目录
一. 问题背景 1
二. 准备工作 2
三. 具体实施 2
1.数据存储及基本加载 2
# 数据整理到数组之中 2
2.数据清洗 2
① 多余列清除 2
② 列属性归一 3
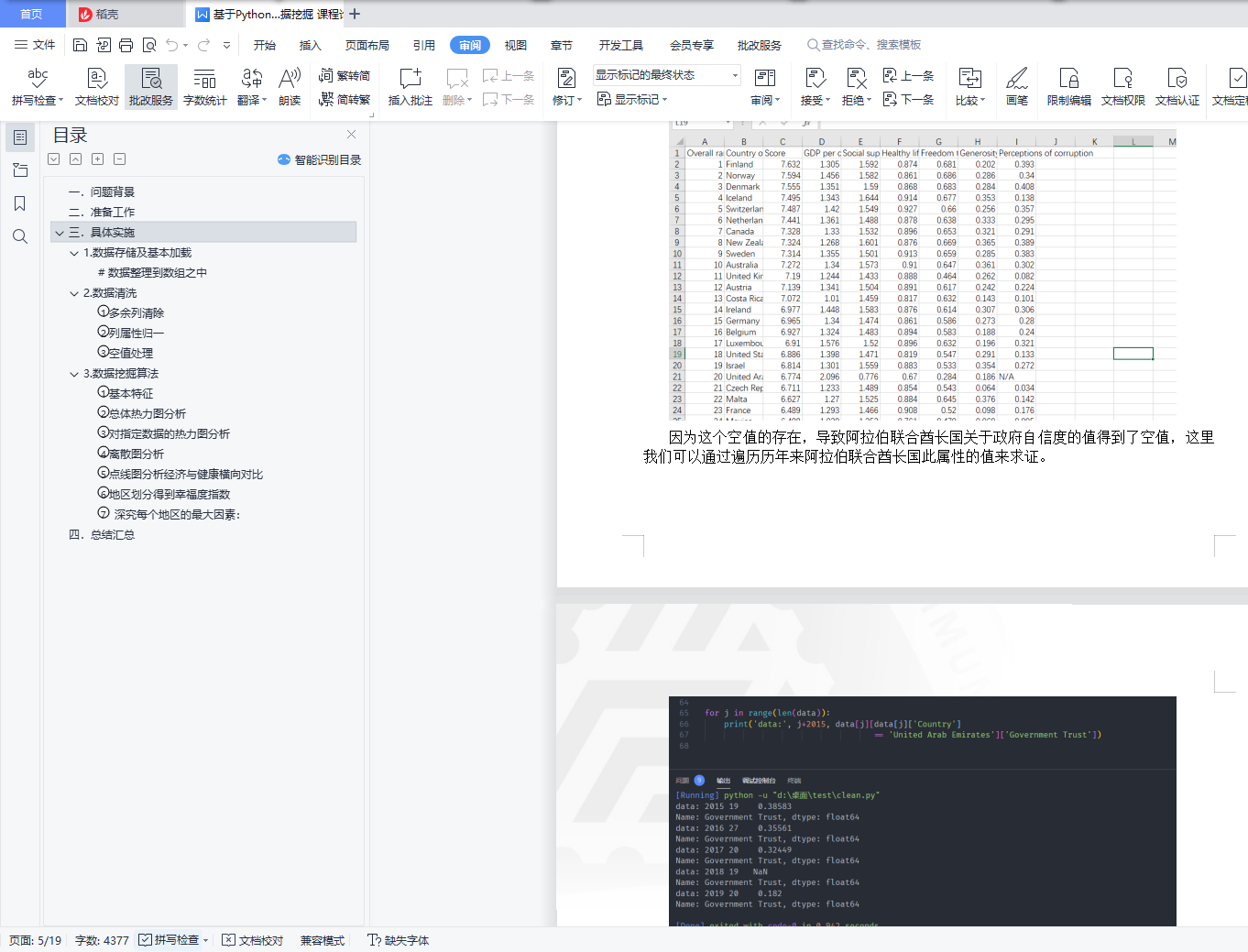
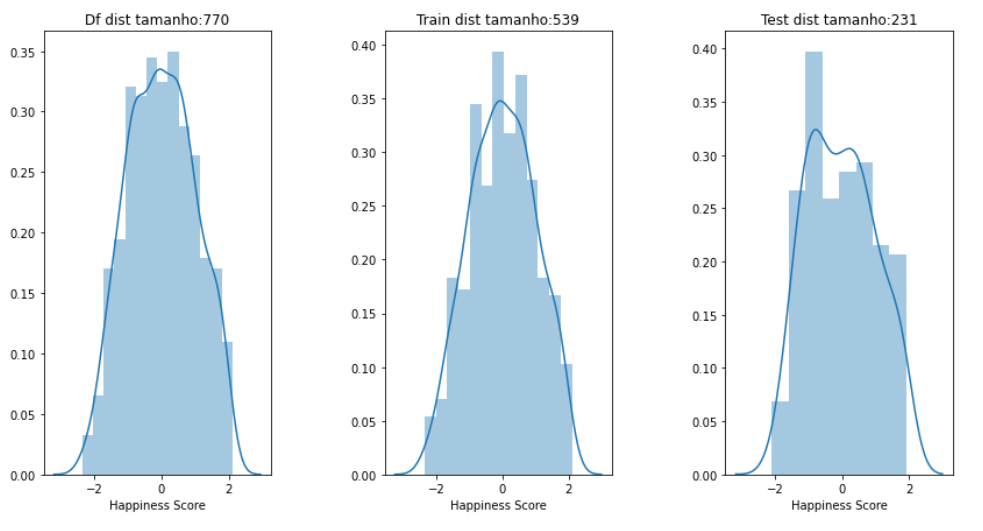
③ 空值处理 4
3.数据挖掘算法 6
① 基本特征 6
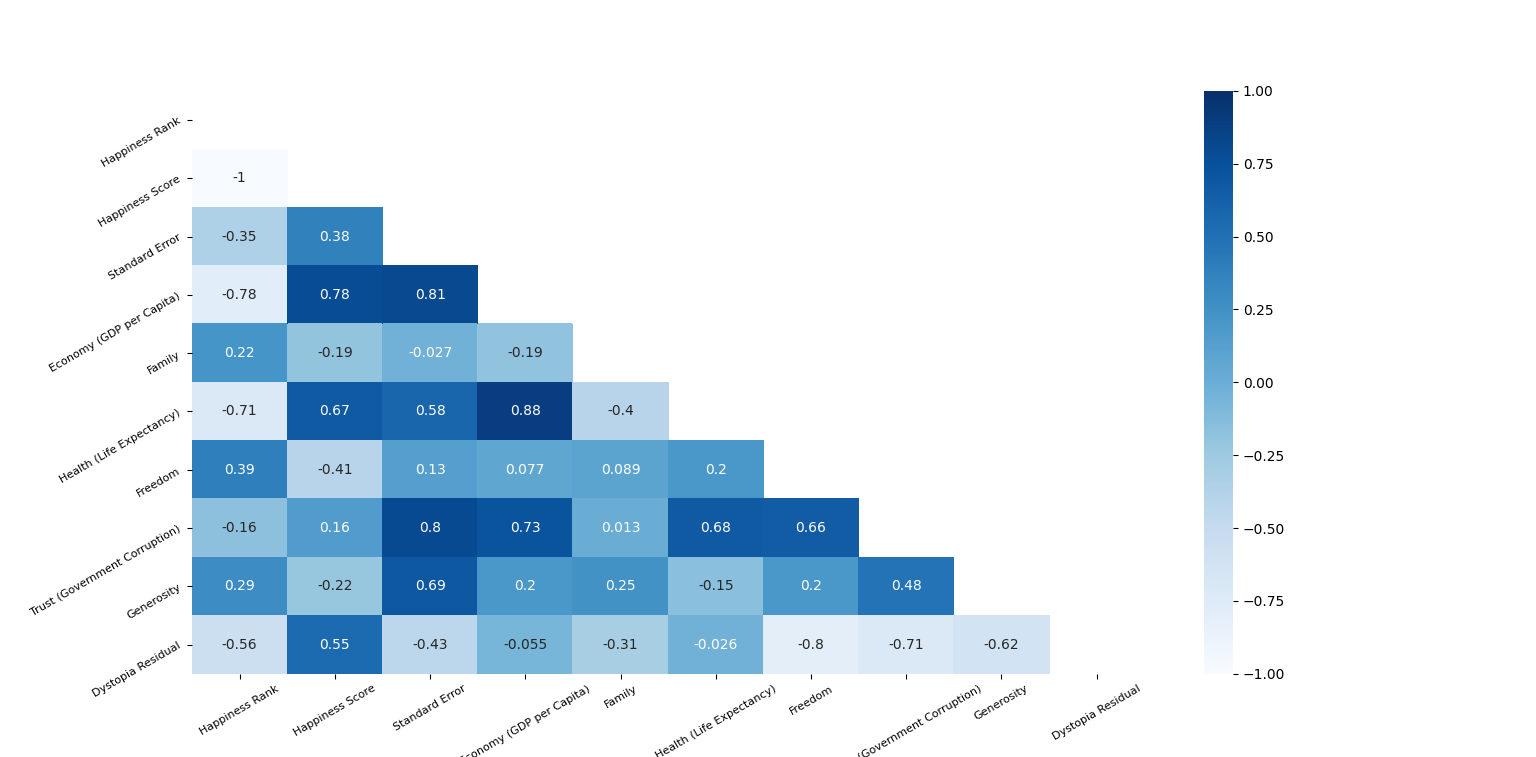
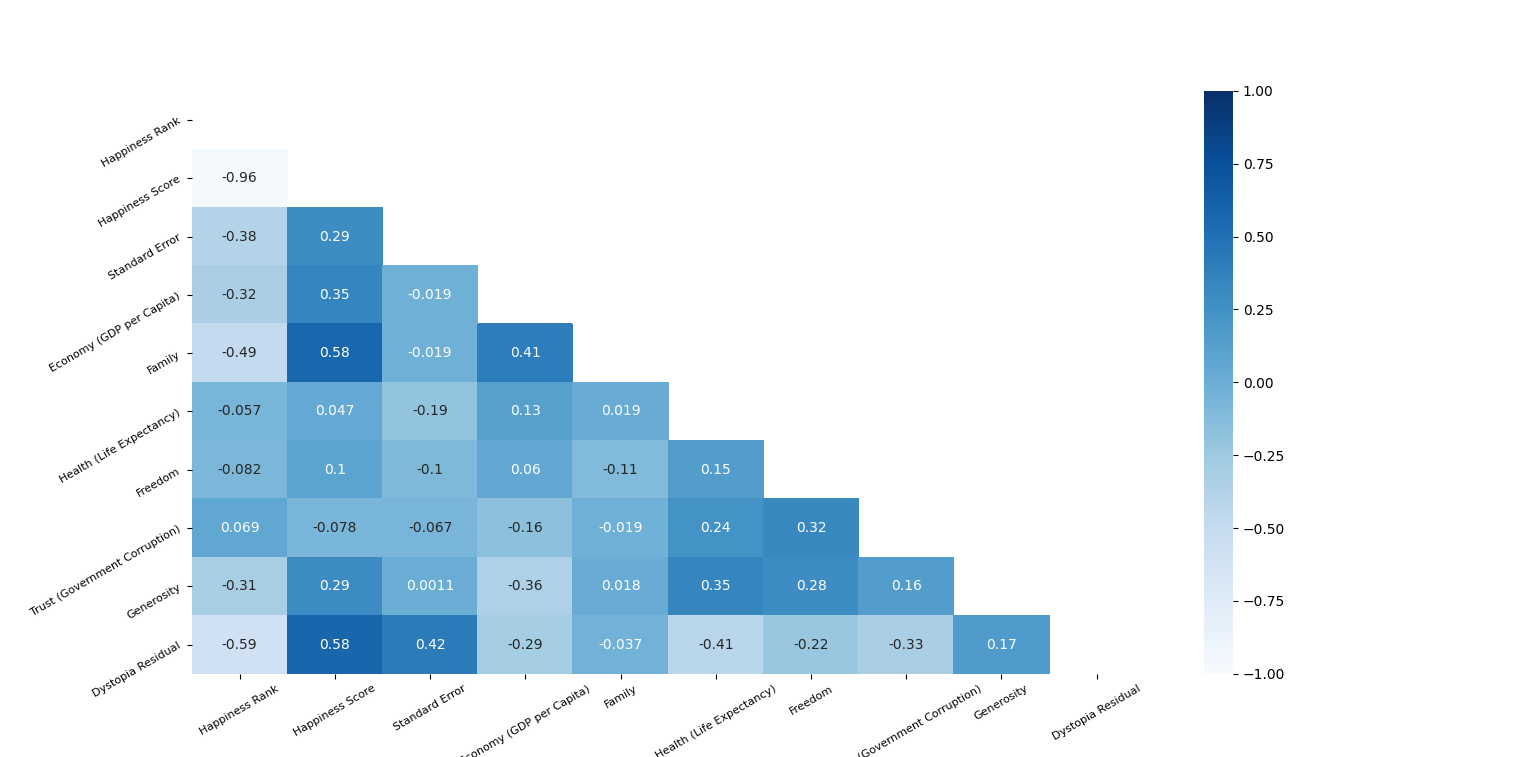
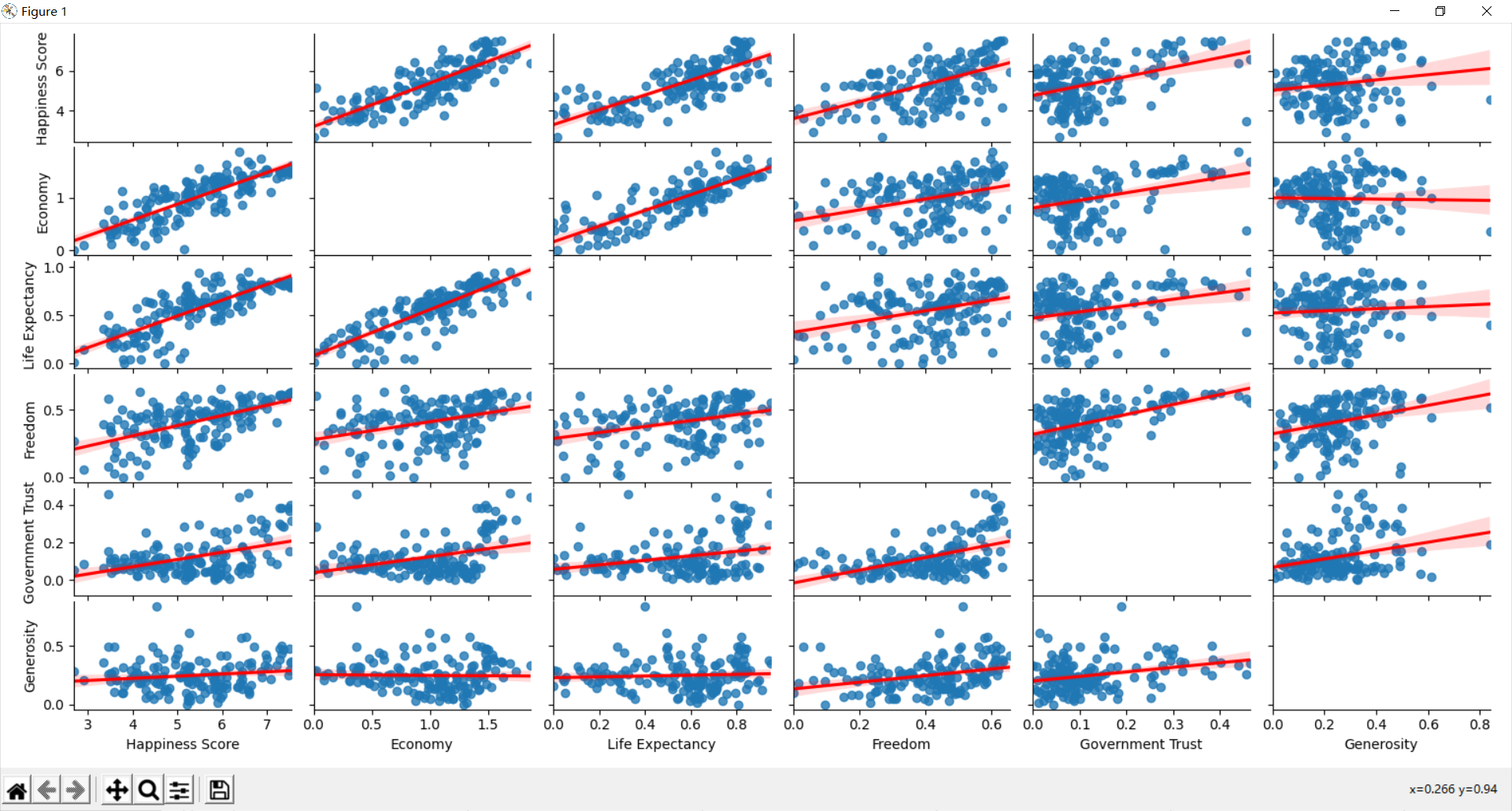
② 总体热力图分析 7
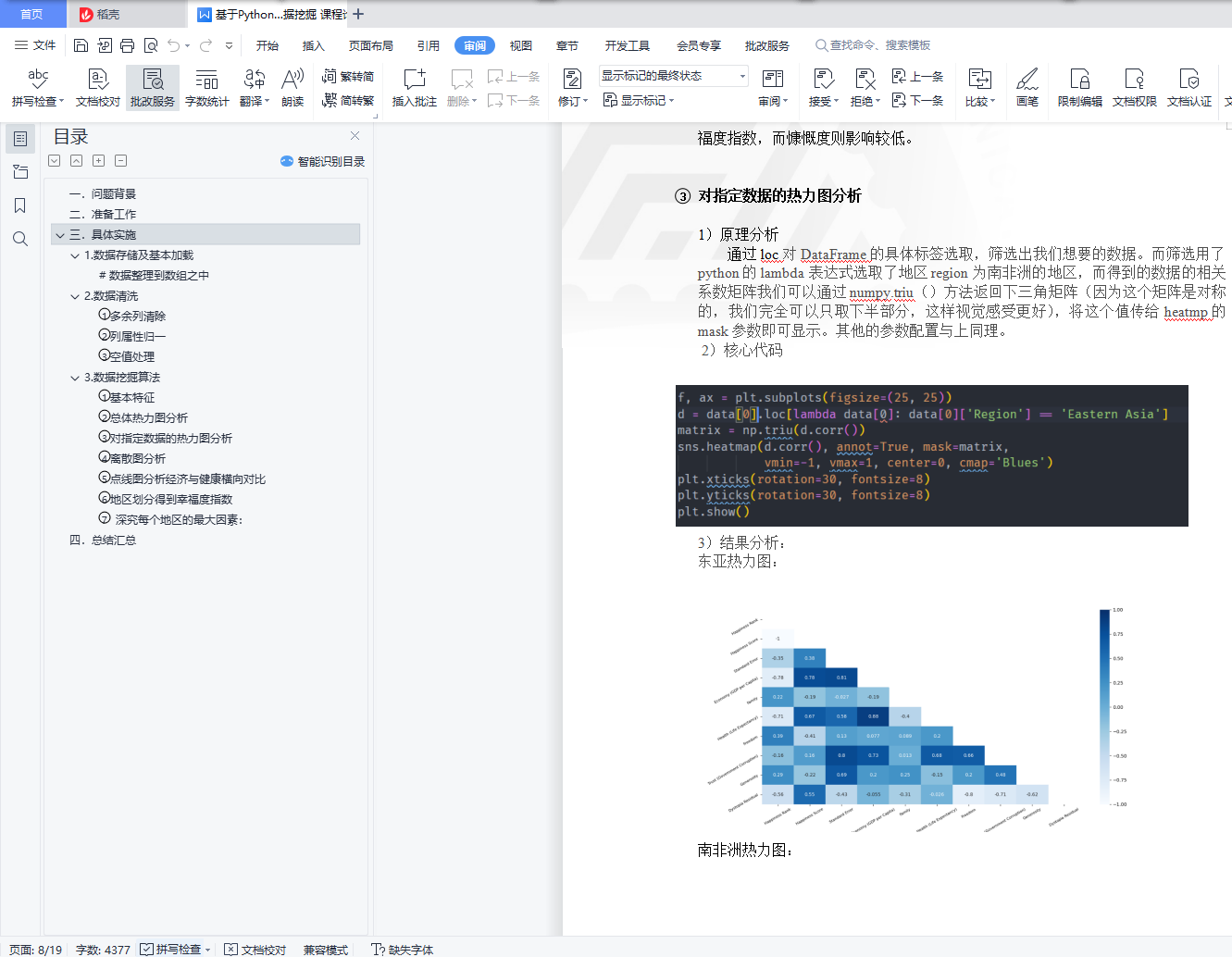
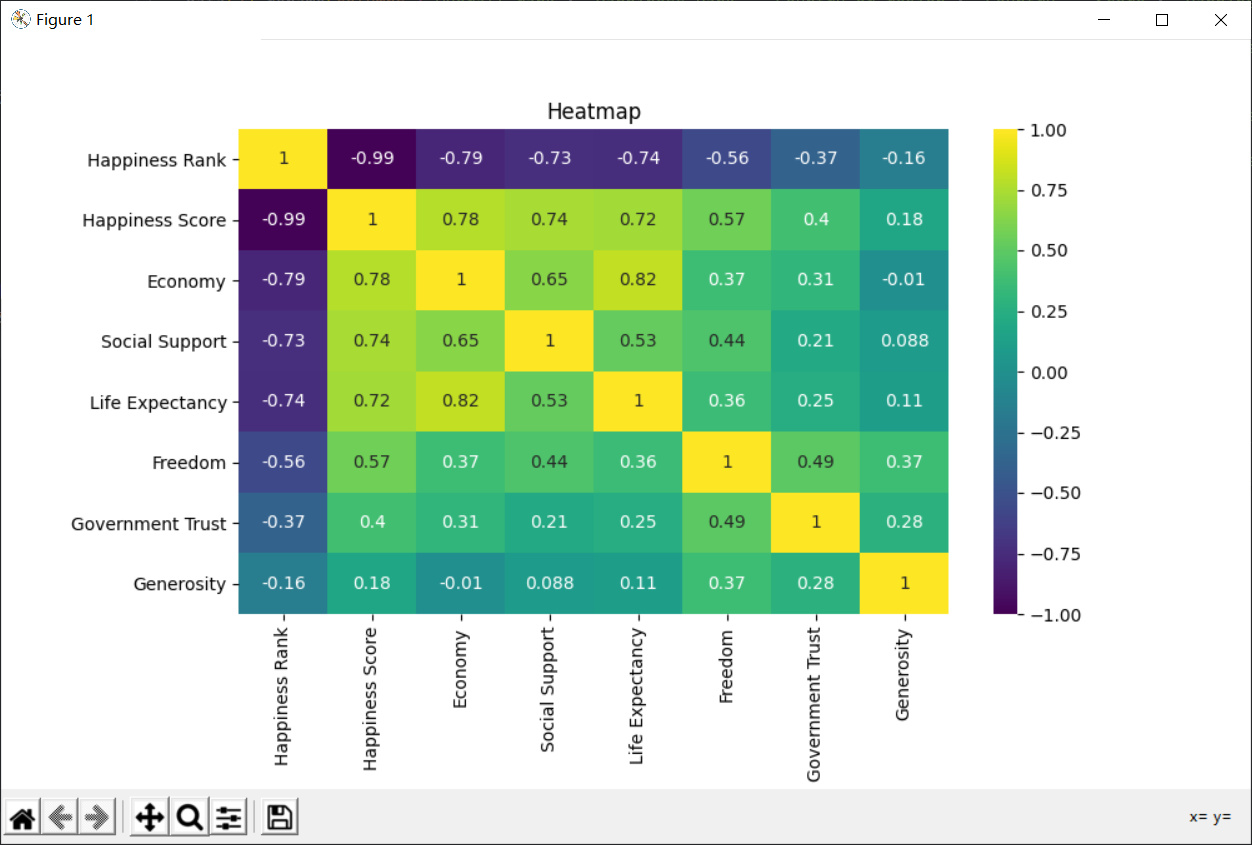
③ 对指定数据的热力图分析 8
④ 离散图分析 9
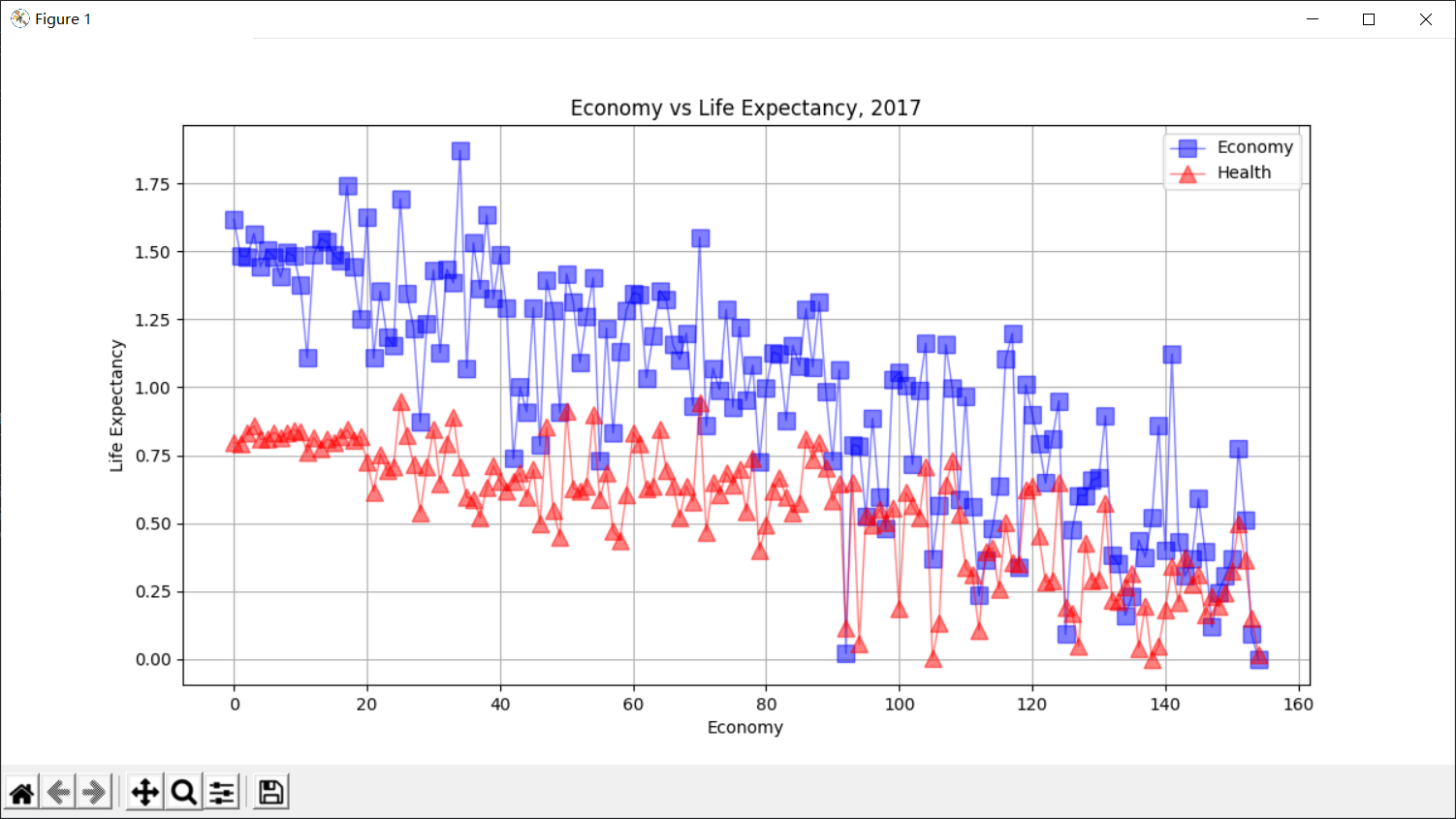
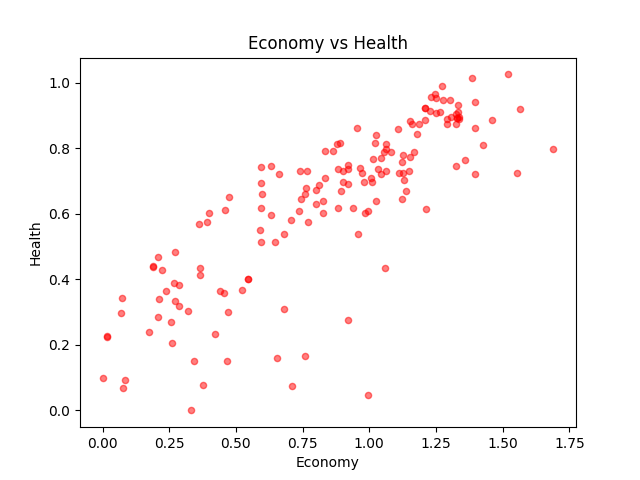
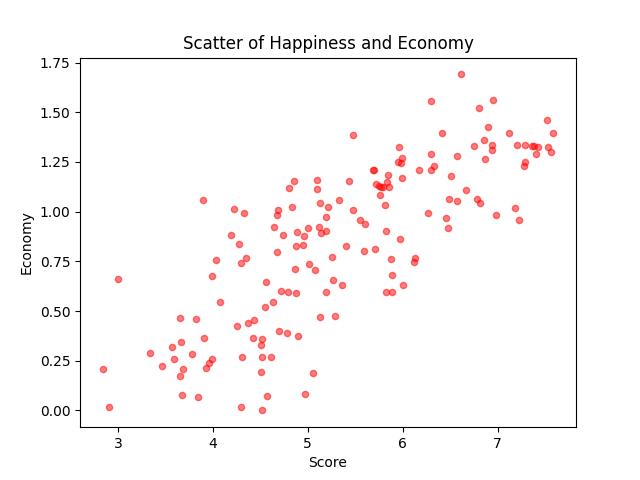
⑤ 点线图分析经济与健康横向对比 10
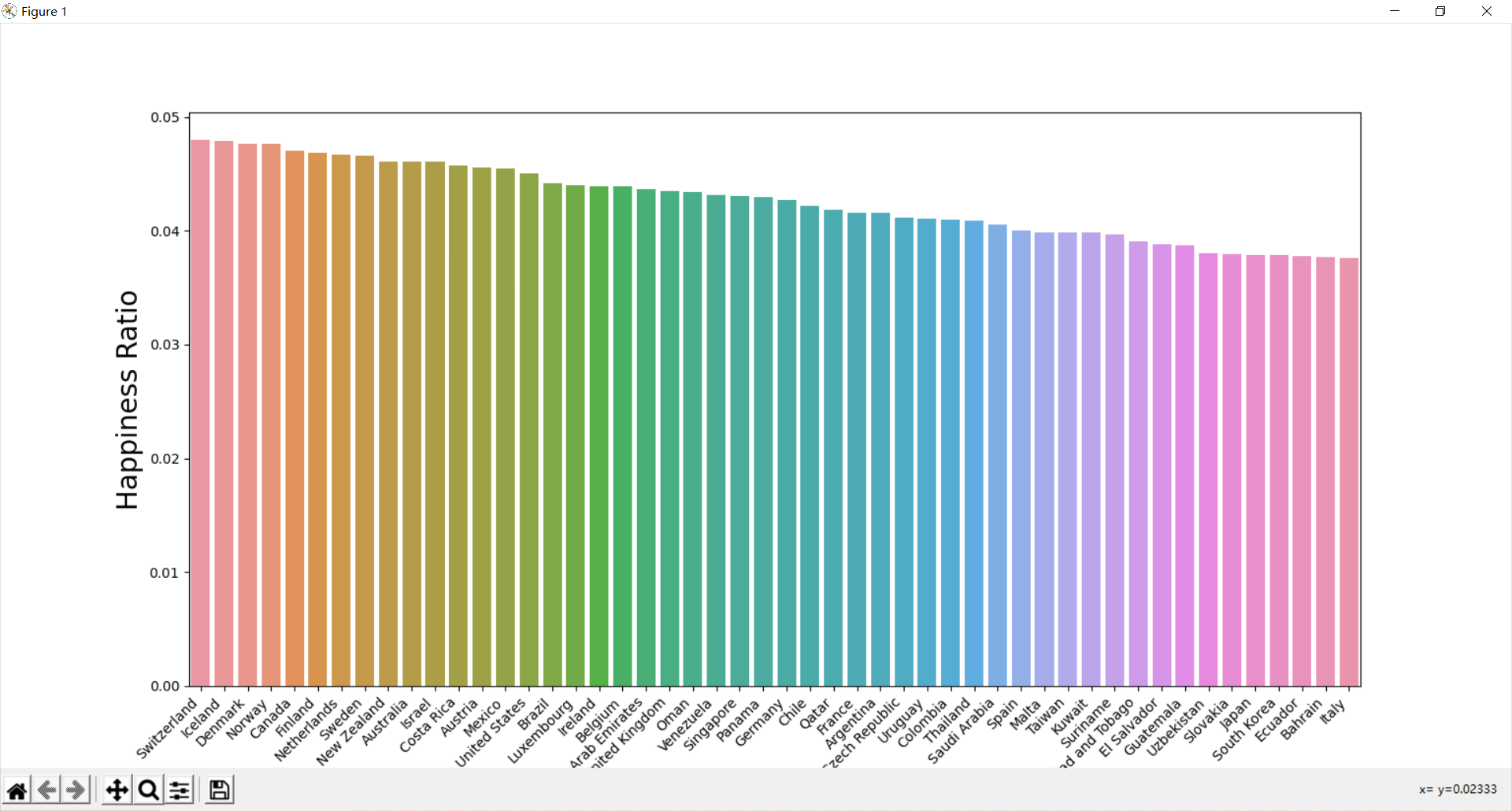
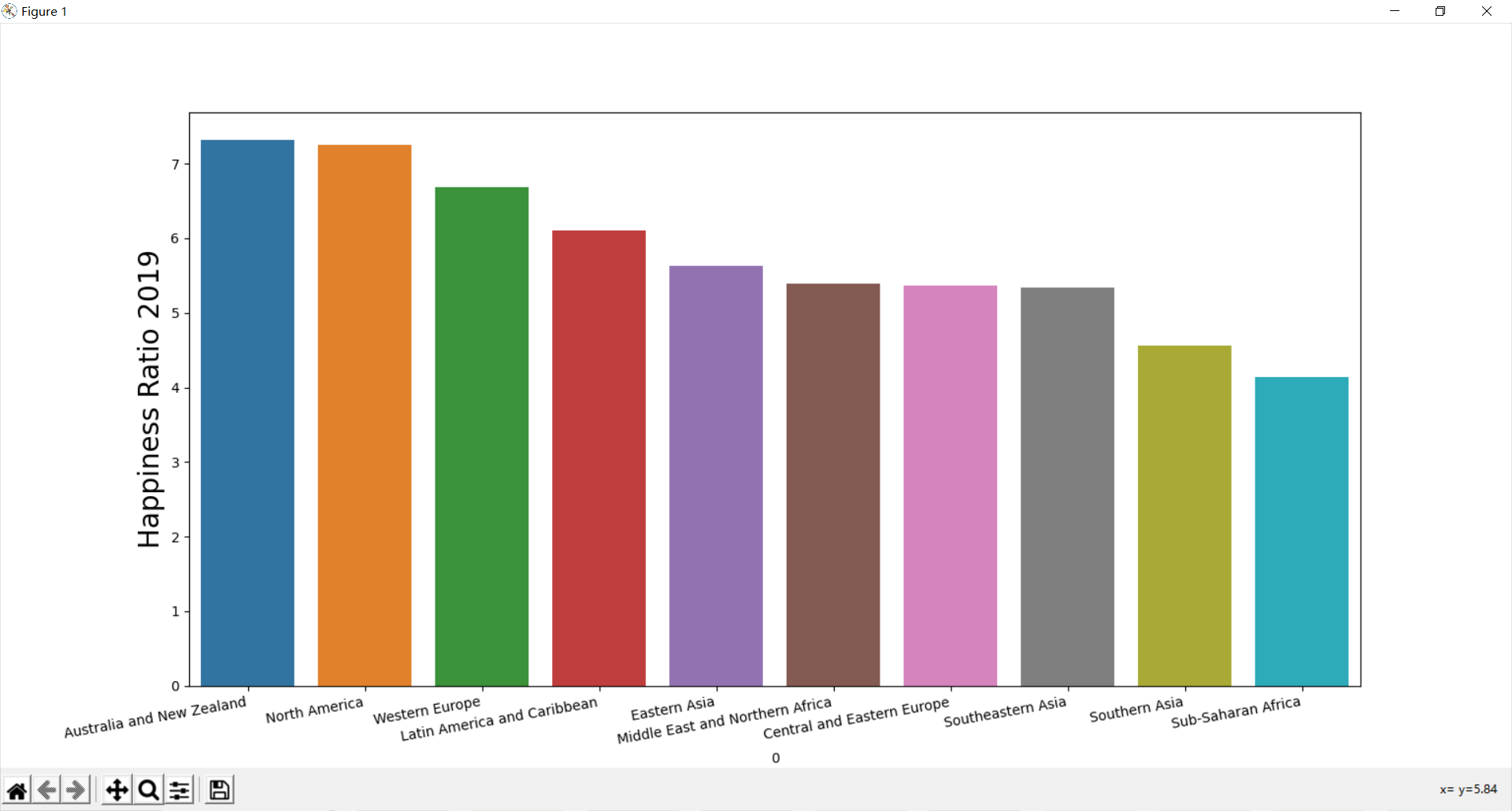
⑥ 地区划分得到幸福度指数 12
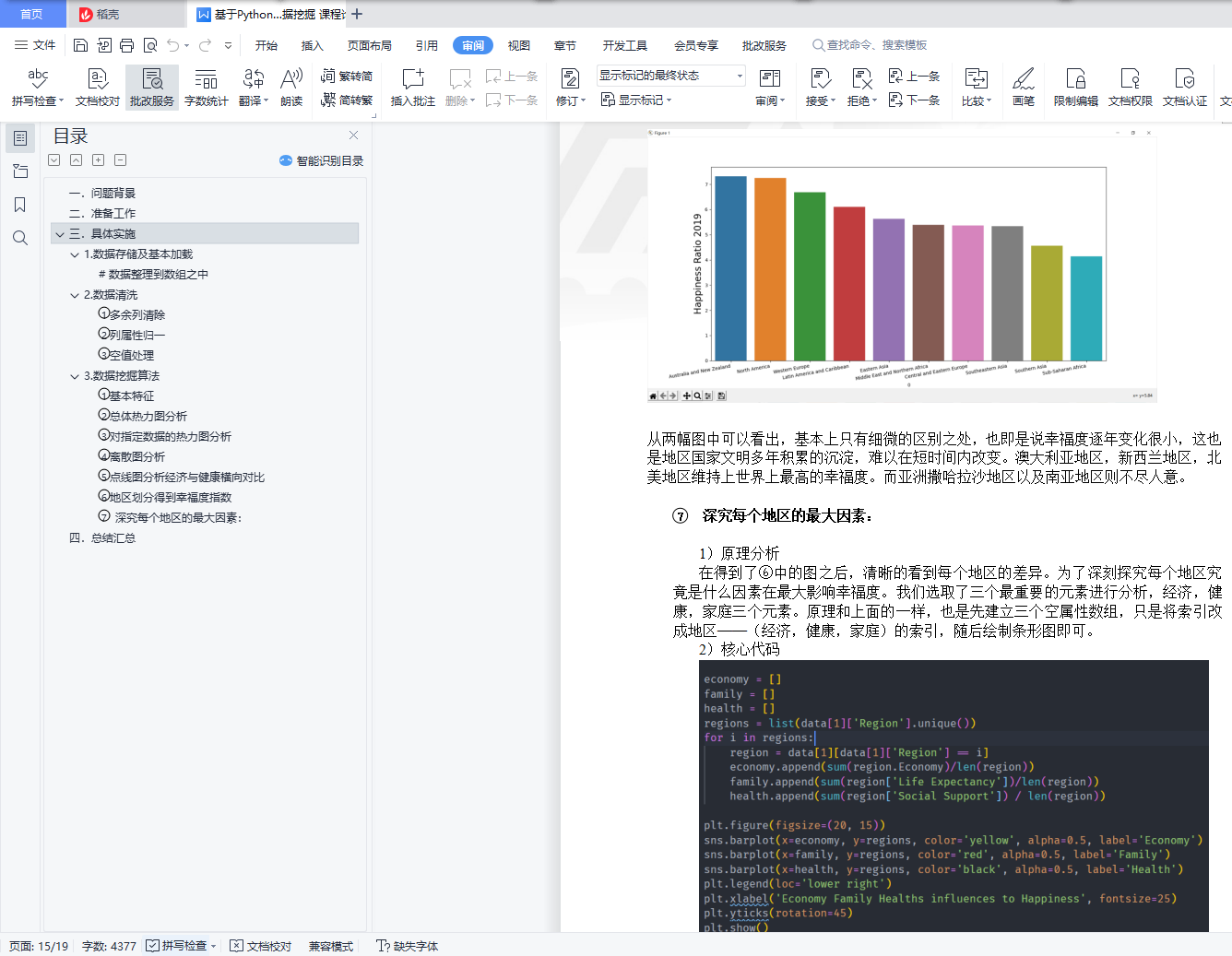
⑦ 深究每个地区的最大因素: 15
四. 总结汇总 16
一.问题背景
《世界幸福报告》是对全球幸福状况的一次里程碑式的调查。第一份报告于2012年发布,第二份于2013年发布,第三份于2015年发布,第四份报告于2016年更新。3月20日,在联合国举行的庆祝国际幸福日的活动上,根据155个国家的幸福水平,发布了《2017年世界幸福》。随着各国政府、组织和民间社会越来越多地使用幸福指数来指导其决策,该报告继续得到全球的认可。经济学、心理学、调查分析、国家统计、卫生、公共政策等领域的权威专家描述了如何有效地利用幸福感来评估国家的进步。这些报告回顾了当今世界的幸福状况,并展示了新的幸福科学如何解释个人和国家在幸福方面的差异。
二.准备工作
小组选择的公开数据集为kaggle上的公开数据集Factors affecting happiness,即一个关于各个国家的幸福度的公开数据集,从2015-2019每一年都有一个数据集。列出了各个国家的幸福度指数,经济情况,健康,宗教信仰,家庭等。
三.具体实施
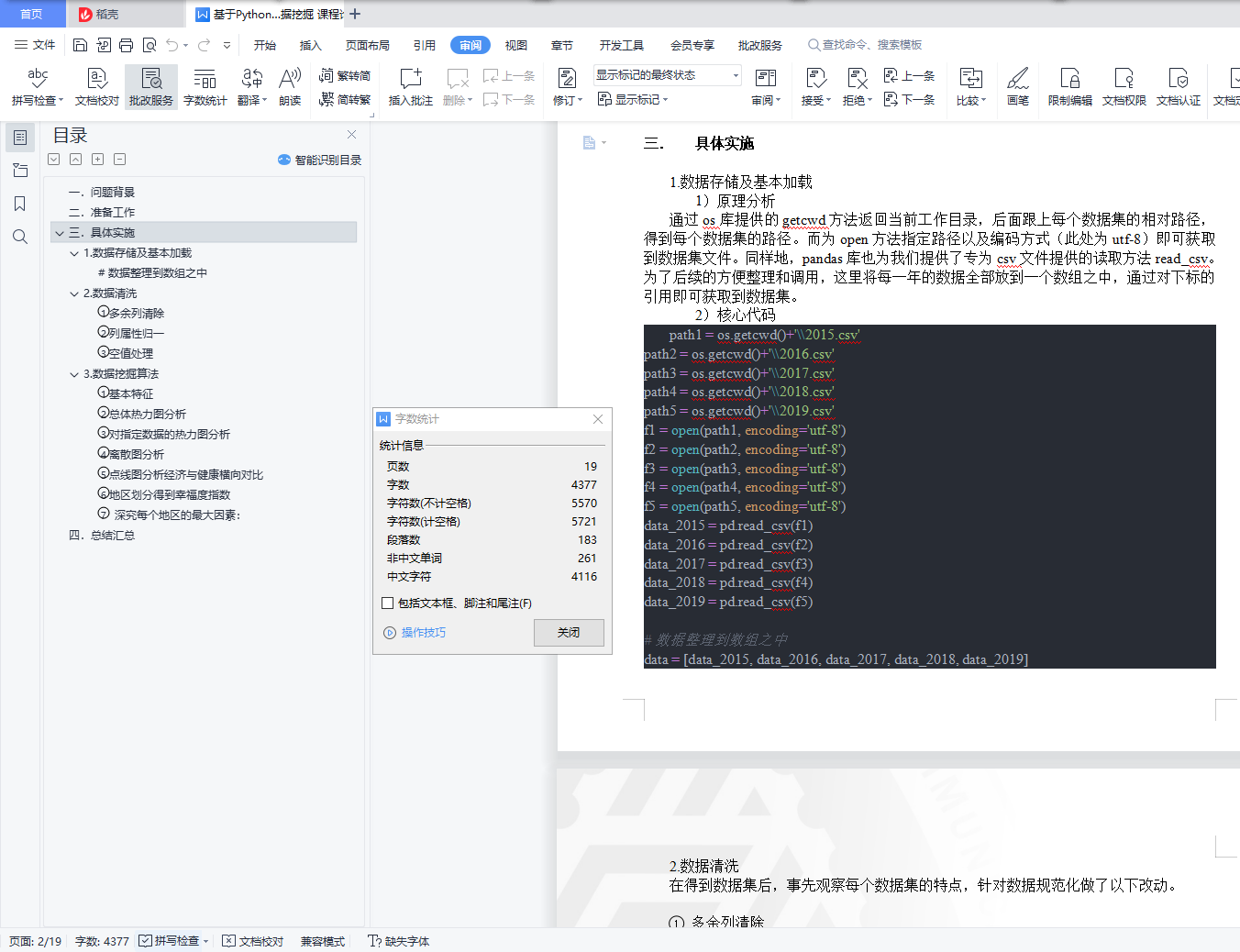
1.数据存储及基本加载
1)原理分析
通过os库提供的getcwd方法返回当前工作目录,后面跟上每个数据集的相对路径,得到每个数据集的路径。而为open方法指定路径以及编码方式(此处为utf-8)即可获取到数据集文件。同样地,pandas库也为我们提供了专为csv文件提供的读取方法read_csv。为了后续的方便整理和调用,这里将每一年的数据全部放到一个数组之中,通过对下标的引用即可获取到数据集。