����������ٲ�ȡ��Ϊ�Զ�������������в��ԣ�����һ����֤���㷨���Խ����ȷ�Ϳ��ԡ��������ַ�������Ҫ���㷨��������������ʵ����в��ԣ�ȷ�ԡ�ִ��ʱ�估�����˵�Ӱ��,��������㷨Ӧ�õ��ĵ�������ȥ��
�������� Java����ʵ�ֵĽڵ�ṹ
Class vexNode
{
int type;//��ʾ�ڵ����ͣ�����ԭʼ�㡢�����㡢δ������Ч�㼰��������Ч��
Int simNum;//��ʾ�ڵ���������ʵ����ı��
ArrayList<integer>adjold//��ʾ�ڵ����ڽӵ�ԭʼ�ڵ�ļ���
ArrayList<integer>contain//��ʾ�ڵ���������ԭʼ�ڵ�ļ���
Map<integer,Double>probability//��ʾ�ڽӽڵ�ߵĸ���
}
4.1�㷨��ȷ��
Ϊ����֤��ȷ�ԣ���������������ͬ�������ݴ������㷨���жԱȣ�����DRBB�㷨�뽫���ĵ�ʶ����������[11]���������5������ʶ���㷨��ͬʱ��ȷ�ʣ�Precision,P�����ٻ��ʣ�Recall,R����F1��ȷ�����ٻ��ʵ����У���Ϊ�Աȱ������ף�12���е����ݼ���ʶ������ͼ6��ʾ��
ͼ6 �㷨ʶ�����Աȣ����ݼ���СΪ2616��
������ͼͼ7��ʾ���ڽ����ݷֱ����������㷨���д�����ÿ���㷨������õ��Ľ�����жԱȣ�����ʮ�����ԵĿ���DRBB�㷨�ó��Ľ���ľ�ȷ�Ը�����������㷨���ɼ�DRBB�㷨��ʶ��������ƽ��ȷ�ʸ��ڶԱȵ�5���㷨���ٻ��ʽ����������㷨��һ�㣬��F1�������Ƹ������ԡ���Щ���ݶ�����֤����DRBB�㷨�������㷨�����ȶ���
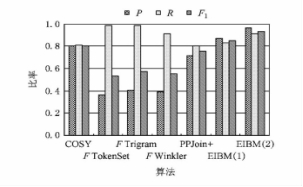
ͼ7���㷨��ȷ�ȶԱȽ��
4.2���㷨��ִ��ʱ��
�ڼ������㷨��ȷ�ʺ����ڴ��㷨��ִ��ʱ�䷽�����ּ������Ժ�������ʱDRBB�㷨��ִ��Ч�ʡ��ְ������²���ִ�и��㷨����ȡ����ʵ�鷽ʽ����һ�����ֽ�������Map-Reduce��ֱܷ�Map��Reduce����52�Ρ��ú���ô������Զ���ȡ���ݵķ�ʽ��ȡ��0.98GB�����ݣ��ڶ����Dz����˹��ֶ����������������������������ԼΪ1.01G������ͬʱÿ�����ݶ�����10������ֵ������ÿ�����Զ���Ȩ��ֵΪ0.1��Ȩ�ء����ۼ���1���ӱ�1�еĽ�����Կ������ڴ����������ϴ�����ʱ��DRBB�㷨����ִ��ʱ��̣��㷨��Ч���൱������
��1��DRBB�㷨ִ��Ч��
|
�ģ����ӣ��
|
�ӣ����/��
|
�ռ�/�ǣ�
|
�ң������硡�ԣ����/��
|
|
�գң�
|
18789004
|
0.98
|
1762
|
|
�������������
|
6836953
|
1.01
|
2833
|
4.3 �����˵�Ӱ��
���ڿ�ʼ�����Զ���IJ����˶Ը��㷨ִ�й����е�Ӱ�죬���½������������������ֽ�����֤�����ݼ��ϴ�С���˵Ĵ�С�͡�Map-Reduceִ��ʱ�����������������
4.3.1 ���ݼ��ϴ�С
�Ȳ���һ�����ݼ��϶��㷨ִ����ɵ�ʱ���Ӱ�졣ѡȡ�˹�������ɵ����ݽ������飬�ֱ����ݼ��ϵ����ݼ���Сѡȡ��10MB��20MB��50MB��100MB��200MB�����Ժ�Ľ����ͼ8��
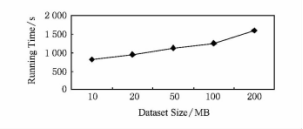
ͼ8 �㷨ʱ������ݼ���С��ϵ
�ɴ�ͼ���Կ�����DRBB�㷨��������ʱ�����ݼ�����Խ���㷨ִ�����ʱ��Խ�̣��෴�����������С�����ʱ�㷨ִ��ʱ��ȴ�ϳ���û���������ӳ����㷨�����ܡ�����ʮ��ֱ�۵ı�ʾ�˸��㷨�ڴ�����������ʱ�߱�ʮ��������ִ��Ч�ʡ�
4.3.2 �����˴�С���㷨��ȷ�ȵ�Ӱ��
DRBB�㷨��ִ�й����л��ܵ������˵�Ӱ�죬��ô�ڦ˴�С��ͬʱ���㷨ִ�еĽ����ȷ����������Ӱ������Ҫ����ģ����ڻ�ȡ���ݴ�СΪ5KB�����ݼ���ʵ�������Ľ����ͼ9��ʾ���ɴ�ͼ���Կ���������Խ��ʱ���㷨ִ�к�Ľ��ȷ��Խ�ߣ���Ϊ��Խ��ʱ����������ʵ�廮�ֵ��Ǹ����������ڻ���ʱ����������ֵ�����ƶȸ��ߵ����ݻ��ֵ�һ�𣬶��෴���ƶȽϵ͵�����Ӳ��ᱻ��Ϊһ�ࡣ����˼�嵱ÿ�������е������������ƶ�����ˣ���Ӧ��ȷ����Ȼ������ˣ����ͬʱ�ٻ��ʽ���Ȼ����ȷ�ȵ���߶����ͣ�����F1�����ʵ����û�����Ŧ˵ı仯�����ֽϴ������ֵ�ʮ���ȶ���
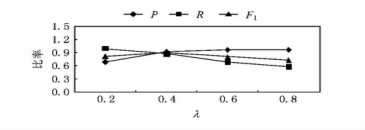
ͼ9 ���ֲ����˴�С���㷨��ȷ�Ե�Ӱ��
4.3.3 Map-Reduce��������������
��ν������㷨ִ��ʱMap-Reduce�������IJ�ͬ���������ж��㷨�����Ӱ��̶ȣ�ÿһ��Map-Reduce���Ǵ��������ڴ���һ�����̣��ʶ�Map-Reduce���������Ա�ʾ���̵��������˴β��Դ��㷨ִ��ʱMap-Reduce�ĸ������֣���֤�㷨��ִ��Ч�ʣ���ͬ����ѡȡ������ͬ��С����������10MB��500MB��
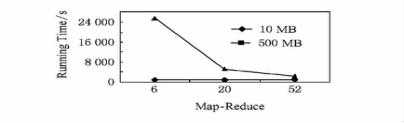
ͼ10��Map-Reduce�������㷨ִ�й����е�Ӱ��
��ͼ10���Կ�����Map-reduce�Ľ��������㷨��ִ��ʱ��Ӱ���Ƿ���������ģ�������������ʱӰ���С���෴���������ϴ�ʱӰ��ϴ��������Ƚϴ�ʱ��������Խ���㷨ִ������ʱ��Խ�̣�Ч��Խ�ߡ�
4.4��ʵ��С��
���������ʵ�飬���Կ��������㷨�������ܵ����ݼ��ϴ�С���˵Ĵ�С�͡�Map-Reduceִ��ʱ�����������������Ӱ���Ĵ����ۺ��������DRBB�㷨����֤����������������ϴ�����ʱ���㷨���ܳ�ַ��������ܡ�
4.5 ����ʶ���㷨���ĵ������е�Ӧ��
������ʵ���֪DRBB����Ժ�������ʱ�ܹ�ʮ��ȷ��Ч�Ķ����ݽ���ʶ�𣬴����������ظ�����������������ÿ�춼�����մ�������Ϣ�������������Ҫ��ѯ������ʱ����δ���֮�������ĵ����ҵ��Լ���Ҫ����һ���֣���һ�����⡣��DRBB�㷨���ÿ���Ӧ�õ��ĵ������������ٸ����ӣ���������������������Ƕ�Զ��How far is it from Earth to Mars?��,���ʱ��Ϊ�˷�������������롰from Earth to Mars������ѯ�������ʾ���ຬ����Щ�ؼ��ֵ��ĵ�������һ�����Լ���Ҫ��ȴ��ֱ���ҵ�����Ҫ��������ʱ��;���һ��һ��������������DRBB�㷨���ڹ���ĵ����������н��г������࣬Ȼ��ͨ���㷨������ʶ����һ�������ν��ж���Map-Reduce����ֵ���㡢ͼ������Զ������Ͽ��и��ݼ��������Ƹ���ɸѡ����ѵĴ𰸼�����������ʾ���ͻ���ͨ���㷨��������ʾ���û����ĵ���������ͣ����û�����ʮ��Ѹ�ٵ��ҵ�����Ҫ���ĵ����ݡ�
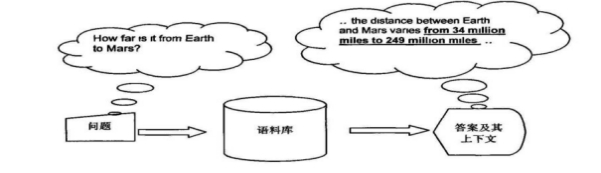
ͼ11�����ĵ�������DRBB�������
���û����룺��from Earth to Mars������DRBB�㷨ɸѡ����ĵ�����ʾ����һ�仰����...the distance between Earth and Mars varies from 34 million miles to 249million miles��������from 34 million miles to 249million miles���Ƿ������û���ȷ�Ĵ𰸡�
5 ����
�ڴ�����������ʱ������Ҫ����칹���ݺʹ����ǽṹ�����ݣ������ڱ�ʾ��Ҳ���ڶ������������ݶ������Բ�ͬ������Դ���ʶ�����������������Ҫԭ�������ݵ���������ݼ����Բ�ͬ���ݵ�Դ�����������ƪ��������Ĵ����ݴ���������ʶ���㷨DRBB���ȳ���������ȡ�Ķ��������ֵ����һ���������������ڲ���ʱ�������˱���ʱ�Ĺ���������Ч�����������ʶ������ȷ�ȡ����������һ������ķ���������ֵ������Ȩֵ��ʹ�û���������ʱ����Ч�ʣ�ͬʱ����һά����任�ɶ�ά���ݼ��ϣ�Ȼ������ͼ����ķ�ʽ�����������ƶԣ�ʮ����Ч����ߵ��㷨�ľ�ȷ�ȡ������ʵ����֤�����д��Զ�¼�����ݺ��˹����������������������в��ԣ������֤��DRBB�㷨�Ŀ����ԣ��������Ժ���Ҫ�����������ݽ�������ʶ��ʱ�����Ÿ��㷨���������ƣ��ػ�õ��㷺�����ã��������ֵ���ڡ�
�� �� �� ��
[1] ����. �߽��Ƽ���[M]. �����ʵ������, 2009:75-78.
[2] ����ϼ,��ҫ��,�����ڵ�. ����Hadoop�ܹ��ķֲ�ʽ����ʹ洢��������Ӧ��[J]. �Ϻ�����ѧԺѧ����2011(01).
[3] �����,���ʷ�,��ΰ. �Ƽ���ƽ̨�������ھ��㷨�о�[J]. ����ũ��ѧԺѧ����2017(01).
[4] ����־,���ķ�. ���������ϵ�����ʶ�����о�[J]. �����ѧ����2011(10).
[5] ����ѧ,�ŭZ,��־��. MapReduce���б�̼ܹ�ģ���о�[J]. ����ѧ��������2011(06).
[6] ������,������. ���ڶ�̬��ֵ��Эͬ�����㷨�о�[J]. ����ѧԺѧ��(��Ȼ��ѧ��)��2017(05).
[7] Cohen w w, Richman J. ��ѧϰ��ƥ�伯Ⱥ��γ�����ݼ������ݼ��ɵ�֪ʶ���ֺ������ھ�.New York:ACM, 2002:475-480.
[8] �³�. ���о����㷨��MapReduce�ϵ�ʵ��[D]. �㽭��ѧ��2016.
[9] �ܺ���,��չ˶. һ�ֻ���Hadoopƽ̨�ķֲ�ʽ���ݼ���ϵͳ[J]. ����������2017(4).
[10] Arasu A, ReC, Suciu D. Laege-scale deduplication withconstraints using dedupalog //Proc of the 25th IEEE Int Confon Data Engineering(ICDE:09). Piscataway, NJ:IEEE.
[11] Фѩƽ,�߽���,�ܲ�. ����Map-Reduceģ�͵�BCkmeans���о����㷨[J]. ���Ӽ���, 2016(05).
[12] K pcke H, Thor A. Evaluation of entity resolution approaches on real-world match problems.Proceeding of the VLDB Endowment. 2014, 3(1/2):484-493.
�� л
���α�ҵ��������벻����������ʦ��ָ���Ͱ���������æµ�Ľ�ѧ�����г��ʱ������顢���ҵ����ģ�������˳�������α�ҵ������˹ؼ��Ե����ã��ڴ˽�������ʦ���Գ�ֿ��л��ͳ�ߵľ��⣬�������н̹��ҵ���ʦ�������Ͻ�ϸ�£�����ѭѭ���յĽ̵���һ˿������˼·�������������ϡ�
�һ�Ҫ��л�ҵ�ĸУ�人���﹤��ѧԺ���Լ��ڴ�ѧ�����ѧϰ�������и����ҹ��ĺͰ��������ѡ���ʦ��ͬѧ�ǣ���л����Ϊ������Ľ���������������Ϊ���ǵ�֧�֡������Ͱ������Ҳ��ܳ�ʵ�Ĺ���������Ĵ�ѧ����������ҳɳ������࣬�̻�����רҵ��֪ʶ�����˵ĵ��������Ҹ��ӳ��졣
,


�γ���Ʊ���
����Ŀ���˵���飩
|
�� �̣�
|
|
|
�� Ŀ��
|
|
|
ѧ Ժ��
|
|
|
רҵ�༶��
|
|
|
���С�飺
|
|
|
��Ա������
��������8�ˣ�
|
|
|
ָ����ʦ��
|
|
|
ʱ �䣺
|
|
���С�鼰��Ա�ֹ�����
���С���飺
����Ա����������ֹ�һ������
|
ѧ��
|
����
|
רҵ�س�
|
����Ŀ�е����ã����ɫ��
|
������/�鳤����
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ŀ ¼
ժ��Ҫ II
�ؼ��� II
Abstract III
Key words III
1 ϵͳ������� 1
���ɸ�����Ҫչ��Ϊ���������������⣬��ʽ���£���ͬ����������ʽ�γ���Ʊ����в�Ҫ��
1.1 1
1.2 1
1.2.1 2
1.2.2 3
2 ϵͳ���ܷ�����ģ�鹹�� *
չ���Ķ��������������⣬��ʵ�ʵı������
3 ϵͳ�ļ���� *
չ���Ķ��������������⣬��ʵ�ʵı������
4 ���ݿ��������� *
չ���Ķ��������������⣬��ʵ�ʵı������
5 ��Ҫ����ģ��������ʵ��
5.1 ģ��һ *
5.1.1 ��ǰ�ˣ����������ʵ�� *
5.1.2 ����̨�����������ʵ�� *
5.1.3 �������� *
5.1 ģ��� *
5.2.1 ��ǰ�ˣ����������ʵ�� *
5.2.2 ����̨�����������ʵ�� *
5.2.3 �������� *
6 ϵͳ����ʹ��ע������
6.1 ϵͳ�������߷����� *
6.2 ϵͳʹ��ע������ *
7 ���� *
����� 21
��������������ʽʾ��������������˴�����أ�����ԣ���
���ڴ����ݵ�����ʶ���㷨���ĵ������е�Ӧ��
ժ��Ҫ
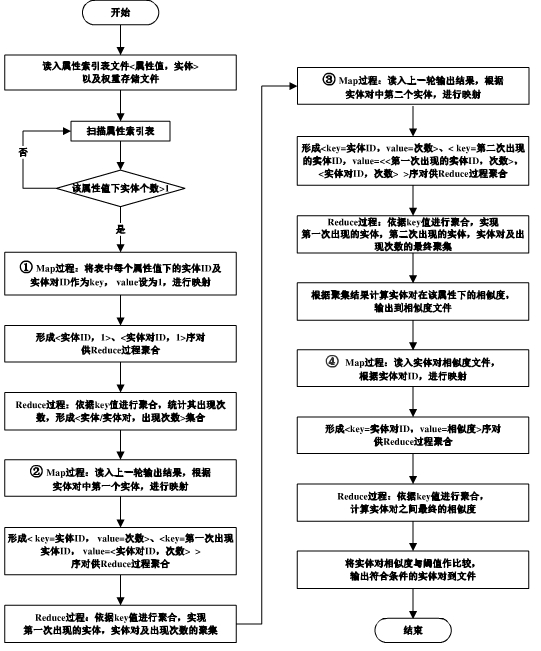
����ʶ����ɸѡ���ݣ������ݽ���ʵʱ���������һ��ؼ�����������Ч������ݼ�������Ϣ����������Ŀ������ʶ��������ڱ�ʾʱ�Ķ����ԣ��Լ�����ӳ�����ݵ��ظ��ԡ����Ŵ�����Ӧ�õ�Խ���㷺�����ڴ����ݵ�����ʶ���Ӧ�˶�������ˣ����ֽλ�������չ�Ļ����ϣ����߸�����һ�����ڴ����ݵ�����ʶ���㷨,���㷨�����������������ݿ��е�����ֵ���бȽϺ�ɸѡ��Ȼ�����þ����㷨�������ݹ����ƥ�䣬����������Hadoopƽ̨�϶���ʵ���ݼ����������ݼ������˱Ƚϣ�����ʵ������֤�㷨�Ŀ���������Ч�ԡ�������㷨Ӧ�õ��ĵ������У�����Ҫ����ij����Ϣʱ��ֻ������ij���ؼ��ʣ����ø��㷨�������Զ�ƥ�䡣
�ؼ���
�����ݣ�����ʶ���㷨���ĵ�������Ӧ��
The Application of Data Recognition Algorithm Based on Big Data in Document Search
Abstract
Data recognition is a key technique for screening data��real-time monitoring and identification data which can effectively improve the quality of data and feedback information,Its purpose is to identify the diversity of data in representation and the repeatability of object mapping data.with big data applications more widely, the data recognition based on big data then arises at the historic moment. Therefore, based on the current development of the Internet, a data recognition algorithm based on big data (map-reduce) is presented. The algorithm first compares and filters the attribute values of the objects in the database, and then uses the clustering algorithm to classify and match the data. After the output results were compared between the real data set and the artificial data set on the Hadoop platform, the feasibility and effectiveness of the algorithm were verified by experimental results.Finally, the algorithm is applied to document search. When you need to search for information, you only need to search for a keyword and use the characteristics of the algorithm to automatically match.
.Key words
Data identification��Big data��hadoop��Map-Reduce
1 ǰ��
1) ĿǰΪֹ���ܹ��������ڴ���������������������ݵ�������������㷨����֮���٣�����ƪ���������ܽ��������⣬�ڻ���Hadoopƽ̨�²���Map-Reduce���ʵ������ʶ��
2) ʵ���˴����������ݵ�ʵʱ���˳����㷨�ͶԹ��˽�����м�����ֵ���㷨�����߽��ʹ���ݽ��У�����ȷ���������������ضԽ����Ӱ�졣
3) ���㷨�ڵó�ʶ���������У����������ļ�¼�������˸��ʼ��㣬������ÿ����¼���ظ������ԣ����ӷ��������ݵĶ��δ�����
4���ڱ�ƪ�������ͨ������ʵ�飬�����㷨Ӧ�õ��ĵ������龰�У�ʵ���ں���������ǰ���ܹ�����ֻ������ؼ��֣��Զ�ƥ�����ѵ���Ϣ��
2 ��ع����ͱ���
2.1 ��ع���
��������ʶ�������о������ڼ�����翪չ��ʱ��������������ݵ�������Խ��Խ�Ӵ������һֱ���Խ�������ڵ��о���Ҫ�Ӵ��������������ظ����������֣��������һ�ֿ��������ṩ�ļ����¼���ƶȵĻ������ƶȵĺ����ͻ��ھ���ֵĺ�����ǰ����Ҫͨ���Ա���������֮��Ĺ����̶ȺͱȽ���ֵ�����ж����������Ƿ�һ�������ͬʱѡȡ�Զ��������ת���ַ�������ʶ������������ʶ��ȣ�����������ƺ����е��Զ�ִ�з���ͨ������ѧϰ��ȡһ�����ݳأ����ݳؿ���ȷ�ضԱȼ�¼�ĸ�������ֵ������ֵ��ӽ��Ķ����¼��Ϊһ���������ھ���ķ����Ǹ����Զ���ı����жϼ�¼�Ƿ�ɹ�Ϊһ�������ࡣ�������ף�1�������һ�ֿ����������ܻ����ܹ�Ӱ�졢�ܹ���������ʶ���������Deduplog�����ף�2�����ò�ͬ����Լ������ѡ��ʶ�����ݵĹ���ͬʱ������������(EM)�㷨[3]�ͻ��ڳ��ɳڵ����ı�ǩ�����㷨[4]������ѧϰ���������������ȷ�ȣ�����ӳ���е������ͺ�������������ͬһ�����������ݿ�����ӳ��IJ�ͬ��¼�ı���
�ֽδ��ڶ��ֿ���ʶ��������Ч�Ե��㷨�����㷨ԭ�����ֻ����������������ʱ�����ݶ����ܻ��ڴ���������µ�����ʶ���㷨����û�У�ֻ�м����������������ԣ���������ֻ�ܶ��ַ��������ϵԪ����в�����ͬʱ�Դ���������µ��칹���ݡ��ǽṹ�����ݵ�ʶ����Ҳʮ��ȱ�������ο���Щ�㷨����֤ʶ����Ľ����������
2��2��Haddoopƽ̨
3 ����Map-Reduce������ʶ���㷨
3.1�����ݵij��������㷨
������֪����ʵ�����е�ÿһ�����壬����Ϣ�����������ݱ�ʾʱ���������ֲ�ͬ��¼����ͬһ������Щ��¼�����Զ�ӵ����������֮�����ʶ���ѡ���¼������ֵΪ�жϱ�����ÿ�����������ֵ���쵹������������ÿһ�����Ƶļ�¼���г����Ļ��֣�����һ����ʮ����Ч�ļ��������ݵ�����ͽ������ݱȽ�����Ĵ���[10]��Ϊ�˸���ֱ�۵ı����˹��̣���������˵����ʱ���ü�¼����������ʾ�����һ������ֵʮ�����Ƶļ�¼�������ƶ�����L�У��ѡ��š�����ΪL�е�һ�����ݶ�������һ���Ϳ�����ID����ʾ�������Ȼ���L������Ԫ�ش���һ�����ϣ������е�Ԫ�ص�����ֵ���ñ�dz������輯����ΪP��������ΪPi���ڴ˻������ٴι���һ����ΪPLi�ĵ������������ʶ����������е�����ֵPij��pi�����ڶ��ϡ���PE�����������֣�ÿһ�λ��ֶ�Ҫ����һ��Map-Reduce���̡�
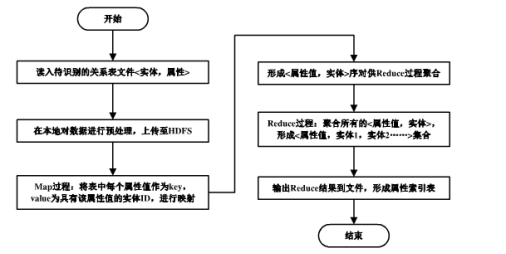
ͼ1 ���������㷨����ͼ
����1��BuildSE
�� Map����
���룺<key���к�ID��value������ֵ>
�����<key��Pij��value��Li>
�� Reduce����
�����<Pi1��<Li1��Li2��>>
<Pi2��<Li1��Li2��>>��.
�������������㷨���ظ����������ݹ�Ϊһ�������࣬���ҽ���Щ����ֵ�Ե�������������ʽ�棬����Щ����ֵ������һ����������ʾ�Ķ�������һ���������������Ƕ�����һ�����������DZ�ʵ�������ݵij������ࡣ��һ���������ʶ�������˷dz��õ��̵棬ʹ�ý�������ʶ��ʱ����Ҫ����Ķ�ÿһ�����Խ���ʶ��ֻ���ڵ������������ҵ���Ӧ�Ĵ���ͬһ���Ե����ݣ������˹�������
3��2 ���ݵ����ƶ�ʶ��
����ʶ���㷨��Ҫ���Դ��·�Ϊ3���Σ����������ɼ���������ֵ�ȽϾ����Լ�����ʶ���������������ɼ���������ֵ�ȽϾ���2���ο��Բ��ò���Hadoop�Ķ��̲߳��м��㷽ʽ��ֻ�赥�̵߳ļ�������ɣ�������ʶ�������Map-Reduce��ܵIJ���������ݴ����ص�ʵ�֡�
3.2.1 ���������ɼ���
��������Ե������Ǻ������ݣ���Щ���ݲ�������Ƿǽṹ�����ݶ��������ڲ�ͬ������Դ���ʶ�Ҫ��ȡ����ֵ�����������ݿ��г��һ����������Ϊ������ȡ��ֵ����ȡ�������Զ�������һ����������һ��ʮ���Ӵ��Ԫ�ؼ����г�ȡһ����Ԫ����Ϊ���������輯������N��Ԫ�أ�����ȡ����Ϊk�����ڹ涨k��Ԫ���д��ڶ������ֵʮ�ֽӽ������ݣ������Ϊm��������Ҫ���������ݲ��ϵ�ʵʱ����������ʮ���Ӵ��ڽ��г���ʱ������һ���������ݽ����ڴ��У���ǰ��˵��Ҫ��֤��ȡ��Ԫ������Ҫ����m������ֵ���Ƶ����ݣ���˱����ȡһ�ֿ�������ʵʱ�������Զ�ʶ��������Ч�Եij����㷨������ȡ��ΪDESampling�����㷨��DESampling�㷨��ԭ�����ȹ���һ���ɹ������ij���������SamplingPool������һ�����ݽ�������������У����Ҳ���ʵʱ���£�����һ�����������а���Ҫ���ȡ������
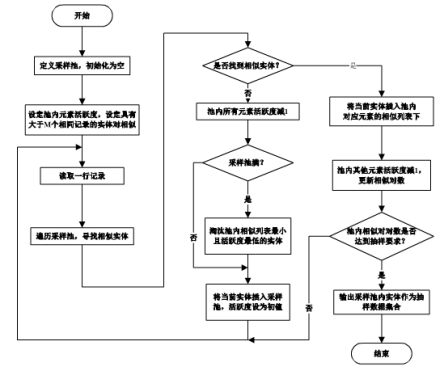
ͼ2 �����㷨����ͼ
���㷨α���룺
�㷨1��DESampling ���룺��ϵ��E�����������S
�� sim Pair=0;
�� for each entity Ei��E do for��each entity Ei��E do
�� for each entity S,in SamplingPool do
�� if similarity(Ei,Sj)==true then
�� SamplingPool[Sj].setID.insert(Ei);
�� simPair +=SaPair+=SamplingPool[Sj].size;
�� for each entity Ck,inSamlingPool do
�� SamplingPool[Ck].jmp--;
�� end for;
�� go to��;
end if
end for
If SamplingPool.size==MAXSIZE then
D=min(SamplingPool.jmp);
SamplingPool.remove(D);
end if
for each entity Ft in SamplingPool do��
SamplingPool[Ft].jmp--;
End for
SamplingPool.insert(Ei,null,MAXJMP);
if simPair<MAXPAIRT then
goto��;
Else
Break;
Endif
Endfor
Output SamplingPool;
�������㷨���Կ�������һ���ǹ�����һ������������SamplingPool,������е�Ԫ�ض���Ϊ���䱸������ǣ�����һ�����ڱ�ʾ���������ļ��ϣ���һ�����˱�ʾ���ڼ����г��ֵĴ���setID�����һ���ڳ�������һ��ȫ�ֱ���simpair��¼�������ƶȽϸߵ����ݶ�jmp������ֵΪ0�������Щ�������Ƚ����е�Ԫ�ؽ��б������ҵ���������ֵ���Ƶ����ݣ�Ȼ���������뵽һ�����ݼ����У�Ȼ����³��еļ�¼��Ȼ��������ڳ��е�Ԫ�ص�jmp�Լ�1,���������㷨ִ�в�������ִ�С��෴������û���ҵ�����ֵ���Ƶ����ݶԣ������һ�����ݲ������е����ݣ��������Dz��������ݴ洢���ﵽ�����ޣ�����������Ծ�ȵ͵�Ԫ�أ�Ȼ�����������µ����ݣ�����Щ���Ƹ����ٵ�Ԫ����������ͬʱ������ԭ������Ԫ�ص�jmp�Լ���һ��������Ǵ��Ҫ����ִ�������в��裬��Ȼ�ص��㷨�ڶ�������ִ�У������������ͬʱ�����㷨��ʱ�临�Ӷ�ΪO(n),�ռ临�Ӷ�ΪO(m n)��
3.2.2 ������ֵ�ȽϾ����
Ҫ���жϳ�ȡ������������ֵ�Ƿ����ƣ����ԱȽ�����ֵ����Ҫ��ó��������ݵ���ֵ�����ĸ�����һ�ּ�����ֵ�ķ����������ݵ����ƶȻ���Ϊǿ���ƣ�HL����������(LL)��Ȼ�����������Ľ���������ظ��̶ȣ������������ϵ�����Բ����ʾ�����࣬Բ������������е����ݼ��ϣ�Ȼ��������Ը�������Բ�ĵ���С������������������ֵTHES��
����1��������������������һ����V������һ��Բ���Խ����������������Բ����ס��ͬʱ����ֻ��һ��������Բ�İ뾶��С������ԲCΪ����V�����е�İ뾶��С��Բ�����ԲCΪ�㼯V����С��������
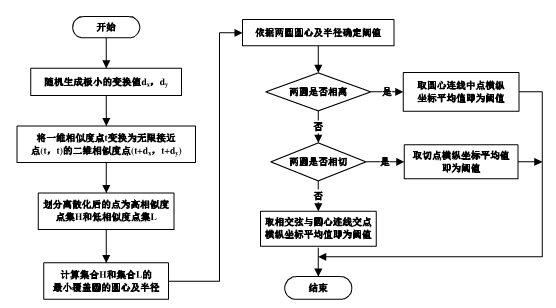
ͼ3 ��ֵ��������ͼ
�ɴ˿�֪���������һ���㷨TMC��
�㷨2��TMC
���룺HL��LL�������THES
�� for each value t in HL do
�� P.x=t+rand();
�� P.y=t+rand();
�� H.insert(P);
�� Endfor
�� For each value s in LL do
�� Q.x=s+rand();
�� Q.y=s+rand();
�� L.insert(Q);
�� Endfor
<rH,pH>=computer_mcc(H);
<rL,PL>=computer_mcc(L);
If |PH-PL|>rH+rL then
R.x=PH.x+PL.y;
R.y=PH.y+PL.y;
THRES=(R.x+R.y)/2
Else
R=computer_inj(PH,RH,PL,rL);
THRES=(R.x+R.y)/2;
Endif
Endif
Return THRES;
Endif
Return THRES;��
���㷨ǰ5���У�Ϊ���ǽ�һά�ĵ�������������ֵ��ʵ�̶ȵĵ���Ϊ��ά�ĵ㣬ͬʱ�����ڴ˻�����Ԥ�����ɢ�㣬Ȼ�����������ֱ�鵽HL��LL���ں���IJ��������Compute_mcc�������THRES��Ȼ���������Բ��λ�÷ֱ�������յ���ֵ���ཻ��THRES=�ཻ��������Բ�����ཻ�ĵ�����꣨x,y����Ȼ��x��y��ӵĺͳ���2�����룺����Բ��Բ�ĵ����ߵ��е����꣨x,y������������ȡ�е�����꣨x,y��,ͬ�������x��y�ĺ͵Ķ���֮һ����ֵ��Ϊ�������ֵ��������㷨��ʱ�临�Ӷ�ΪO(n)��
3.2.3 ����ʶ���
����ʵӦ�õ�ʱ���������ڱ�ʾ���ݵ�����ֵ�Ķ����ԣ�������ʶ������˷dz���IJ���֮����Ϊ�˽��������⣬�뵽��һ������ķ��������ʶ������ʱ���ֵ�������ʵ�����ƥ������⡣�Ǿ���Ϊÿ�����ݵIJ�ͬ��������һ��Ȩ��Wi��Ȼ����ƥ��ʱ�����ڶ�����ֱ�ӽ��в���������ֻ������趨���Ǹ�Ȩ��ֵ�����жϣ�ʮ����Ч�������ʶ��ȷ�ȣ���������Զ����Զ�ʶ����̵ĸ��š��������Щ��������ڳ�������ֵ���������ɸѡ�����ݽ���һ��ȫ��ı�����Ȼ���ٸ���Ȩ��ֵ����ֵ֮��ĶԱ�������ݵ����ƶȡ�
ͼ4 ����ʶ������ͼ
����2��EntityCount
���룺����������SE����������ݳ��ֵ�Ƶ�ʺ����ƶԵ�Ƶ�ʡ�
�� map����
���룺<key=Aik,value=<Ei1,Ei2>>
��������SE�еĵ����ݺ����ݶ���Ϊkey,value=1,����ӳ�䡣
�����<key=Ei,value=1>,��,<key=Ei,Ej,value=1>��.
��Reduce����
���룺<key=Ei/<Ei,Ej>,value=1>
�������������key���оۺϲ�����Ȼ���¼���ݳ��ֵ�Ƶ�ʺ����ƶԵ�Ƶ�ʡ�
�����<key=Ei,value=Ti>,��,
<key=Ei+Ej,value=Tij>��.
��ɵ�һ�����̺���Ҫ�ڽ��������ظ������IJ��裬������Ľ�����оۼ���
����3��EntityGather1
���룺EntityCount��������������ݼ������ƶԵ�Ƶ�Ρ�
����������ݼ������ݶԳ���Ƶ�Ρ�
�� map����
���룺<key=Ei/<Ej>,value=Ti/Tij>
��������Ei��Ϊkey��value=<<Ei,Ej>,Tij>��Ȼ��ӳ�䣬���ⵥ�������ݺ�Ƶ��ֱ�������
�����<key=Ei,value=Ti>,��,
<key=Ei,value=<<Ei,Ej>,Tij>>��.
�� Reduce����
���룺<key=Ei,value=<<Ei,Ej>,Tij>>/Tj>
��������key���࣬�ѾۺϺ�Ľ����������������ݽ����������ΪEi��������Ϊ�������
���������ۼ������ֺ������
�����<key=Ei,value=Ti>,��,
<key=Ei,value=<Ti,<<Ei,Ej>,Tij>>>��.
����4��EntityGather2
���룺�����������ݼ������ݶԶԳ���Ƶ�Ρ�
����������г��ֵĵڶ������ݼ������ݶԵ�Ƶ�Ρ�
�� Map����
���룺<key=Ei,value=Ti/<Ti,<<Ei,Ej>,Tij>>>��
������key=�������еĵ�2�����ݣ�value=Ei��Ƶ�κ�������Ei+Ej��Ƶ�Σ�����ӳ�䣬������ֱ�������
�����<key=Ei,value=Ti>,��,
<key=Ej,value=<<Ei,Ej>,<<Ei,Ej>,Tij>>��.
��Reduce����
���룺<key=Ej,value=<<Ei,Ti,<<Ei,Ej>,Tij>>
����������key���ۺϣ���������������ݶ��ж���ڶ��������Ƿ�ΪEj,���������������Ƶ�Σ�Ȼ�������ֲ������
<key=<<Ej,Tj>,<Ei,Ti>,value=<<Ei,Ej>,Tij>>����
���������������ڴ˻����Ͻ�������ͬ���IJ������ó�ȷ�Ľ�����˽�����Ǹö��������µ���������ֵ�Ƶ�Ρ�����ij������Am����������<Ei��Ej>�����ƶ�Sm����Ϊ��
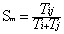 ʽ��1-1��
ʽ��1-1��
�����������Ե�����ƽ�����Ƴ̶�similarity(Ei,Ej)ʱ����Ҫ��ÿ�����ݵ����Ե�ֵ������Ȩƽ��������Ϊ��
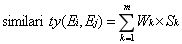 ʽ��1-2��
ʽ��1-2��
ͨ����Щ���㣬�ó��Ľ���ٽ���һ��Map-Reduce�Ϳ��Եõ����յĽ�����ý������������������ƶȡ�
����5��ComputeSimilarity
���룺THRES,Ȩֵ��������
<key=<<Ej,Tj>,<Ei,Ti>>,value=<<Ei,Ej>,Tij>>;
���������ֵ���Ƶ����������̶ȡ�
�� map����
���룺<Key=�к�,value=key>;
������key=Ei+Ej,value=Sm,ӳ�䡣
�����<key=<Ei,Ej>,value=Sm>,��,
<key=<Ei,Ej>,value=Sn>��.
��Reduce����
���룺<key=<Ei,Ej>,value=Sm>,��,
����������key�µ�<Ei,Ej>����������Ƴ̶ȣ�Ȼ�������������֮ǰ����ó�����ֵ�Ľ����
�����<key=<Ei,Ej>,value=similarity(Ei,Ej)>����
����������Ĵ���֮��ͨ������һ�����ó������ഴ���Ķ���������Ե�����������Ȼ���ڴ˻������ṩ��һ��EntitySim��ܡ��Ա�֤������������������չ��
���룺SE������Ȩ�غ���ֵ��
������������ƶԼ����ļ���
�� for each Attribute Ai in A do
�� set Wi;
�� EntityCount(Ai);
�� EntityGather 1(Ai);
�� EntityGather 2(Ai);
�� endfor
�� ComputeSimilarity();
�ڢ١����У�ÿ�����ݵIJ�ͬ��������һ��Ȩ�أ�Ȼ����ƥ��ʱ�����ڶ�����ֱ�ӽ��в�����Ȼ���ٽ������� Map-Reduce��¼�½���е��������Ƶ�Σ������ڴ˻������ڴ˽���һ��Map-Reduce�ó������
3.3������ͼ����Ķ������
ͨ��3.2�εIJ������Կ���������ü��ϵ���ʽ��ʾ���ʶ�����һ�����Խ�����ļ��ϱ�ʾ��ͼ������ʽ��Ϊ�˸�����һ���㷨��GraphDivision�����Ҹ����˱Ƚ���ϸ���������ڸ��㷨����N(V)Ϊ����V�����ڽ��ļ���,ͬʱV��N(V)��
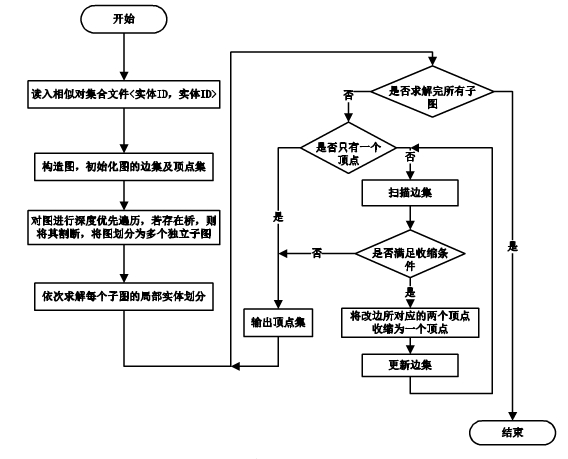
ͼ5 ͼ������㷨����ͼ
�㷨4��GraphDivision
���룺����ͼG=(V,E)����Ϊ�Զ��������
��������ֺ�Ľ��D={G1��G2��....GN}
Gi={Ej|EjΪһ�������е�Ԫ��}
�� for each E=(a,b) do
�� if |N(a)��N(b)|�R��|N(a)��N(b)| then
�� merge(a,b);
�� update=true;
�� endif
�� if update=true then
�� goto��;
�� endif
�� endfor
��output G;
���������У�ͨ������ִ��ͼ����Ļ��ַ�ʽ�Ի��ֵ�ij����ͼ���в�����ȷ�ԣ�ͨ���������㷨���Կ�������ij����(a,b),���뵽|N(a)��N(b)|�ݦ�|N(a)��N(b)|�У����Ƿ�����������ͽ��˱���һ������a����ʾ����a����{a,b}{a,b}��Ȼ�������ÿ���߶�ִ�д˴β���֪���������������Ϊֹ����������ͨ�������ĵ���Ϊ���ֽ����һ�������һ���ࡣ�����㷨��ʱ�临�Ӷ�ΪO(d��|E|)��
3.4�����ݶ��ڶ�������ƶȵĸ��ʼ���
���������ò�ȡ��һ��������ʵķ�ʽ��ͨ���˷�ʽ���Լ����ÿ�����ݴ���������������2.3��ͨ��ͼ����ķ�ʽ֪����ͨ���������Եó�������ij�����еĿ����ԡ������=Gi��ͼ���������ƽ�����ƶ�=Pi������ijһ��A��SA-XΪA��Pi����ô�����ڴ����ݷ���ĵĸ���Ϊ:
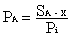 ʽ��1-3��
ʽ��1-3��
Ȼ���ṩһ�����ʼ�����㷨ComputePro��
�㷨5:ComputePro
���룺���ֵ�ͬһ��������鼯��G={G1��G2��....GN};
�����G�ĸ��ʡ�
�� for each Gi in G do
�� Pi=Compute Average degree(Gi);
�� for rach A in Gi do
�� SA-x=Compute Average degree(A);
�� PA=SA-X/Pi
�� end for
�� endfor
�㷨5�ȼ����Gi���������ƶȾ�ֵ��Ȼ������˵�A���������ӵıߵ����ƶȾ�ֵ�����յó�������ʡ�
�ڸ��ʼ�������ж��ڶ�������Ϊn��������Ϊm�Ļ��֣������������ж�����ʵ��ʱ�临�Ӷ�ΪO(m2+mn)��
4.ʵ�鼰Ӧ��
�������IJ��������������ʶ���DRBB�㷨��������Ҫ�Ը��㷨�Ŀ����Խ��в��ԡ�������Javaд�����㷨�ľ��岽�裬Ȼ����ubuntu12.04.1����ϵͳ�ϵ�Hadoop���С����ڸ��㷨�Ŀ����Ի���δ֪״̬��Ϊ�˱���������ö��ַ�ʽ���жԱȺͲ��ԣ����Ǵ���������ȡ���еĺ������ݽ��в��ԣ��ó�
