摘要
随着计算机技术的不断发展,新的编程语言层出不穷,Python 正是其中的佼佼者。相比较早期普及的高级语言(Java,C 语言)等,Python 有着更加实用的模块和库,虽然牺牲了底层性,但却更加方便用于开发小型项目。基于 python 的网络爬虫技术,相比于通用的搜索引擎更具有目的性和灵活性,它能根据选定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。本文以人民日报新闻爬取和爬取后的保存及查询为研究,实现
了一个基于 python 的人民日报新闻文章爬取程序。本论文还阐述了一些网络爬虫实现的常见
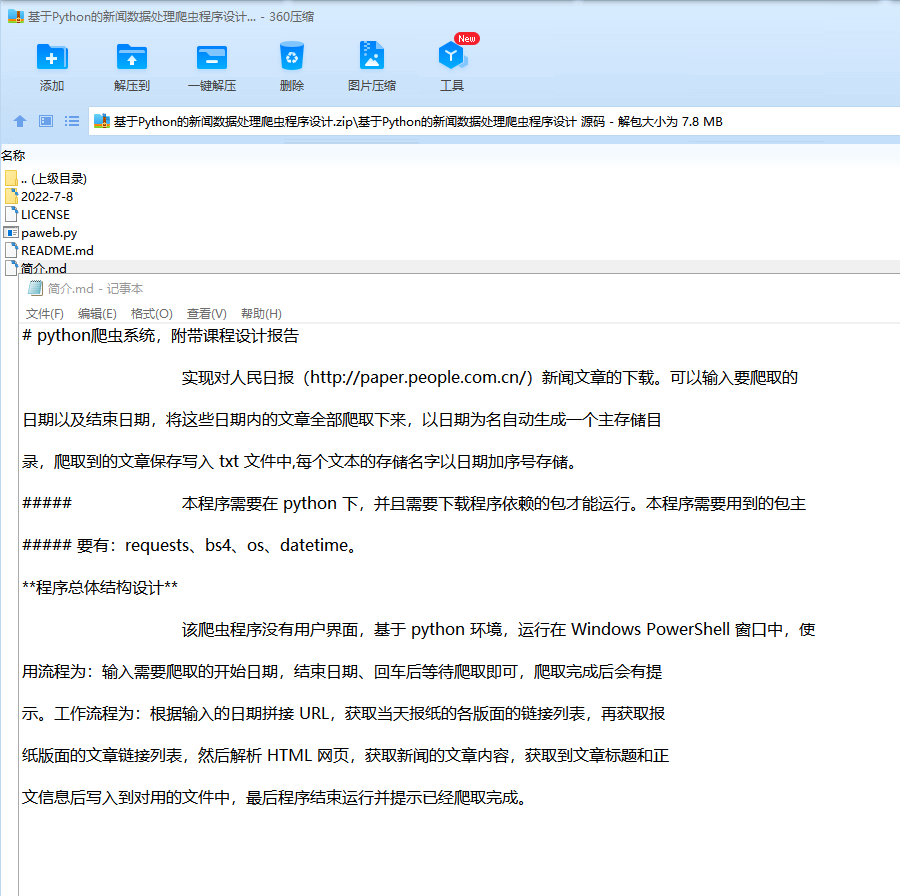
问题,包括常用的 python 的网络请求、如何解决网页的反爬问题、数据保存写入问题等。本程序最终可以实现对人民日报(http://paper.people.com.cn/)新闻文章的下载。可
以输入要爬取的日期以及结束日期,将这些日期内的文章全部爬取下来,以日期为名自动生成一个主存储目录,爬取到的文章保存写入 txt 文件中,每个文本的存储名字以日期加序号存储。
关键词:网络爬虫;Python;;网络请求;人民日报新闻。
目录
目录............................................................................................................................................ 错误!未定义书签。
正文 4
1 绪论 4
2 相关技术介绍 4
2.1 网络爬虫技术 4
2.1.1 网络爬虫技术概述 4
2.1.2 python 的网络请求 4
2.1.3 如何解决网页的反爬问题 5
3 设计目的与要求 5
3.1 程序设计的目的与要求 5
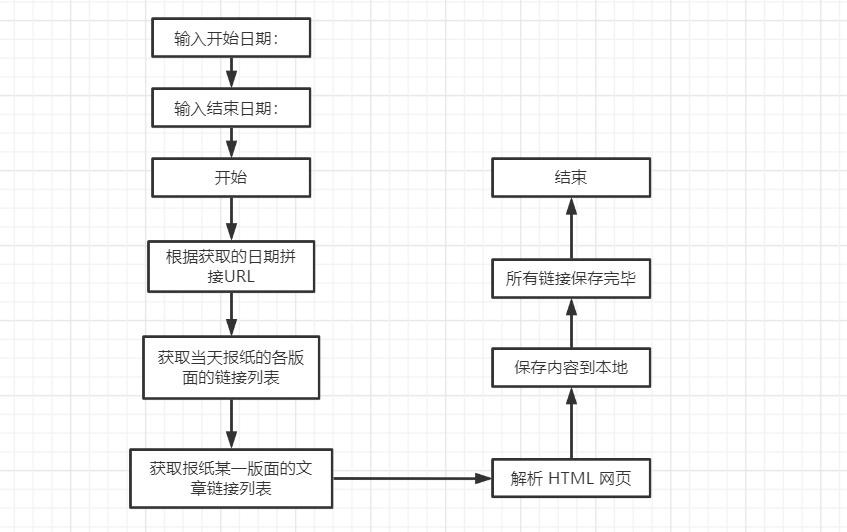
4 总体设计 5
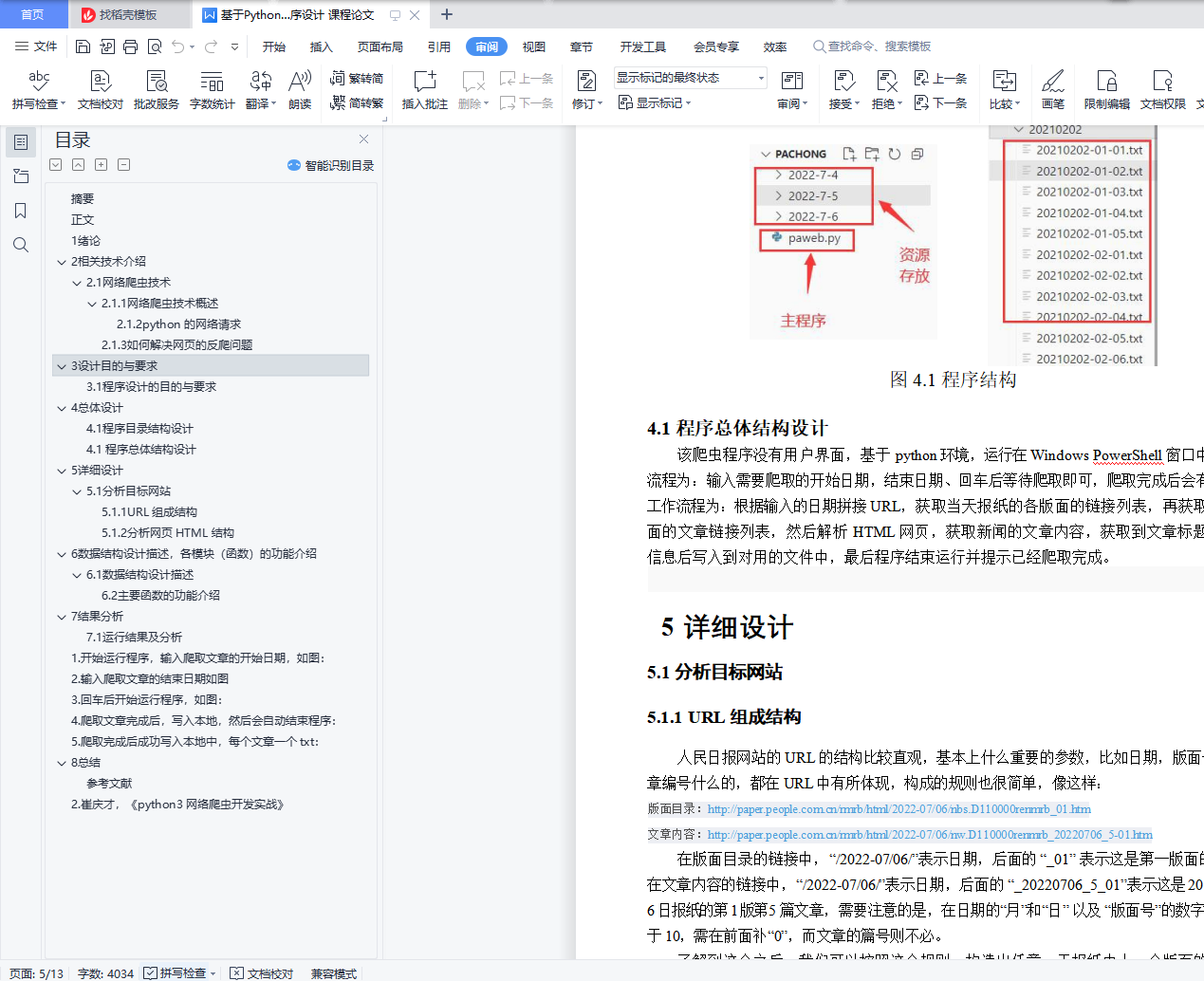
4.1 程序目录结构设计 5
5 详细设计 6
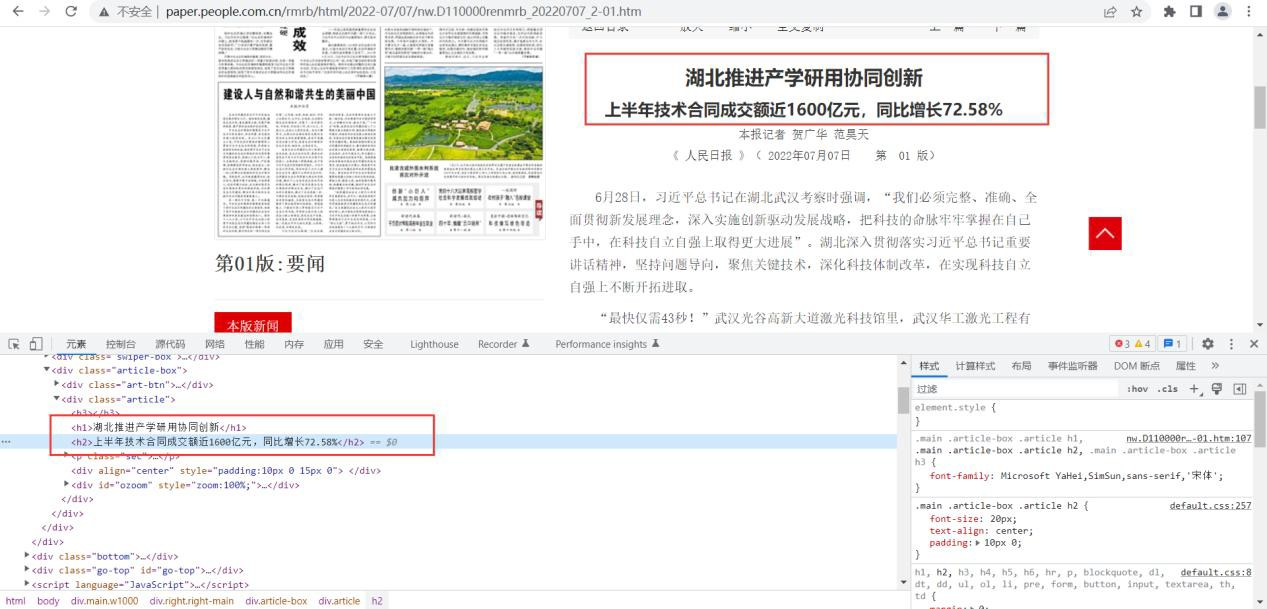
5.1 分析目标网站 6
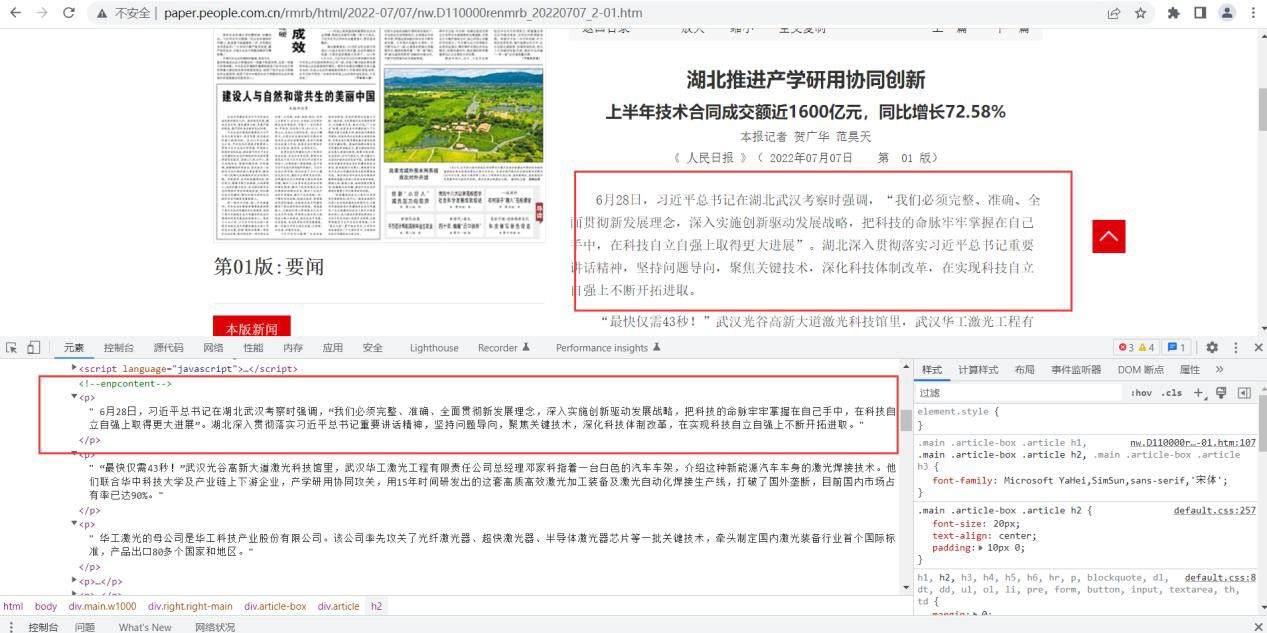
5.1.1 URL 组成结构 6
5.1.2 分析网页 HTML 结构 7
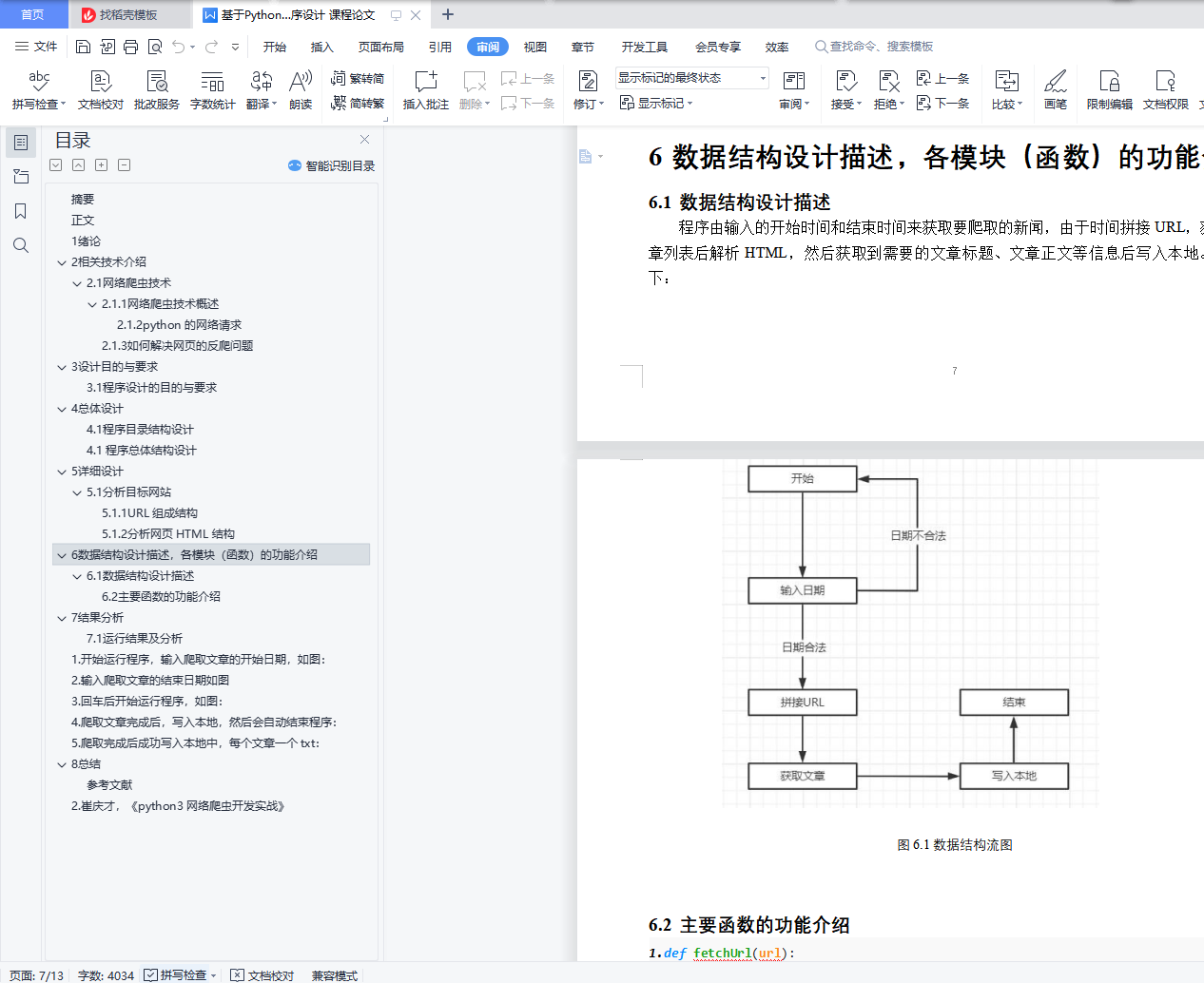
6 数据结构设计描述,各模块(函数)的功能介绍 8
6.1 数据结构设计描述 8
6.2 主要函数的功能介绍 9
7 结果分析 11
7.1 运行结果及分析 11
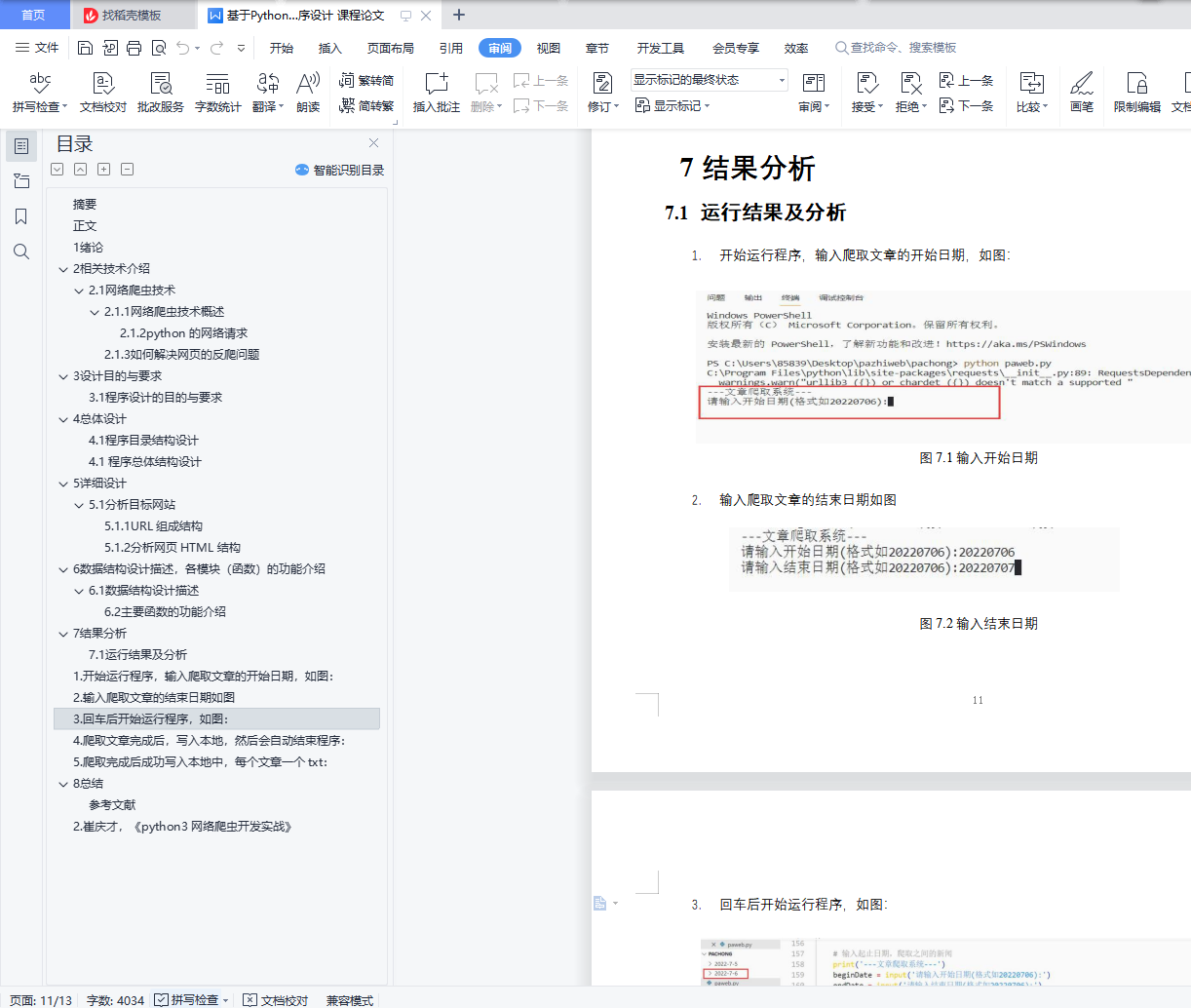
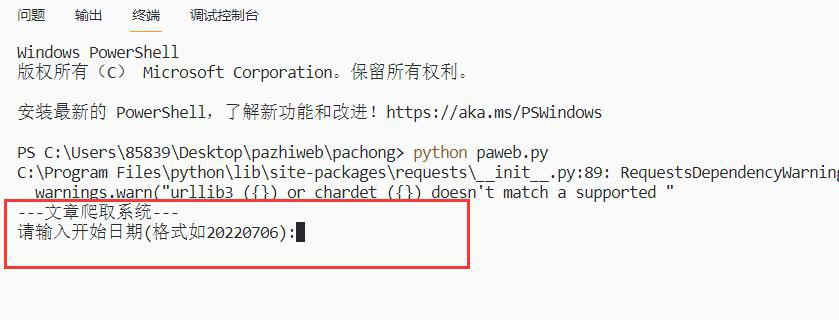
1. 开始运行程序,输入爬取文章的开始日期,如图: 11
2. 输入爬取文章的结束日期如图 11
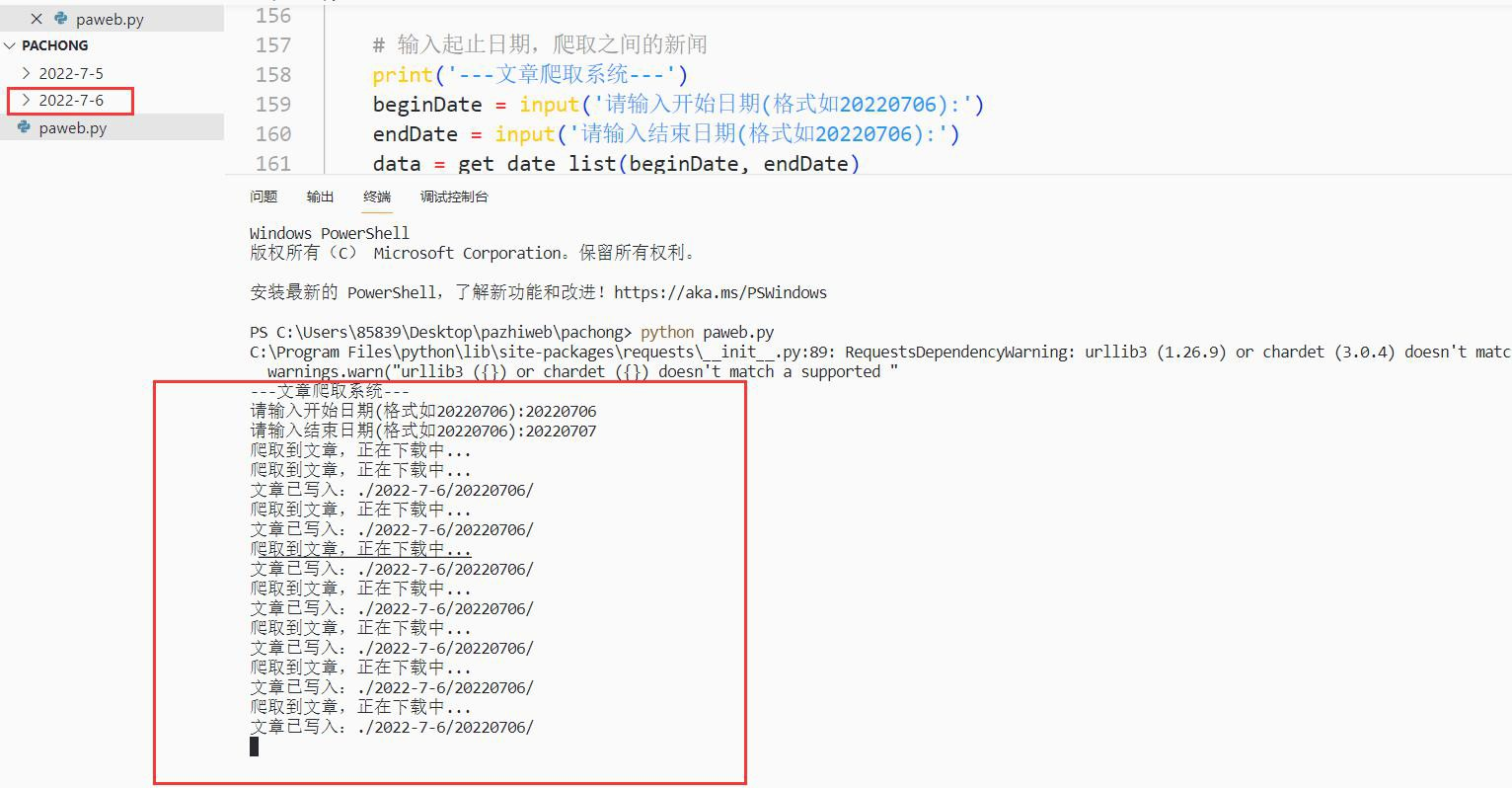
3. 回车后开始运行程序,如图: 12
4. 爬取文章完成后,写入本地,然后会自动结束程序: 12
5. 爬取完成后成功写入本地中,每个文章一个 txt: 13
8 总结 14
参考文献 14