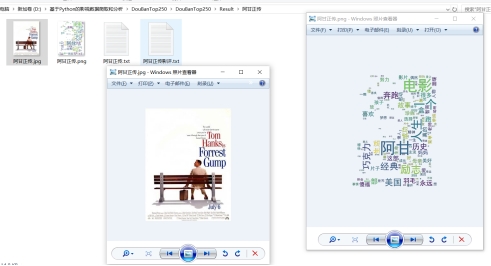
图4.15 词云运行结果
6.2 近年来排行榜电影各类图
思路:打开top250.json文件,遍历得出每部电影的上映日期(用正则表达式筛选,返回结果是列表,直接用sort函数排序,筛选出第一个上映日期)、电影类型(每部电影都有很多个分类,在爬取的时候已经直接选择该片主要类型),得出这三个数据后,需要遍历得出每个种类在哪一年有电影,最后再用matplotlib做出折线图,已png格式保存成图片。运行结果如图4.16。
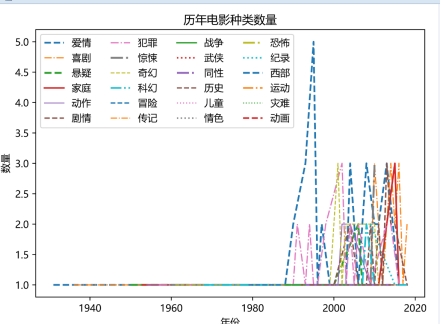
图4.16 历年电影种类数量
结论:在上世纪90年代有那么几年出了很多高分的爱情片,可以说那几年爱情片占市场较大份额,而到了2000年后各种电影发展较为均匀,各种类的电影都有优质作品。
6.3 电影种类数量饼图
这段代码实现比较简单,直接用字典统计各个种类的电影数量,然后用pygal做饼图,保存为svg格式,svg格式可交互操作。结果如图4.17
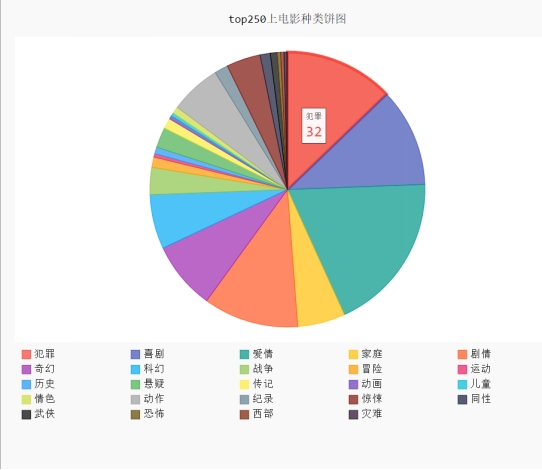
图4.17 top250上电影种类饼状图
结论:爱情、犯罪、喜剧、剧情、奇幻的电影在排行榜占的份额达到一半,而战争、悬疑、惊悚、灾难之类的占的份额极低。由此可以判断出常见类型的电影相比较于偏门分类来说更能出高分电影。
6.4 各国电影柱形图
获得电影制片国家时,中国有中国大陆,中国台湾,中国香港,需要直接归纳成中国不细分,实现过程也是用字典统计各国电影数量。结果如图4.18
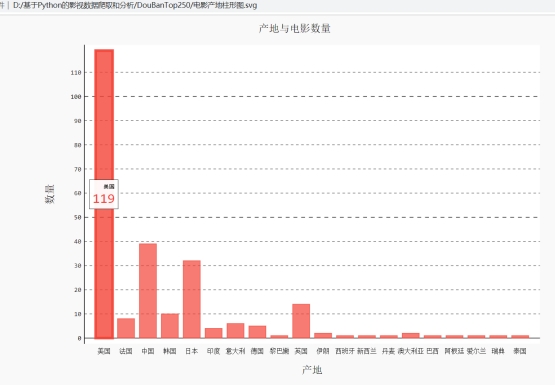
图4.18 产地与电影数量
结论:就目前而言排行榜上美国的电影还是属于霸主级别,而中国与美国在电影方面还是有不小的差距。
6.5 作品数量前十导演
结果如图4.19
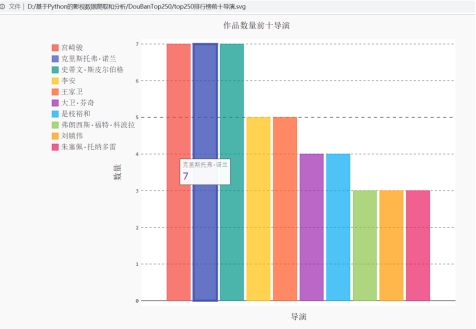
图4.19 作品数量前十导演
6.6 人气前二十的电影对比图
思路:获取电影名字、豆瓣排名、豆瓣评分、评论人数(原始数据转成整数除以万,以万为单位)、片长,添加到字典中,键为电影名字,按评论人数排序筛选前二十部,用此数据做雷达图。结果如图4.20
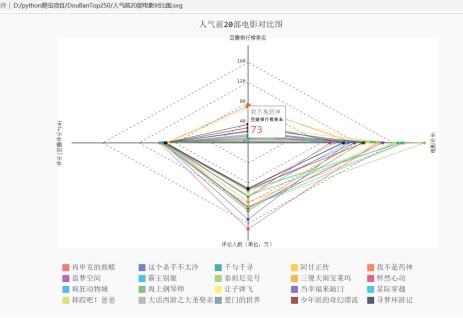
图4.20 人气前20部电影对比图
结论:可以看到《我不是药神》和《让子弹飞》排名不高(相比较于其他),人气却不小,超过了一些老片,值得一看。
总结
在本次毕业设计的过程中,首先要做的就是Python和Pycharm的安装问题,安装了Python和Pycharm,并完成了基本配置。
Pycharm安装好后,在老师的细心教导下和同学们的帮助下,慢慢地弄清楚了安装Scrapy的步骤和注意点,并使用Scrapy初步完成了对豆瓣电影Top250网站电影基本数据和影评的采集。完成对数据的绘图、影评词云化。其中许多的细节尚有待改进,如今后若有机会将继续完善。
通过这次毕业设计,完成了简单的爬虫,更重要的是学习了许多重要的知识。整个过程中,涉猎了Scrapy的使用、Scrapy对接Selenium、分布式爬虫原理、Scrapy分布式实现、Scrapy-Client的使用等爬虫相关技术。不仅学会了很多概念性的知识,还极大地锻炼了动手能力,发现错误,不厌其烦地寻找错误根源并想办法去解决问题的能力,还丰富了学识和见解。相信给以后的学习和生活中能够带来十分多的帮助和支持。
参考文献
[1] 成文莹, 李秀敏. 基于Python的电影数据爬取与数据可视化分析研究[J]. 电脑知识与技术:学术版, 2019, 15(11):4.
[2] 高巍, 孙盼盼, 李大舟. 基于Python爬虫的电影数据可视化分析[J]. 沈阳化工大学学报, 2020, 34(1):6.
[3] 裴丽丽. 基于Python语言对电影影评数据爬虫与词云制作[J]. 信息记录材料, 2020, 21(5):3.
[4] 乔士秀, 圣文顺. 基于网络爬虫的数据可视化系统设计与实现[J]. 电子技术与软件工程, 2021, 000(012):P.138-141.
[5] 杨应浩. 基于Python的电影信息爬取与数据可视化分析[J]. 新型工业化, 2021, 11(7):71,73.
[6] 胡晓燕. 基于Python的可视化数据分析平台设计与实现[J]. 信息与电脑, 2018(17):3.
[7] 张腾. 中国电影市场票房趋势研究[J]. 福建质量管理, 2019.
[8]安子建. 基于Scrapy框架的网络爬虫实现与数据抓取分析[D].吉林大学,2017.
[9]赵绿草,饶佳冬.基于python的二手房数据爬取及分析[J].电脑知识与技术,2019,15(19):1-3.
[10]孙瑜. 基于Scrapy框架的网络爬虫系统的设计与实现[D].北京交通大学,2019.
[11]丁忠祥,杨彦红,杜彦明.基于Scrapy框架影视信息爬取的设计与实现[J].北京印刷学院学报,2018,26(09):92-97.
[12]韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019,29(02):139-142.
[13]李刚.疯狂Python讲义[M].电子工业出版社,2018,12(01).
