网络图片爬虫系统的设计和实现
摘 要
大数据时代,数据资源具有广阔的特点。下载图片和保存图片主要是通过Python图片下载来实现的。目前,基于Python的图片下载和图片存储及技术实现是Python图片下载的主要目的,Python可以为图片下载和图片存储提供思路,在体现数据价值方面发挥着重要作用。因此,可以看出Python在研究图像下载和图像存储的过程中具有显着的应用价值。互联网是一个资源丰富、信息海量的数据库,其中包含着大量的文字图画和每天更新的内容,如何检索和呈现这些数据以供人们使用是非常重要的。本文介绍了利用网络爬虫抓取图片内容的研究现状、技术方法、故障排除等,希望对以后的研究人员有所参考。
进行图像主题爬虫的设计和研究,采用基于文本内容的启发式方法,通过图像文件的锚文本及其上下文来实现主题相关性判断。相关图片资源。对网页也实现了主题相关性判断,以更好地引导爬虫的爬取路径。基于Python 的设计让您可以快速高效地捕获网站数据,Pandas 工具提供简单灵活的数据清理和分析,Python Matplotlib 工具包可以轻松将图像下载结果保存为图形图像。
实验表明,该系统可以达到一定的优化效果,为实现定向目标图像信息获取奠定了良好的基础。
关键词:Python;爬虫;网络图片爬虫;图片下载;图片保存
Design and implementation of the network picture crawler system
Abstract
In the era of big data, data resources have broad characteristics.Downloading images and saving images is mainly achieved through Python image download.At present, Python-based image download and image storage and technology implementation are the main purpose of Python image download. Python can provide ideas for image download and image storage, and plays an important role in reflecting the value of data.Therefore, it can be seen that Python has significant application value in studying the process of studying image downloading and image storage.The Internet is a resource-rich database with massive information, which contains a large number of text pictures and daily updated content. How to retrieve and present this data for people's use is very important.This paper introduces the research status, technical methods, troubleshooting of the Internet crawler, hoping to have some reference to the future researchers.
To design and study the image subject crawler, using a heuristic method based on the text content to realize the subject relevance judgment through the anchor text and its context of the image file.Related Picture Resources.Theme relevance judgment is also realized on the web page to better guide the crawler crawling path.The Python-based design allows you to capture website data quickly and efficiently, the Pandas tools provide simple and flexible data cleaning and analysis, and the Python Matplotlib toolkit can easily save image download results as graphical images.
Experiments show that the proposed system can achieve certain optimization effect and lay a good foundation for the acquisition of directional target image information.
Key words: Python; crawler; network picture crawler; picture download; picture save
目 录
1 绪论 1
1.1 选题背景及意义 1
1.2 国内外研究现状 1
1.2.1 爬虫技术概述 1
1.2.2 爬虫设计者面临的问题与反爬虫技术现状 3
2 相关理论及技术 7
2.1 robot协议对本设计的影响 7
2.2 爬虫 7
2.2.1 工作原理 7
2.2.2 工作流程 8
2.2.3 抓取策略 8
2.3 Python及Pycharm简介 8
2.4运行环境和系统结构 9
3 系统设计 9
3.1环境搭建 9
3.2设计思路 10
3.3 第三方类库的简介和安装 11
3.3.1 Scarpy简介及安装 11
3.3.2 Numpy简介及安装 12
3.3.3 Pandas简介及安装 12
3.3.4 JieBa简介及安装 13
3.3.5 WordCloud简介及安装 13
3.3.6 Matplotlib简介及安装 13
3.3.7 Pygal简介及安装 13
3.3.8 re简介 13
3.3.9 json简介 14
3.3.10 os简介 14
3.3.11 shutil简介 14
3.3.12 pathlib简介 14
3.3.13 random简介 14
3.3.14 math简介 14
3.3.15 PIL简介 14
3.4 Scrapy详解 15
3.4.1 架构介绍 15
3.4.2 数据流 16
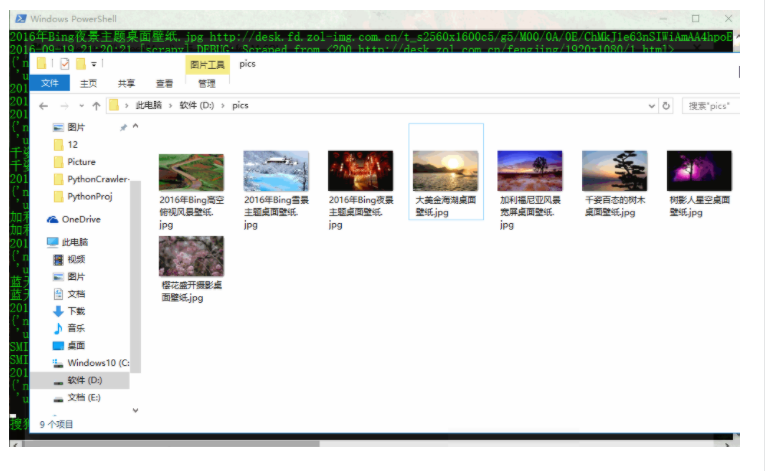
4 网络图片基本数据爬取 17
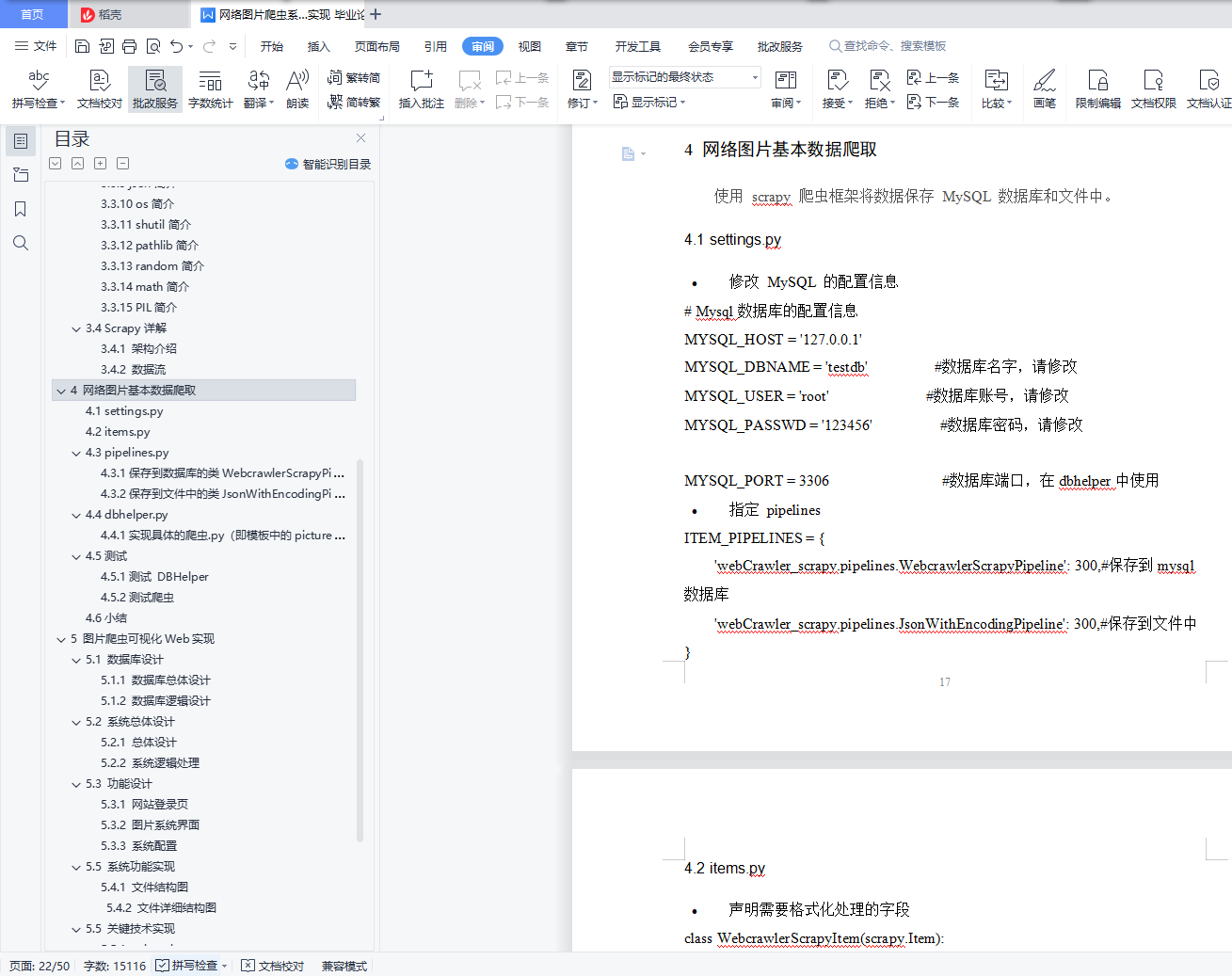
4.1 settings.py 17
4.2 items.py 18
4.3 pipelines.py 18
4.3.1保存到数据库的类 WebcrawlerScrapyPipeline(在 settings 中声明) 18
4.3.2保存到文件中的类 JsonWithEncodingPipeline(在 settings 中声明) 19
4.4 dbhelper.py 20
4.4.1实现具体的爬虫.py(即模板中的 pictureSpider_demo.py 文件) 21
4.5测试 22
4.5.1测试 DBHelper 22
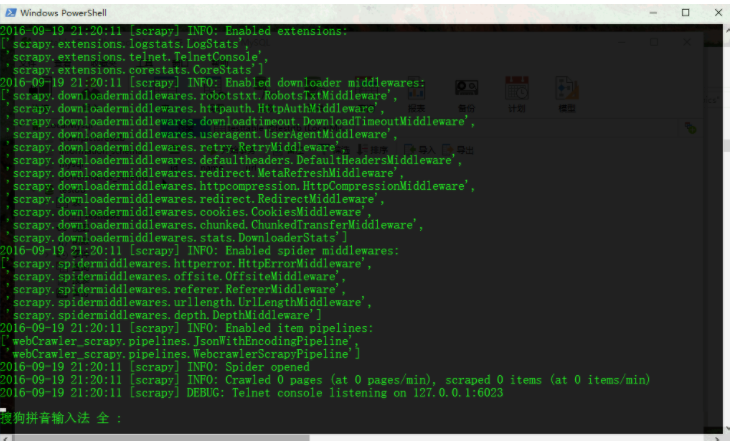
4.5.2测试爬虫 23
4.6小结 23
5 图片爬虫可视化Web实现 24
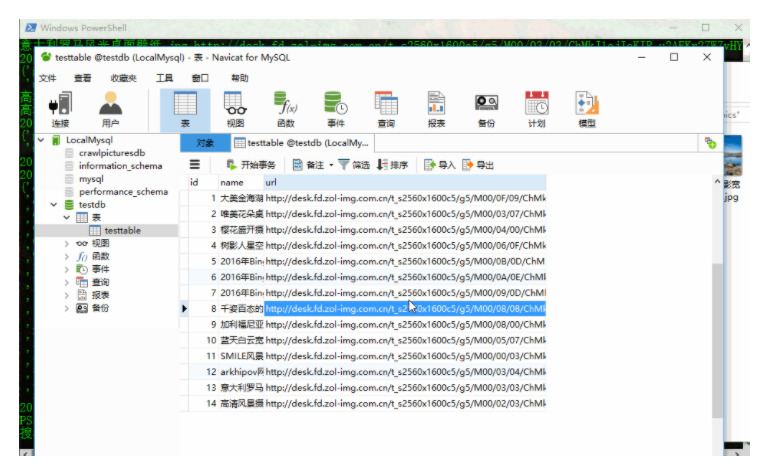
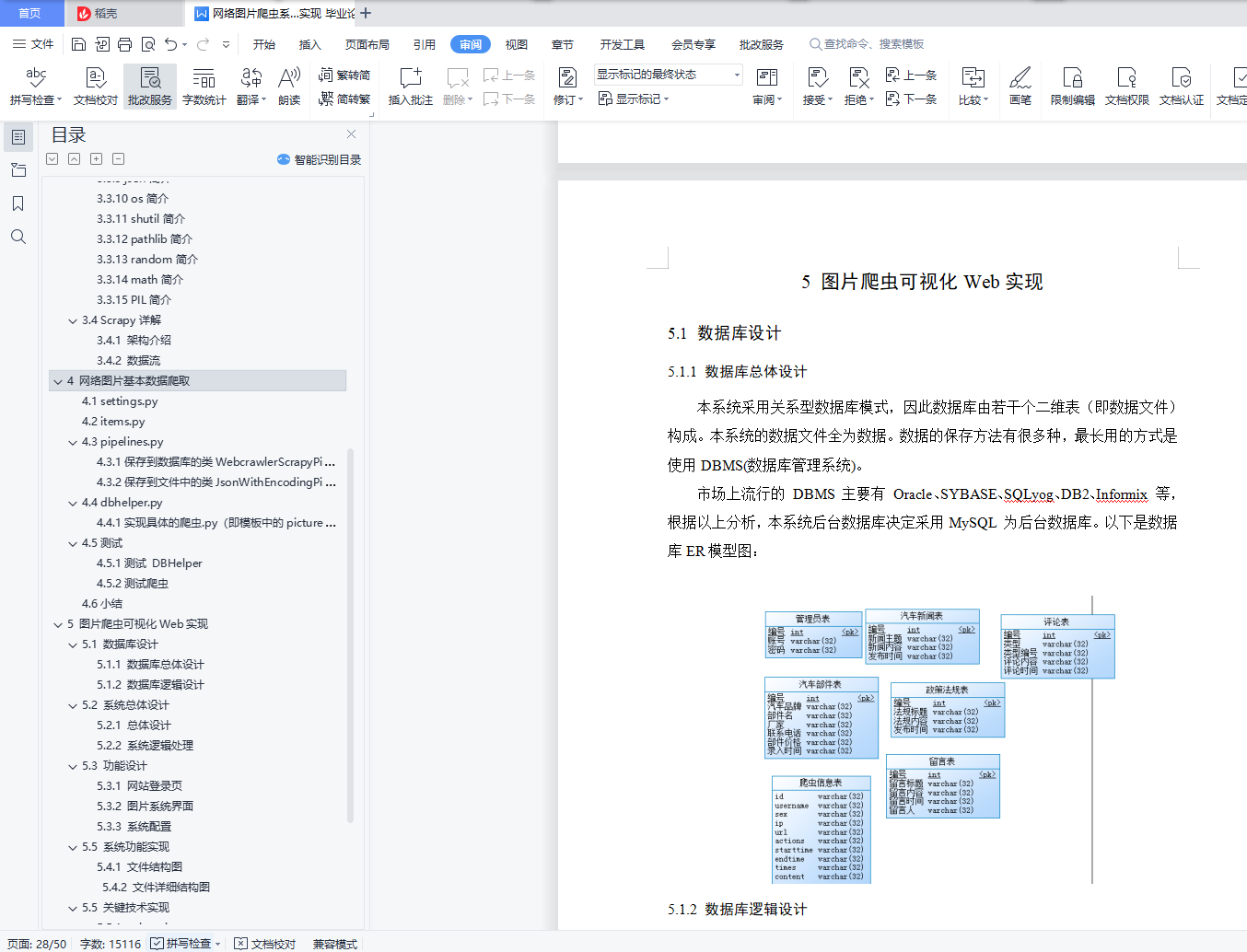
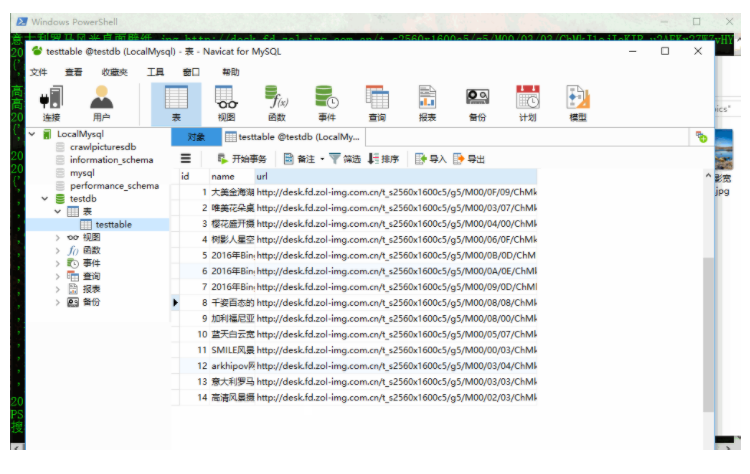
5.1 数据库设计 24
5.1.1 数据库总体设计 24
5.1.2 数据库逻辑设计 24
5.2 系统总体设计 27
5.2.1 总体设计 27
5.2.2 系统逻辑处理 28
5.3 功能设计 29
5.3.1 网站登录页 29
5.3.2 图片系统界面 29
5.3.3 系统配置 30
5.5 系统功能实现 32
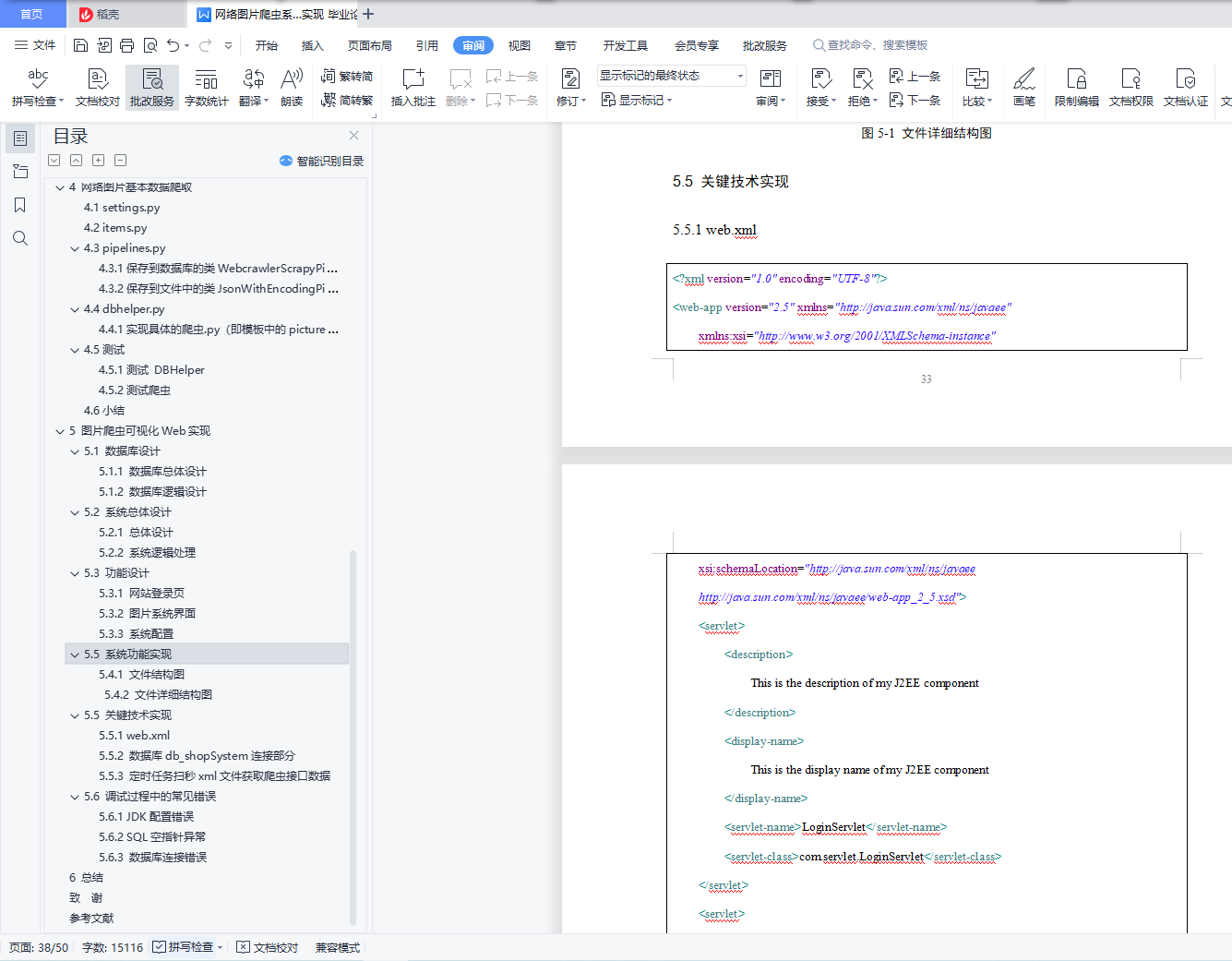
5.4.1 文件结构图 32
5.4.2 文件详细结构图 33
5.5 关键技术实现 33
5.5.1 web.xml 33
5.5.2 数据库db_shopSystem连接部分 37
5.5.3 定时任务扫秒xml文件获取爬虫接口数据 38
5.6 调试过程中的常见错误 40
5.6.1 JDK配置错误 40
5.6.2 SQL空指针异常 41
5.6.3 数据库连接错误 41
6 总结 42
致 谢 43
参考文献 44