校园搜索引擎实验报告
目录
实验环境 1
实验内容 1
实现过程 2
抓取校园网资源并处理 2
分词处理 3
词表建立 4
结果排序 4
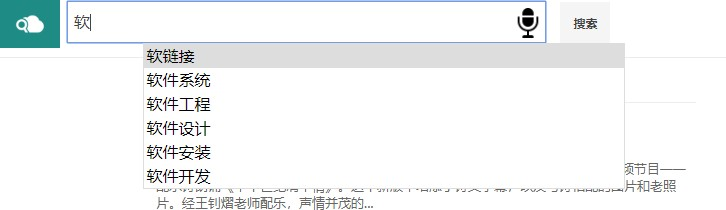
查询提示 5
查询纠错 5
关键词高亮 5
语音输入 5
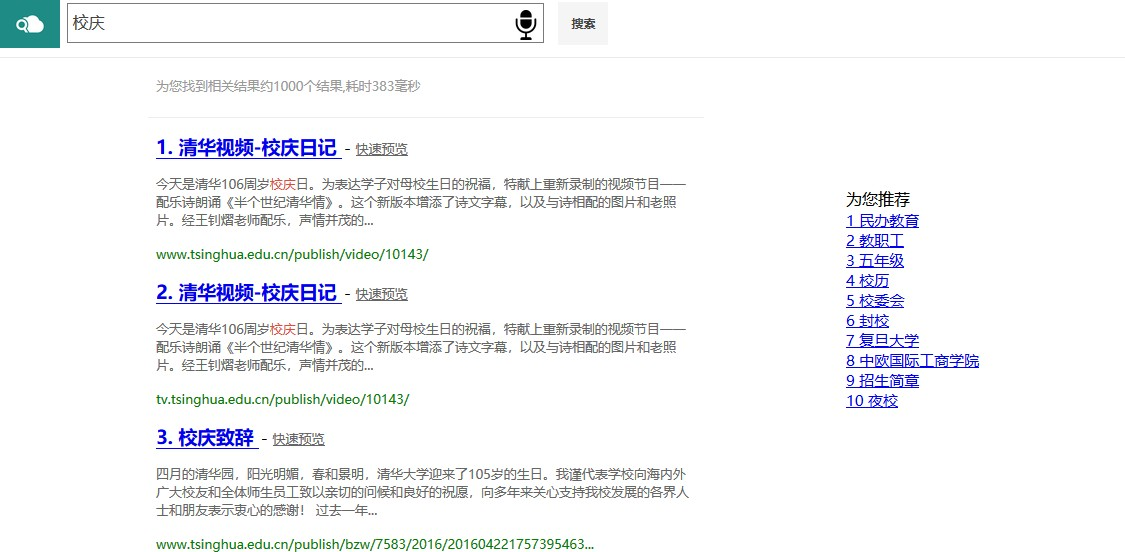
快速预览 5
相关推荐 5
使用说明 7
主页 7
查询推荐 7
查询提示 8
查询结果纠错 9
页面预览 9
性能评价 9
概述 9
查询样例 10
构建相关性标注集合 10
性能分析 11
总结 11
实验环境
apache-tomcat-7.0.86 paoding-analysis-2.0.4-beta IDEA ULTIMATE
win10
实验内容
综合运用搜索引擎体系结构和核心算法方面的知识,基于开源资源搭建搜索引擎,具体包括如下几点:
1.抓取清华校园网内绝大部分资源,并且进行预处理;
2.基于Lucene实现校园搜索引擎――太强搜索;
3.加入关键词纠错、查询提示、语音搜索、相关推荐功能,以提高太强搜索的体验;
4.美化Web界面,实现关键词高亮、快速预览等功能;
5.完成对于太强搜索的性能评价。
实现过程
抓取校园网资源并处理
使用 Heritrix 抓取工具,抓取 HTML,PDF,M.S.Word 格式的文件28万份,共计31GB。编写 Python 脚本处理抓取到的数据,解析成 json 文件: 首先遍历所有抓取到的 文件,为每一个文件分配一个 ID,文件与 ID 一一对应,ID 用于之后PageRank的计算。获取文件的标题、文本 (docContent)、标签(h1~h6)、加粗(strong)信息等。使用
BeatifulSoup 库解 析 HTML 文件内容,获取其中的超链接,为抓取到的整个数据包构建图结构, 根据图结构计算网页的 PageRank,使用pdfminer库解析pdf文件,使用docx2txt库解析word文件。我们发现实际抓到的html文件给出的charset有时是错误的,因此使用了chardet自动判断网页的编码,这样我们便可以处理几乎所有的编码。