目录
1需求分析 4
1.1输入输出约定 4
源程序输入 4
文法规则输入 4
词法分析器输出 5
语法语义分析器输出 6
目标代码输出 7
1.2程序功能 7
词法分析器.cpp 7
语法语义分析器.py 8
目标代码生成器.py 8
1.3测试数据 8
input\源程序.txt 8
input\产生式.txt 8
2概要设计 9
2.1任务分解及分工 9
2.2数据类型定义 10
词法分析相关 10
语法分析相关 10
语义分析相关 10
目标代码生成相关 10
2.3主程序流程 11
词法分析器 11
语法分析器 11
语义分析器 11
目标代码生成器 11
2.4模块间的调用关系 11
3详细设计 12
3.1主要函数分析及设计 12
词法分析器 / 读入 12
词法分析器 / 过滤 12
词法分析器 / 分解 12
语法分析器 / 读入 13
语法分析器 / 求 First 集 14
语法分析器 / 求单个项目的闭包 14
语法分析器 / 求项目集族和 Go 转移函数 15
语法分析器 / 求 Action/Goto 表 15
语法分析器 / 分析输入的句子 16
语法分析器 / 构造语法树 16
语义分析器 / 数据结构和实用函数 16
语义分析器 / 详细产生式动作设计 18
目标代码生成器 / MIPS 21
目标代码生成器 / 内存存储变量、寄存器交互 22
目标代码生成器 / 数据结构和数据段格式 23
目标代码生成器 / 将四元式翻译为目标代码 24
1.确定该中间代码的运算类型 24
2.根据 y 所属类型进行不同操作 25
3.执行核心指令。 26
4.将运算结果(若有)存入内存。 26
目标代码生成器 / 核心指令 26
赋值 26
单/双目运算 26
跳转 28
目标代码生成器 / 函数调用 29
目标代码生成器 / 待用及活跃信息表 30
目标代码生成器 / 其它优化 30
3.2函数调用关系 30
4调试分析 31
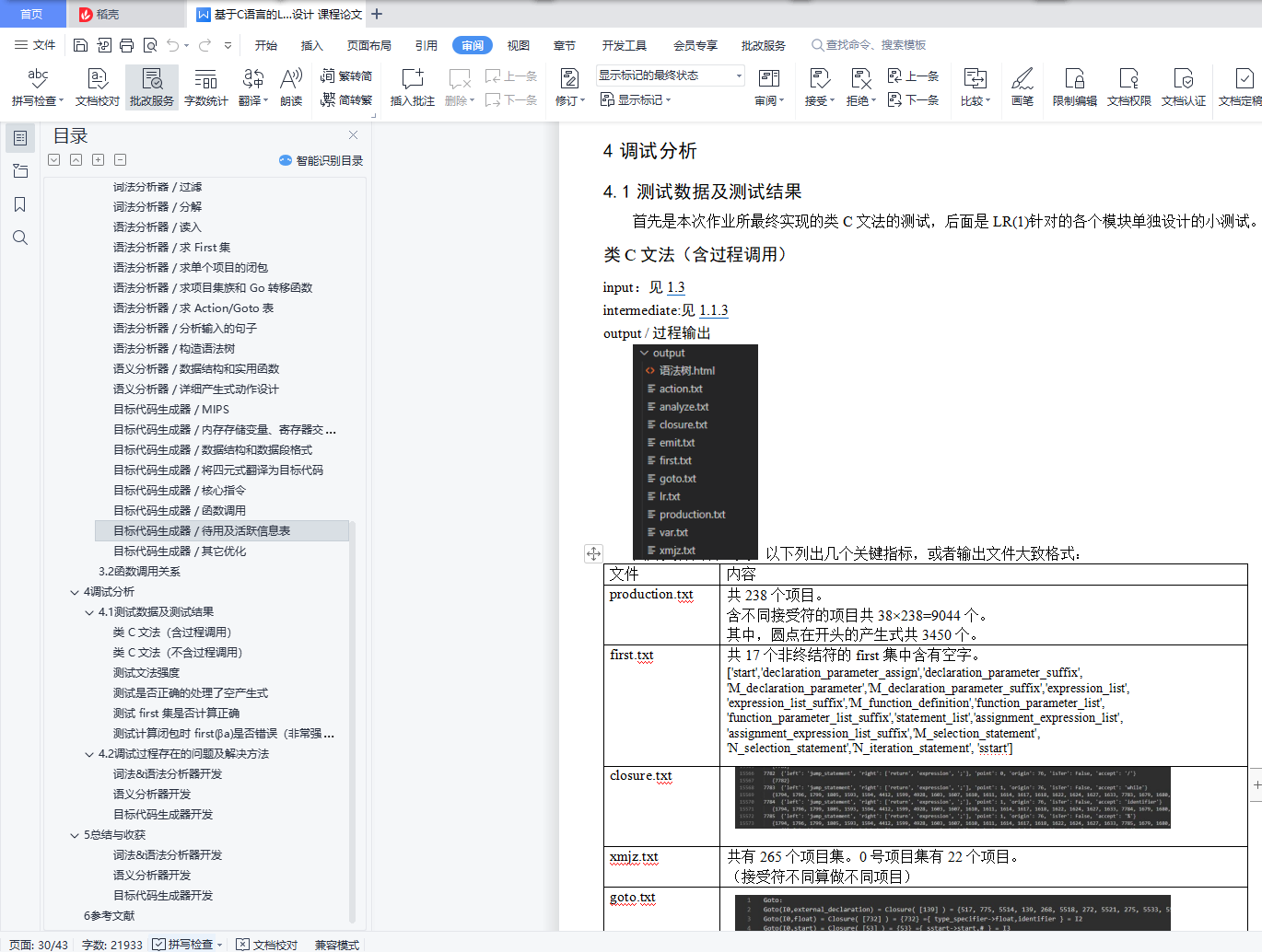
4.1测试数据及测试结果 31
类 C 文法(含过程调用) 31
input:见 1.3 31
intermediate:见 1.1.3 31
output / 过程输出 31
output / 最终输出 32
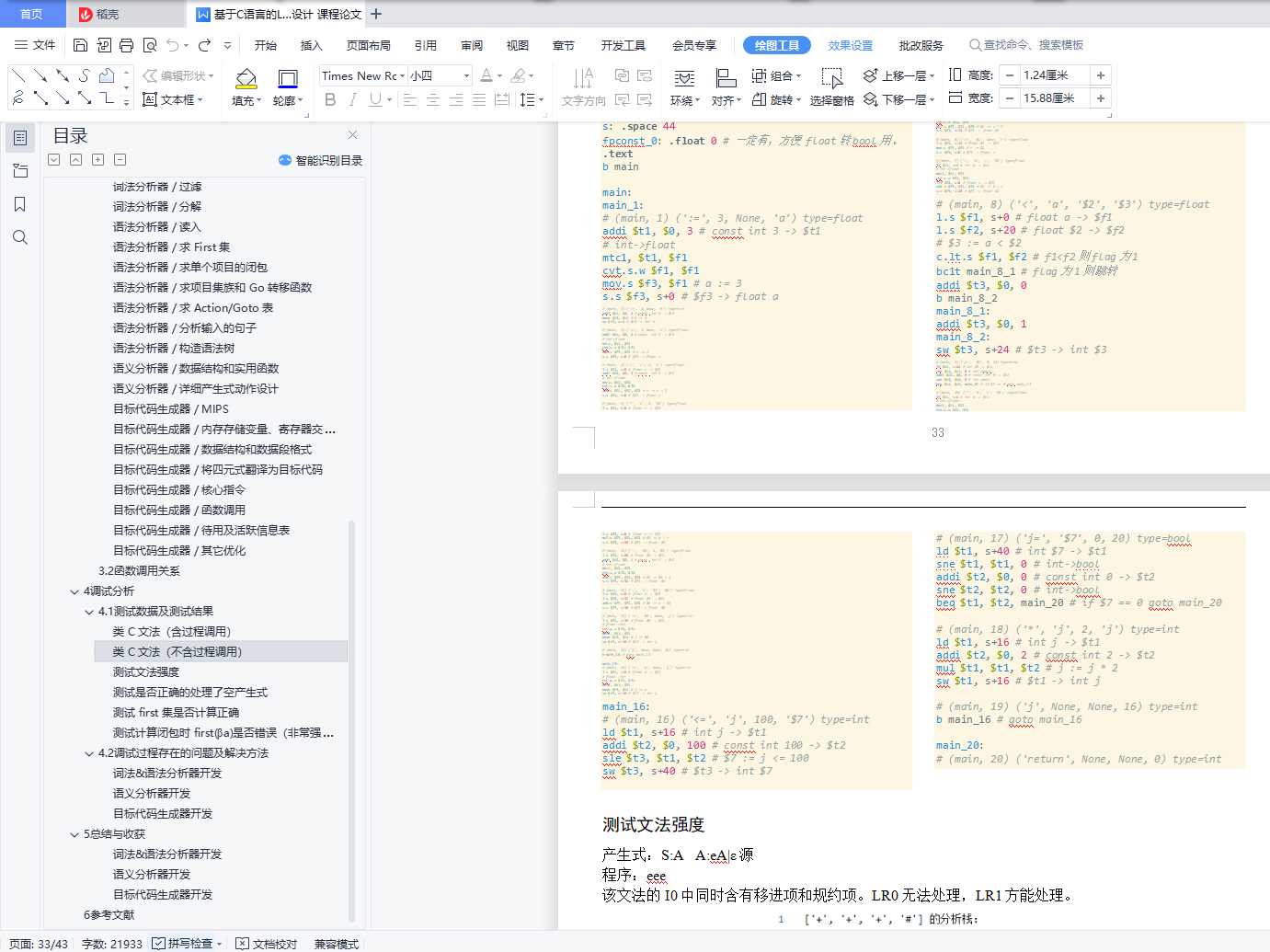
output / object_code.asm 33
类 C 文法(不含过程调用) 33
input / 源程序.txt 34
output / object_code.asm 34
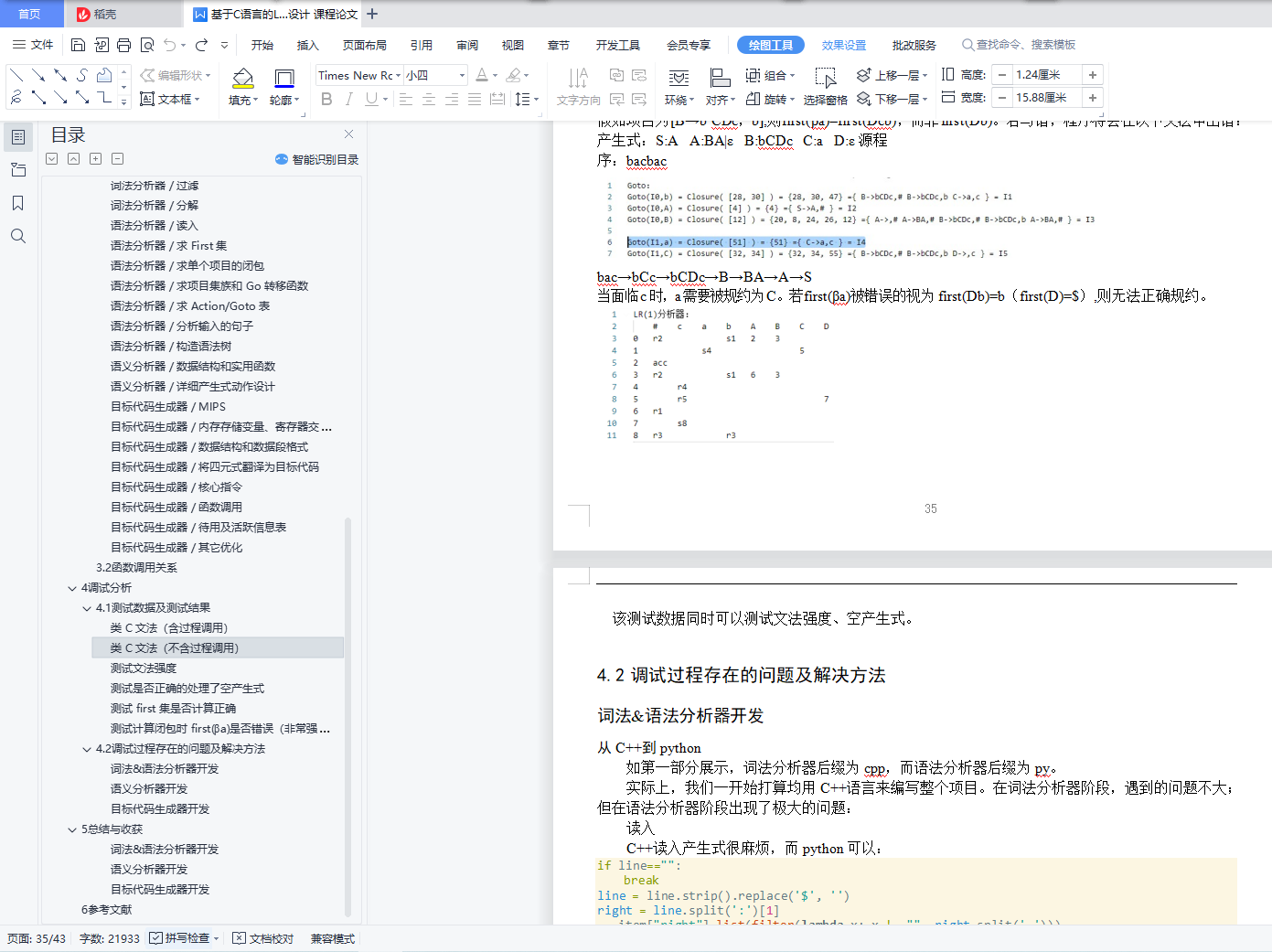
测试文法强度 35
测试是否正确的处理了空产生式 35
测试 first 集是否计算正确 36
测试计算闭包时 first(βa)是否错误(非常强的数据) 36
4.2调试过程存在的问题及解决方法 37
词法&语法分析器开发 37
从 C++到 python 37
如何 debug? 38
语义分析器开发 39
关于 identifier 和 number 39
为什么需要临时 attr?为什么语义动作要分为规约前执行和规约后执行? 39
如何让我的文法支持 int a = 5, b, c = 4.321; ? 39
如何处理 program(a,b,demo(c)) ? 40
同时支持 3 和 4 这两种逗号表达式,会有文法冲突吗?文法依然是 LR(1)的吗? 40
为什么移进 identifier 和移进 number 都被记录为 attr["name"]? 40
我们支持哪些 warning 和 error? 40
关于 bool 41
目标代码生成器开发 41
关于 float 41
关于强转 42
关于 bool 42
5总结与收获 42
词法&语法分析器开发 42
语义分析器开发 43
目标代码生成器开发 44
6参考文献 44
1需求分析
1.1输入输出约定
需要由用户提供的输入位于 input 文件夹中,分别是源程序和产生式。
由词法分析器生成,供语义分析器使用的文件位于 intermediate 文件夹中。由语义分析器生成的,供查阅的文件位于 output 文件夹中。
源程序输入
input\源程序.txt
直接使用 ppt 中的源程序输入即可。具体请见 1.3。
*ppt 中函数调用语句少了分号。
**为了测出并修改词法/语义分析器的 bug,我们构造了许多组具有特点的数据,详见 4.1。
文法规则输入
input\产生式.txt
和语法分析器不同,语义分析器需要对不同的规约做出不同的动作。因此,语义分析器不允许自定义输入文法。
我们的文法规则的输入格式如下:
1.一行只能有一个产生式;对于存在多种可能性的产生式如 S->a|b|c,需要分成若干个不同的产生式分别输入。
2.产生式分为三段:标号、左部、右部。他们之间用冒号分隔。
3.产生式右部不同符号以空格分隔,右部为空可以加入$
4.第一行产生式左部必须为初始符号。初始符号在整个产生式集合中只能出现这一次。
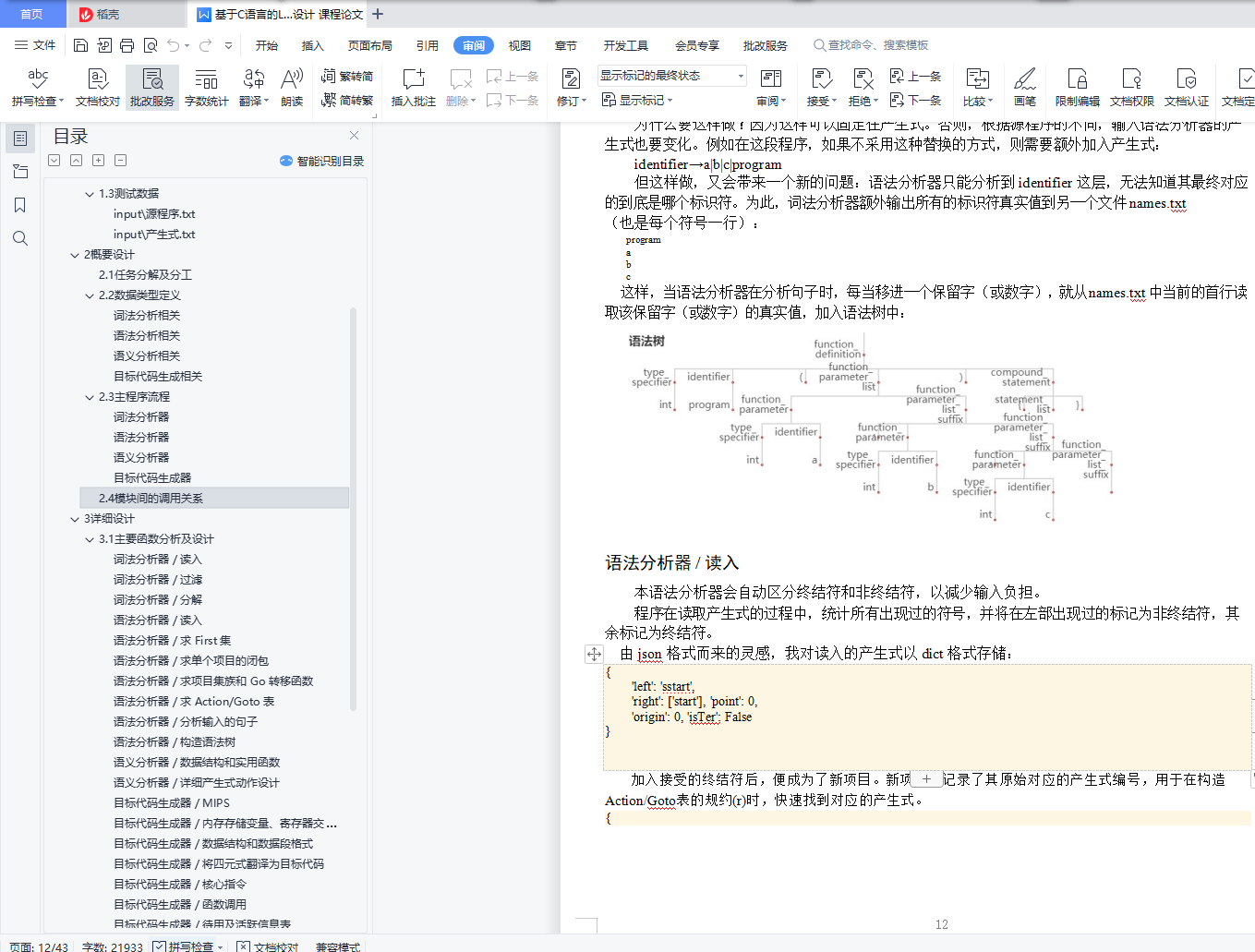
终结符和非终结符会自动区分。程序统计所有出现过的符号,并将在左部出现过的标记为非终结符,其余标记为终结符。
对不同产生式,仅仅用其输入所在的行数作为索引是很不健壮的。因为在编写过程中,可能会需要添加(空转移)产生式来完成一些语义动作。一旦中间插入新的产生式,则后续产生式的行号全部变化。
因此,我们在每条产生式左侧人为添加了序号,方便后续语义动作的索引。这样做还有一个好处,是将产生式人工分类了,变得更加清晰。