5 基于Hadoop的护肤品推荐系统实现与测试
本章将完成具体的实现过程及测试工作。首先对开发环境进行描述,然后分别介绍定时任务、离线计算、数据更新和web服务端模块的实现,最后对系统执行测试。
5.1 系统开发环境
在正式开发前一步,应该确定本系统需要的开发环境,由于系统的几个模块之间用到的框架及技术不一样,因此可以分为两部分开发环境。
|
环境
|
定时任务模块/web服务点模块开发环境
|
离线计算模块/数据更新模块开发环境
|
|
硬件环境
|
CPU
|
Intel(R)Core(TM)i5-7200U
|
|
内存
|
4.00G
|
|
软件环境
|
操作系统
|
Windows7(64位)
|
|
开发工具
|
PyCharm
|
Intellij idea
|
|
开发语言
|
Python
|
Java
|
5.2 系统功能实现
前面第四章中对基于Hadoop的护肤品推荐系统的总体架构做了设计并按照功能将其分成了若千个模块并分别进行了设计。本节主要根据第四章的功能模块设计进行具体实现,完成定时任务模块、离线计算模块、数据更新模块和web服务端模块的开发。
5.2.1 定时任务模块实现
定时任务模块的核心任务程序scheduler.py使用python开发,由crontab托管它主要包含3个任务,分别是:定时上传用户浏览日志和商品属性关联信息文件至HDFS:定时调用离线计算模块做计算:定时调用数据更新模块同步数据至Redis。下面详细介绍这3个任务的实现过程。
(1)定时上传日志文件和商品属性文件到HDFS该任务将本地的log文件和商品tag属性文件上传至HDFS上,用作推荐计算程序的输入数据源。
(2)定时调用离线计算模块
在计算之前,已经将MapReduce程序包放至Hadoop集群上了,所以这里的任务就是定时调用离线计算模块对应的MapReduce程序包使之执行MapReduce计算。
(3)定时调用数据更新模块
当执行完新的计算后,会产生新的数据比如推荐商品列表结果数据、热门商品列表结果数据等,此时就需要将HDFS上的最新数据同步至存储端,而该任务的作用就是调用数据更新模块来完成这个同步操作。
在这个任务执行之前,数据更新模块的实现程序已经打包成了一个可运行的jar包放在了定时任务程序所在的同级目录,所以这里的工作只需要调用它即可。
5.2.2 离线计算模块实现
离线计算模块就是将来打包成jar包用以执行MapReduce计算的程序。该模块主要包含两部分功能,一个是计算用户推荐商品列表结果的程序逻辑,另一个是计算网站热门商品列表结果的程序逻辑。下面详细介绍该模块的这2个功能的实现过程。
(1)计算用户推荐列表程序实现
根据前面对该程序的设计可知其包含了12个主要的步骤,下面依次介绍各个步骤的具体实现:
①商品表示
ItemAndTagInfoNormalizationJob。
该Job简单来说就是为每个物品提取出一个属性集合出来,用这个属性集合表示这个物品,实际上就是将一个物品抽象成一个属性向量。由于本系统中的属性是结构化的属性,所以在对各个属性进行特征映射时采用的是布尔类型方式,即有这个属性则权重就为1、没有则权重就为0。在物品表示的过程中,权重的表示方法如下:记某个属性为tag、它在商品item中、商品item总共有n个属性,则属性tag在商品item 中的权重为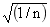 。此步骤结束之后,各个商品均由一个特征向量表示这个向量中由各个属性的Id和属性所占的权重构成。
。此步骤结束之后,各个商品均由一个特征向量表示这个向量中由各个属性的Id和属性所占的权重构成。
②预处理用户日志
PreprocessDataJob。
该Job的实现逻辑是对原始的用户日志做一个预处理操作,剔除掉非法数据去重等。该Job由DataPreprocessMapper类和DataPreprocessReducer类来完成其逻辑。输入数据是用户行为日志文件。
③获取用户历史访问商品记录集合
ConvertLogtoSourcedata。
该Job对预处理过的日志做进一步的处理,以用户Id为主键,将用户访问过的所有商品聚集到一起(可能会包含重复的商品)。为下一步的处理做数据准备工作该Job由MakeUserKeyMapper类和CreateIndexReducer类来完成其逻辑。输入数据是步骤2的结果数据。
④计算用户评分向量
SourcedataToltemPrefsJob。
该Job的实现逻辑是根据用户在网站的浏览日志,计算出其对item的喜欢程度(用户对商品的评分计算规则是:每访问一次商品加一定数值的分数,最终累加用户对商品的评分总和即得到最终用户对商品的总喜欢度)。
⑤分割用户评分向量
UserVecotrSplitJob。
该Job的实现逻辑是配置分割用户评分向量(在上一步中的输出数据是以用户为主键,每一行表示用户对哪些商品有评分;这一步中将数据变为以商品为主键每一行表示这个商品被哪些用户评分过)。
⑥合并商品表示向量与用户评分向量
CombineTaglnfoTableAndItemRatingsJob该Job的实现逻辑是合并商品表示向量和分割之后的用户评分向量。即以商品为主键,合并该商品对应的两部分数据(这两部分数据分别是分割之后的用户评分向量和该商品的tag特征向量)。简单来说就是合并这两路数据:用户过去喜欢什么商品、商品有哪些属性,为后面计算用户喜欢什么属性做数据准备工作。
⑦用户特征学习
CaculUserProfilesJob。
该Job的实现逻辑是计算得到用户对属性的喜好程度即User Profiles。前面已经知道了用户过去喜欢哪些商品、又知道了各个商品有哪些属性,因此,在这步中以商品为中间介质,用商品的用户评分矩阵乘以它的表示向量。
⑧统计属性出现次数
CalculDFJob。
该Job的实现逻辑是计算IDF,即对商品tag信息表里面每个tag出现的次数进行计数。并对属性总出现次数取倒数。
该Job由InverseDocumentFrequencyMapper类和InverseDocumentFrequencyReducer类来完成其逻辑。输入数据是商品属性关联信息文件。
⑨合并商品表示向量用户特征向量及属性次数
CombineTagMatrixAndIDFAndUserprofileJob。
该Job的实现逻辑是合并三路数据(商品表示向量、用户特征向量、属性次数)为后面的计算步骤提供数据。简单理解就是合并这3类数据:商品有哪些属性、用户喜欢什么属性、各个属性分别出现了多少次。合并后以属性为主键,其它三路数据集合为值部分。
⑩用户特征向量与商品表示向量相乘
SplitRecomCalculateJob。
该Job的实现逻辑是根据前面三个表格合并后的结果进行重新组合、打散。由于前面已经知道了用户喜欢哪些属性(User profiles)、又知道了各个商品有哪些属性(Item Representation),所以,这步中只需要以属性为中间介质,让属性的用户评分向量乘以属性的所属商品向量,即可计算用户对item的喜欢分数
⑪计算每个用户和商品组合的推荐值
CalcuSplitBigTableJob。
该Job的实现逻辑是计算每个user和item组合的总喜欢度分数。由于前面计算得到的结果比较分散,所以在这步中以userId:itemId组合的方式为主键,累加主键对应的值部分的分数总和。
⑫计算最后的推荐结果
RecommenderJob。
该Job的实现逻辑是首先将前面步骤中的userld:itemld主键拆成以userId为主键,然后将该用户对应的所有商品及喜欢度总分数放到一个集合中并作为主键对应的值部分,然后对该集合中的商品元素按总分数进行降序排序,最后整理输出。
5.2.3 数据更新模块实现
数据更新模块的作用是使HDFS上的最新数据同步到Redis中,其中同步的数据包括三部分,分别是用户的推荐商品列表结果、网站热门商品列表数据以及用户的历史行为记录日志信息。下面详细介绍这3 个任务的实现过程。
(1)更新推荐列表实现
前面离线计算模块执行完MapReduce计算之后,将推荐列表结果存放在了HDFS指定的目录下,所以,本模块首先从Hadoop集群的HDFS目录获取到最新的推荐列表结果。在同步之前先将Redis中之前的推荐列表清空。由于将来要对商品排序,所以保存在Redis中的推荐结果数据类型为Sorted Set类型,key部分为用户编号member
部分为商品编号,score部分为推荐分数。后续排序的依据是推荐分数。
(2)更新热门列表实现
前面离线计算模块执行完MapReduce计算之后,将热门商品列表结果存放在了HDFS指定的目录下,所以,本模块首先从Hadoop集群的HDFS目录获取到最新的热门商品列表结果数据。在同步之前先将Redis中之前的热门商品列表数据清空。由于将来要对商品排序,所以保存在Redis中的推荐结果数据类型为Sorted Set类型key部分为一个固定的字符串用以表示这是热门列表结果,member部分为商品编号score部分为商品被访问的总次数,后续排序就是根据商品被访问总次数来进行。
(3)更新用户日志实现
用户日志信息数据存放在HDFS指定的目录下,本模块首先从Hadoop集群的HDFS 目录获取到最新的用户日志信息数据。在同步之前先将Redis中之前的用户日志信息数据清空。在Redis中用户日志数据类型为Sorted Set类型,key部分为用户编号,member部分为商品编号,score部分为一个固定的数字。
5.2.4 web服务端模块实现
web服务端模块的主程序是一个名为server.py的程序,它实现了一个Flask网站服务,提供HTTP的GET和POST请求接口。该模块的功能主要包括推荐结果查询接口的处理逻辑、热门商品查询接口的处理逻辑、用户日志查询接口的处理逻辑、日志添加请求接口的处理逻辑和商品上下架请求接口的处理逻辑。下面详细介绍这5个功能的实现过程。
(1)推荐结果查询接口的实现
当用户向该接口发送Get请求时,后台的处理逻辑是根据该用户的id去访问Redis,并将对应的推荐列表返回给当前用户。
(2)热门商品查询接口的实现
当用户向该接口发送Get请求时,后台的处理逻辑是去访问Redis数据库,获取热门商品列表并将结果返回给用户。
(3)用户日志查询接口的实现当用户向该接口发送Get请求时,后台的处理逻辑是根据该用户的id去访问Redis数据库,并将该用户最近的N条历史行为记录日志返回给用户。
(4)日志添加请求处理接口的实现
系统中每产生一条新的日志时,都会往该接口发送一个Post请求,并且在请求体中封装好了一定的日志格式。该接口收到这个Post请求后,后台的处理逻辑是解析请求体中的日志格式,并重新按照一定格式拼接成一条新的日志数据,然后将这条日志写入本地文件中。而这个本地文件就是将来会被定时上传至Hadoop集群的HDFS上用做大数据计算的输入数据源文件之一。
(5)商品上下架请求处理接口的实现
当系统中有商品上架或者下架操作时,都会往该接口发送一个Post请求,并且在请求体中封装好了一定的格式,比如指明是上架还是下架以及附有商品的id等信息。该接口收到这个Post请求后,后台的处理逻辑是先解析请求体,如果是上架则:根据商品的id去访问公司网站商品属性模块的接口,并得到该商品的所有属性信息,然后结合商品id组合成一条数据,最后调用相关接口将这条数据添加到MySOL的商品属性关联信息表中;如果是下架,则:根据商品id,调用相关接口从MySQL的item tag表中删除这个item对应的tag信息数据。
5.4 本章小结
本章完成了系统具体的实现过程及测试工作。首先对开发环境进行了描述,然后分别介绍了定时任务、离线计算、数据更新和web服务端模块的实现。
