摘 要
近年来,深度学习的浪潮渗透在科研和生活领域的方方面面,本文主要研究深度学习在自然语言处理,尤其是古汉语自然语言处理方面的应用。本文旨在利用计算机帮助古文研究者对古汉语完成断代、断句、分词及词性标注等特殊而繁琐的任务,其中的断句、分词是不同于英文自然语言处理的,中文自然语言处理所特有的任务,尤其是断句任务更是古汉语自然语言处理所特有的任务。利用计算机处理古代汉语的各种任务有助于提高语言工作者的工作效率,避免人为主观因素误差,这将他们从繁重的古汉语基础任务中解脱出来,从使他们而将更多的精力投入到后续的授受、义理等内容方面上的研究。
本文使用长短期记忆神经网络作为主体,并针对不同的古汉语自然语言处理任务,设计不同的输入输出结构来搭建具体模型,训练集使用的是网络上公开下载的古汉语语料,并且我们对其中的部分上古汉语语料文本进行了手工标记。本文中设计的模型可对古汉语文本完成断代、断句、分词及词性标注的操作。本文涉及的的主要工作和创新点如下:
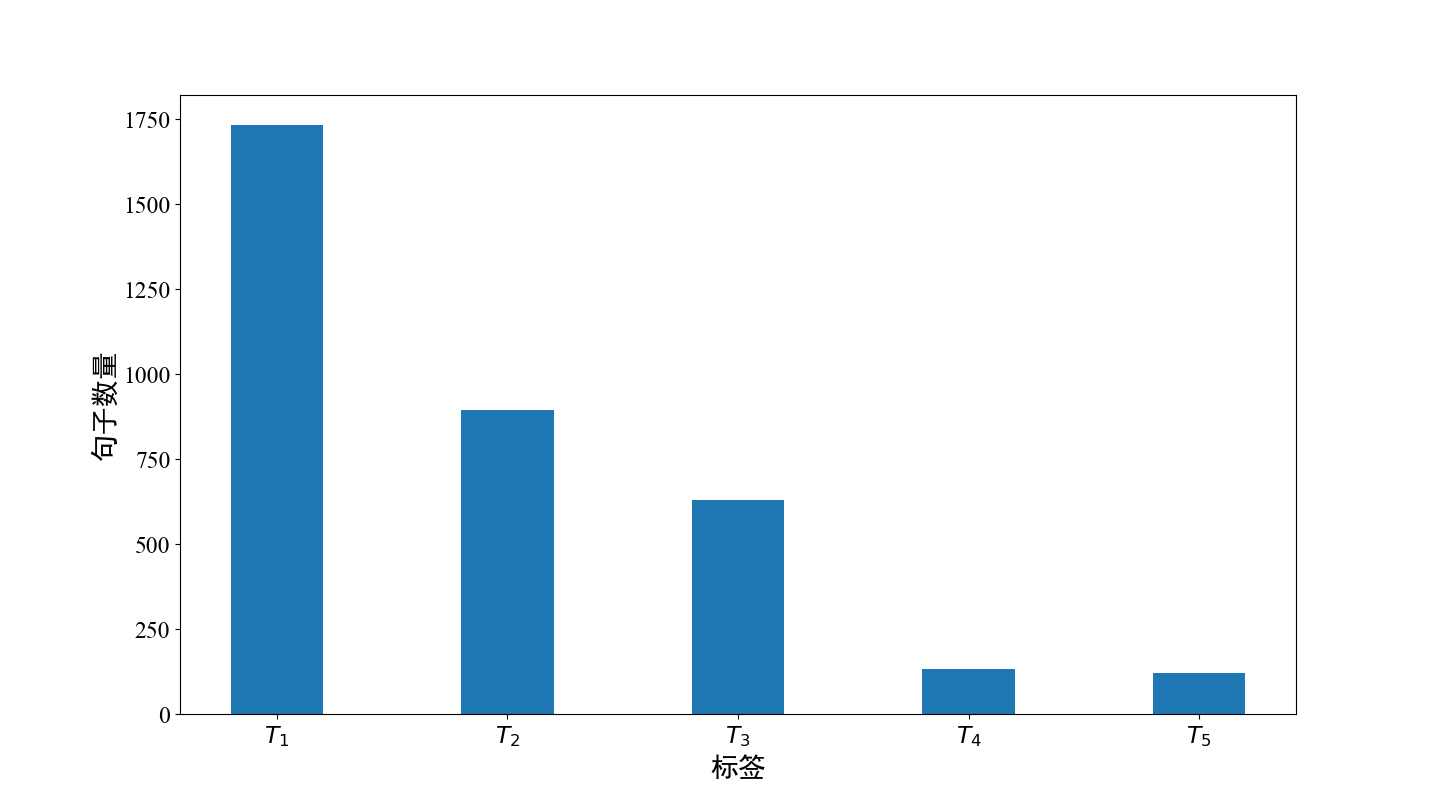
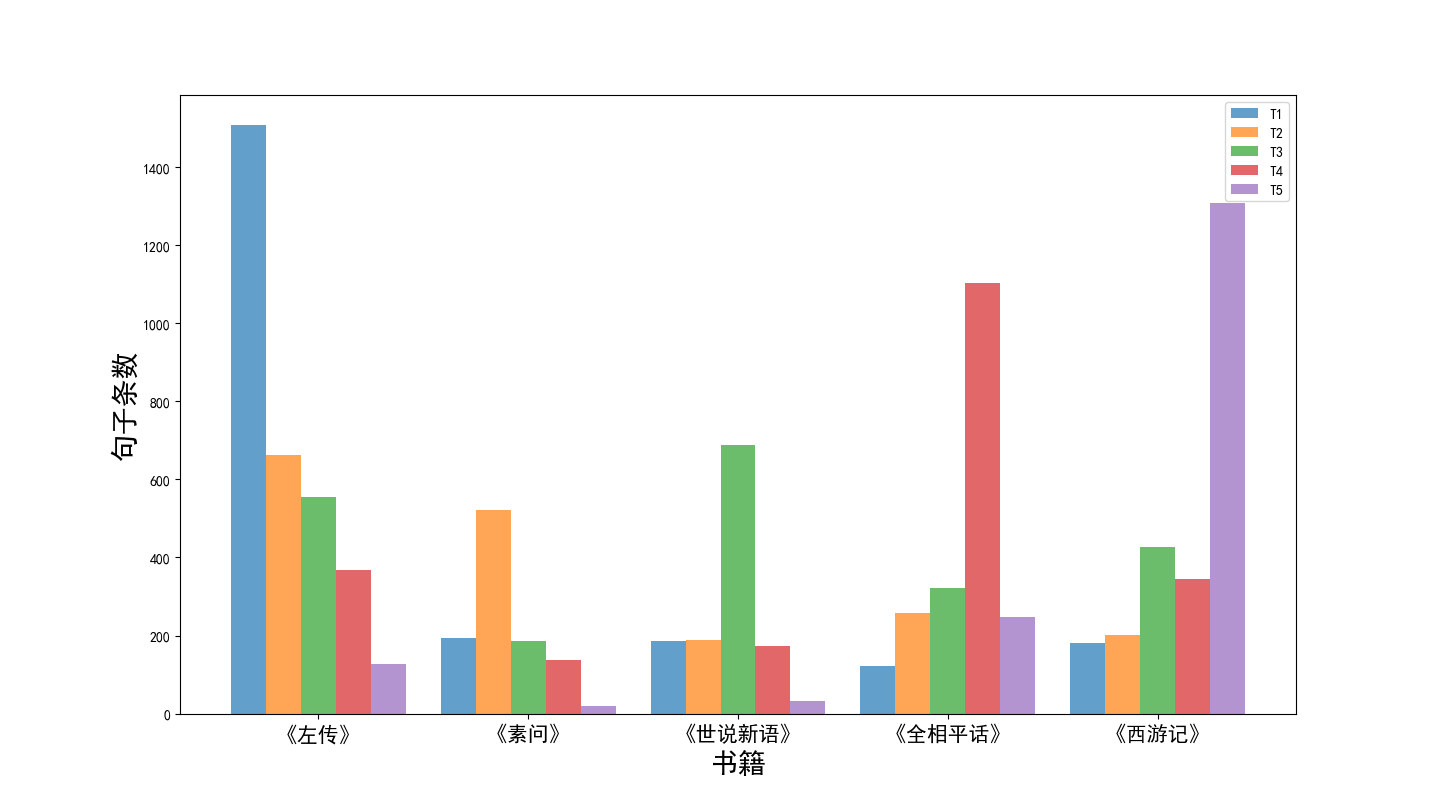
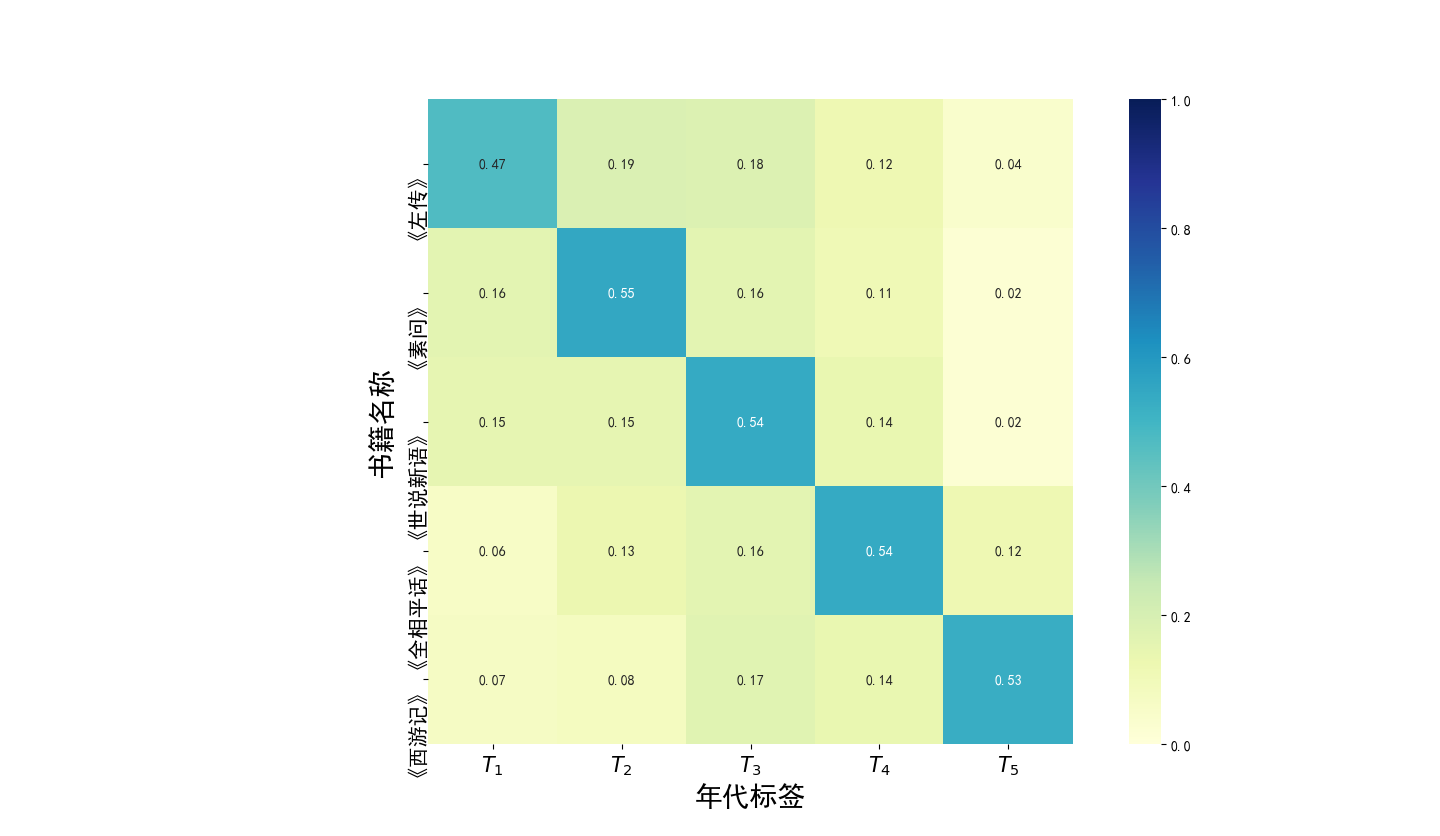
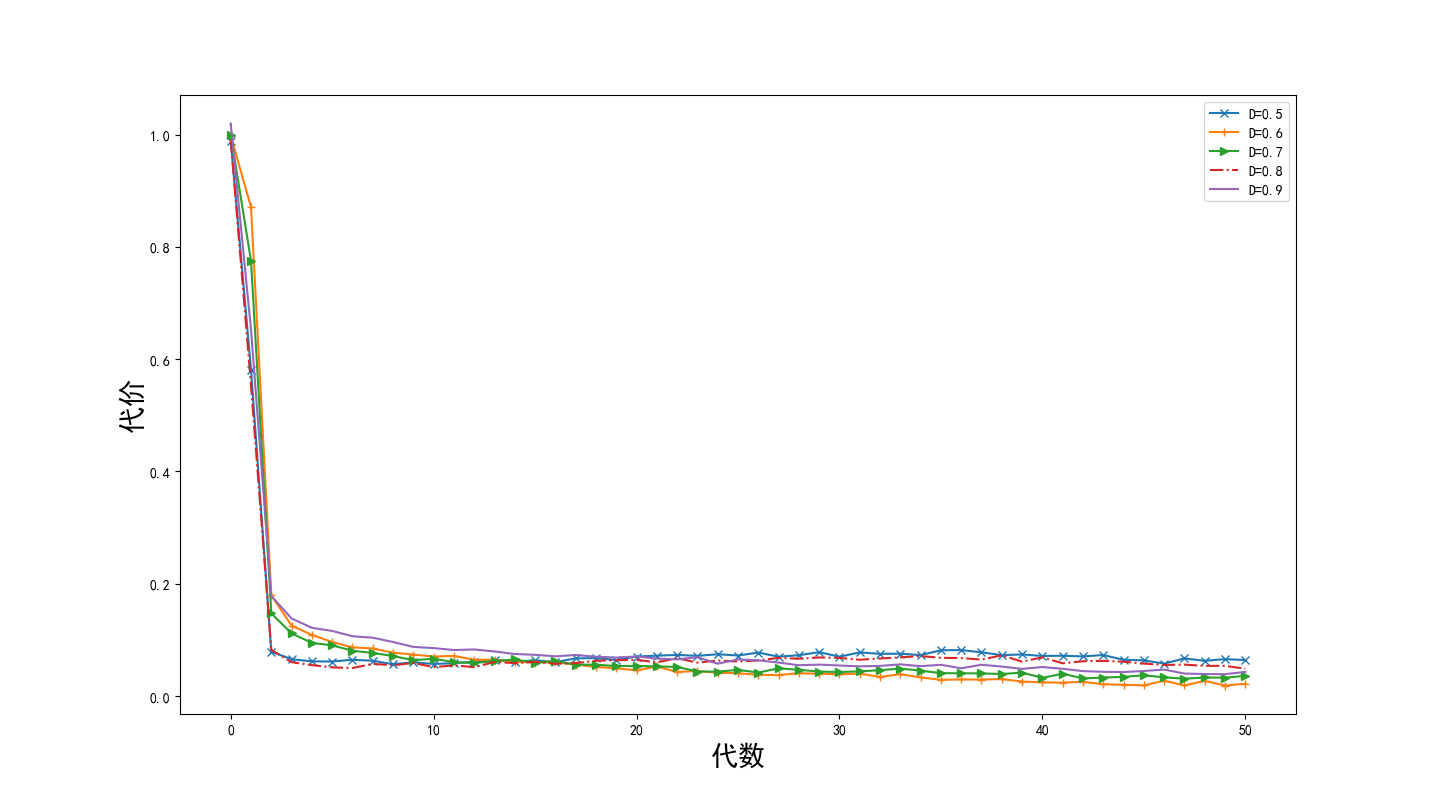
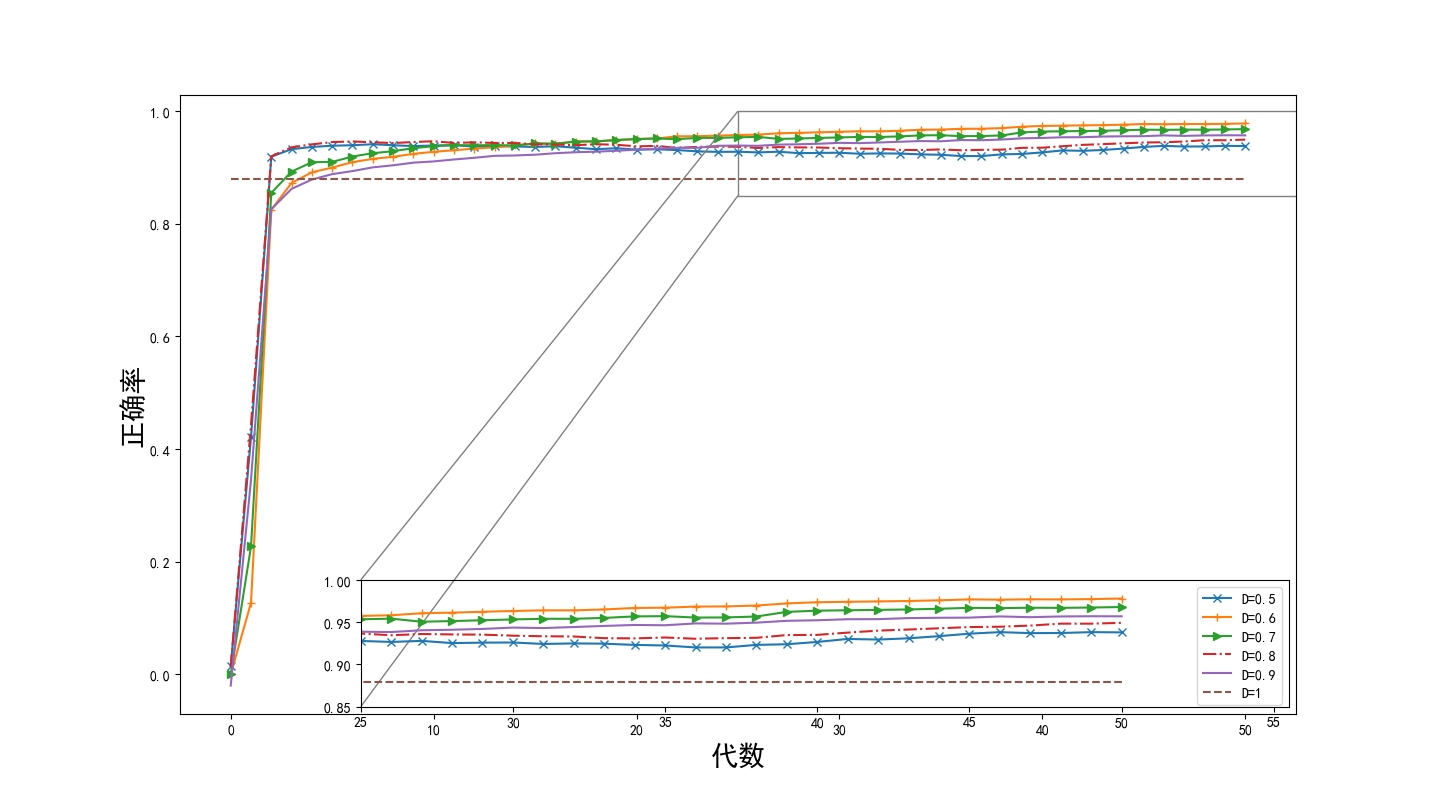
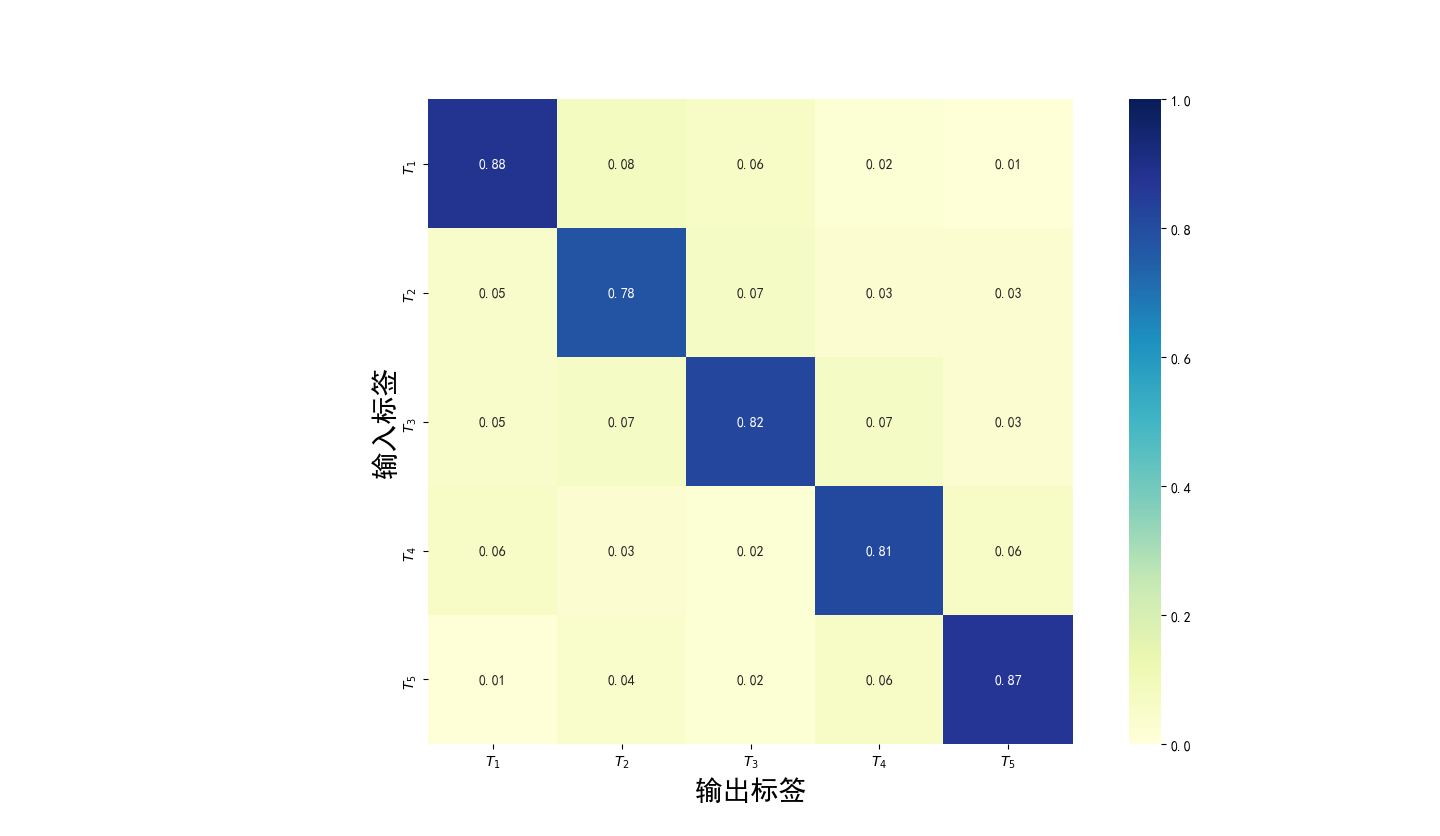
(1)使用长短期记忆神经网络作为主体构建古代文本断代模型。在断代模型当中,文本中的每一个字被转换成一串高维向量,然后将文本包含的所有向量送入模型分析它们之间的非线性关系。最终,模型会输出一个该段文本的年代类别标签。实验结果表明利用Bi-LSTM(Bi-directional Long Short-Term Memory, Bi-LSTM)神经网络构造的模型能够很好的完成断代任务,断代的正确率能达到80%以上。本文的断代模型提供了一种高效且准确的古文断代方法,这将节省古文研究工作者在文本断代过程中的时间。
(2)针对某些古代汉语书籍原著中缺少标点符号的问题,本文提出一个断句模型。本部分我们通过深度神经网络对大量已经断句的古汉语文本进行学习,使断句模型自动学习到某一时期、某种题材的断句规则,从而在后面的古代汉语文献信息化过程中,可以将断句工作交给计算机来完成,减少部分古汉语工作者的任务量。
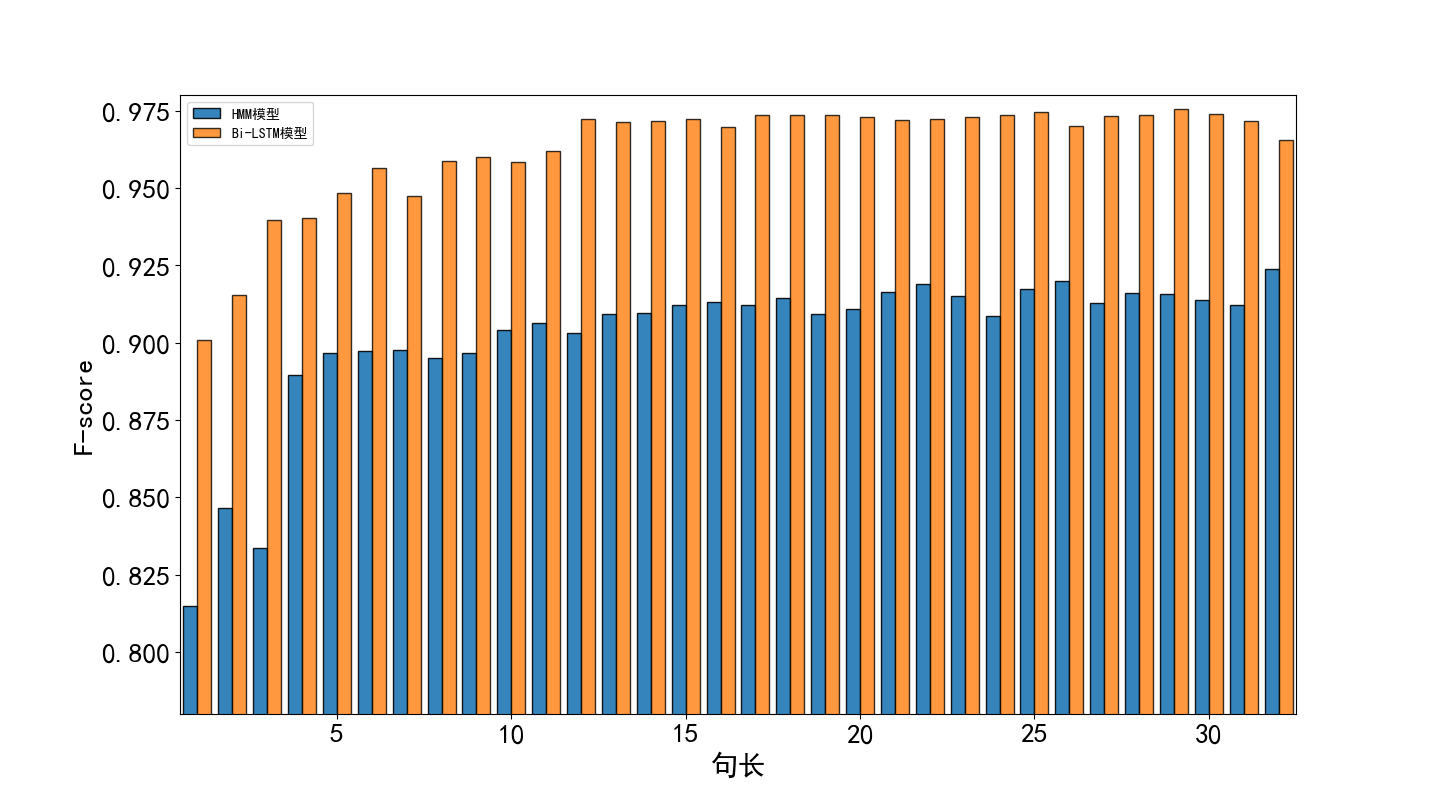
(3)提出一个自动分词及词性标注一体化模型。由于目前尚没有公开的具有分词和词性标注的古汉语语料库,因此本文通过手工标记部分语料的方法得到了少量的数据集,将它们存入数据库作为训练集训练模型。实验表明本文提出的分词标注模型可以较好的完成古汉语分词标注任务。数据库也可通过模型加人工校准的方式进一步扩充。
论文以Bi-LSTM网络为主要结构,建立了一系列针对古代汉语文本不同任务的模型。实验证明,在现有有限的古汉语语料库中本文提出的模型已具备较好的效果,并可以应用到后续更大语料库的构建当中,作为辅助工具帮助古汉语工作者对文本的标记工作。新产生的语料库又可继续用来训练模型提高模型的精度,以此构成语料库和模型互相促进提高的局面,促进古汉语信息化及大型古汉语语料库的构建。
关键词: 古汉语,自然语言处理,断代,断句,分词,词性标注
Machine Learning-based Segmentation, Tagging
and Corpus Building for Ancient Chinese
Abstract
In recent years, deep learning has penetrated into every aspect of research and life. This paper mainly studies the application of deep learning in natural language processing, especially in ancient Chinese natural language processing. This paper aims to use computer to help ancient Chinese researchers to complete special and cumbersome tasks such as dating, sentence breaking, word segmentation and part-of-speech tagging in ancient Chinese. The sentence breaking and the word segmentation are the unique tasks of Chinese natural language processing, especially the sentence-breaking tasks are the unique tasks of ancient Chinese natural language processing. The use of computers to deal with the various tasks of ancient Chinese helps to improve the efficiency of language workers and avoid the subjective factors of human error, which frees them from the heavy basic tasks of ancient Chinese, so that they can put more energy into other aspects of research.
In this paper, we use Long short-term memory neural networks as the main body, and design different input and output structures to build specific models for different ancient Chinese natural language processing tasks. The training set is an ancient Chinese corpus that we have publicly downloaded from the Internet, and we have manually marked some of the ancient Chinese corpus texts. The model designed in this paper can complete tasks such as breaking the ancient Chinese text, breaking sentences, word segmentation and part-of-speech tagging. The main work and innovations covered in this article are as follows:
(1) The Bi-LSTM was used as the main body to construct the ancient text dating model. In the age judging model, each word in the text is converted into a series of high-dimensional vectors, and then all the vectors contained in the text are sent to the model to analyze the nonlinear relationship between them. Finally, the model outputs a time category label for the text of the paragraph. Experiments show that the model constructed by Bi-LSTM can perform the task of age judging well, and the prediction accuracy can reach 80%. The model in this part provides an efficient and accurate method for ancient Chinese texts’ age judging, which will save the time consumption of ancient Chinese researchers in the process of textualization.
(2) In view of the lack of punctuation in the original works of some ancient Chinese books, this paper proposes a sentences breaking model. In this part, we use the deep neural network to learn a large number of ancient Chinese texts that have already been sentenced, so that the sentences breaking model automatically learns the rules of sentences breaking in a certain period and a certain subject. So in the process of informationization of ancient Chinese literature, we can hand over the sentences breaking work to the computer to reduce the task of ancient Chinese workers.
(3) An integrated model of automatic word segmentation and part-of-speech tagging is proposed. Since there is no public Chinese corpus with word segmentation and part-of-speech tagging, this paper obtains a small number of data sets by manually marking tag, and stores them in the database as a training set training model to verify the word segmentation proposed in this paper. Experiments show that the word segmentation and annotation model proposed in this paper can accomplish the task of marking ancient Chinese word segmentation well. The database can also be further expanded by model labeling and manual calibration.
Based on the Bi-LSTM network, the paper establishes a series of models for different tasks of ancient Chinese texts. The experiment proves that the model proposed in this paper has good effects in the existing limited ancient Chinese corpus. The model can be applied to the construction of the subsequent larger corpus as an auxiliary tool to help the ancient Chinese workers mark the text. The new corpus generated by the model can be used to train the model to improve the accuracy of the model, which constitutes a situation in which the corpus and the model promote each other, and promotes the informationization of ancient Chinese and the construction of a large ancient Chinese corpus.
Key Words: Ancient Chinese, Natural language processing, Judging the age, Punctuation, Word segmentation, Part of speech
目 录
致 谢 I
摘 要 III
Abstract V
1 引言 1
1.1 课题研究背景及意义 1
1.2 研究内容 5
1.3 论文组织结构 6
2 研究综述 8
2.1 古代文本断代方法 8
2.2 古代文本断句方法 10
2.3 古代文本分词方法 12
2.4 词性标注综述 16
2.5 本章小结 17
3 古代文本断代模型 18
3.1 数据来源及预处理 18
3.2 模型结构 19
3.3 实验 24
3.4 本章小结 31
4 古代汉语断句模型 32
4.1 数据来源及预处理 32
4.2 模型构建 33
4.3 实验及效果展示 34
4.4 本章小结 38
5 古代汉语分词、标注系统及数据库建设 39
5.1 数据来源及预处理 39
5.2 分类模型的评估标准 41
5.3 模型架构 42
5.4 实验及性能分析 46
5.5 词性标注 49
5.6 本章小结 51
6 总结与展望 53
6.1 总结 53
6.2 展望 53
参考文献 55