�Ľ����û�Эͬ�����Ƽ��㷨�ĶԱ���ʵ��
ժҪ
���Ż��������ռ��ͷ�չ������Խ��Խ���ԴӺ�����Ϣ�л�ȡ�Լ�����Ҫ�ĸ��Ի���Ϣ���Ƽ�ϵͳ�IJ���ʹ�����������Խ������ͨ���û�����ʷ��Ϣ�ͷ�����Ϊ��Ϊ�û��Ƽ������û�����ĸ��Ի���Ϣ�����У�Эͬ�����Ƽ��������Ƽ�ϵͳ��Ӧ�����硢��㷺��Ҳ����Ϊ�ɹ��ļ���֮һ�����ĸ����Ƕ��ϣ����ţ��Ƽ�����˾��ʵ�������о��Ľ������û���Эͬ�����Ƽ��㷨�ĶԱ���ʵ�֡�
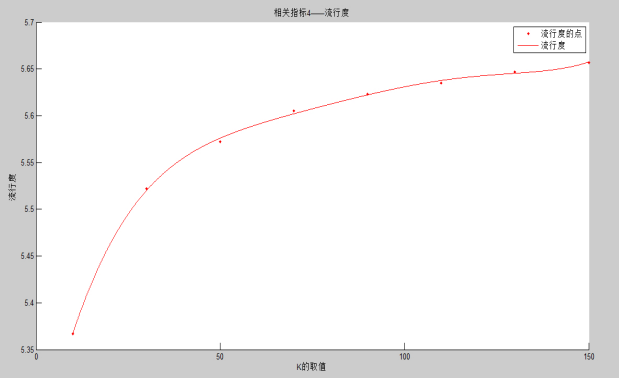
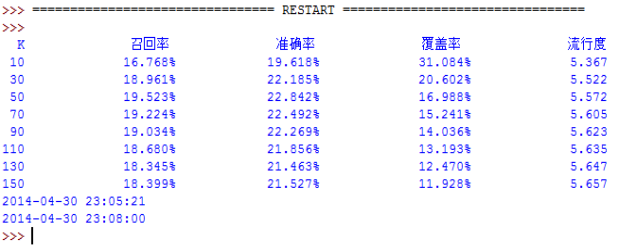
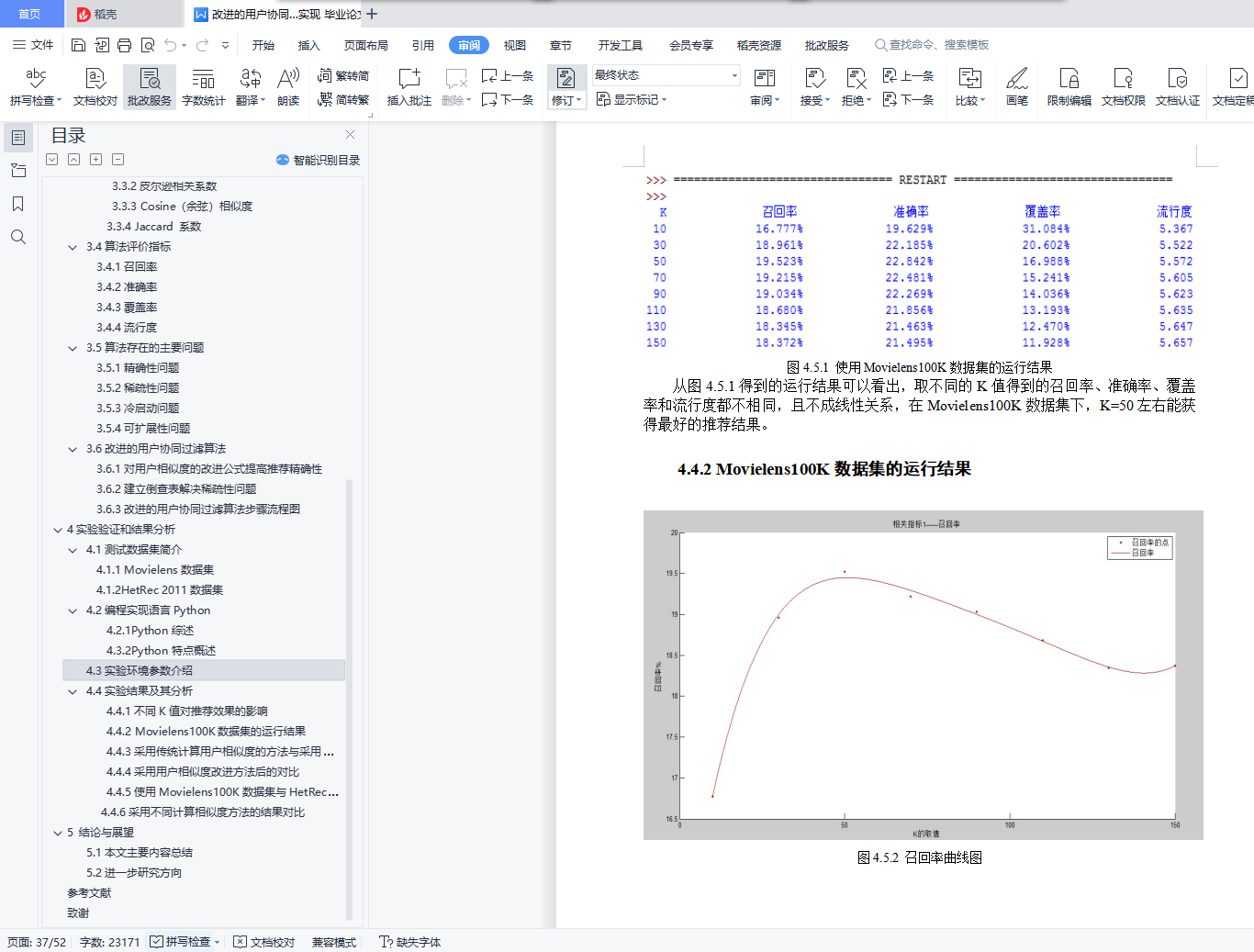
���ȣ��ڶ��㷨������������Ͳ����������ʵ�֣��������Ƽ��㷨���õ��ĸ�ָ�꣺�ٻ��ʡ�ȷ�ʡ������ʺ����жȶԽ�����з�������ʵ�ֹ����У��������������ƶȼ����û������ƶȣ�ʹ��Movielens100K���ݼ����ҵ��Ƽ�Ч�����ʱ��Kֵ�����������Ϊ50���ҡ�
��Σ����Эͬ�����Ƽ��㷨���ڵ�ϡ�������⣬���Ľ�����Ʒ-�û��ĵ������ֻ��������ͬ��������û�֮������ƶȣ������˴�ͳ���������û��������ƶȵĸ��ӹ�������������Լ10%������ʱ�䡣
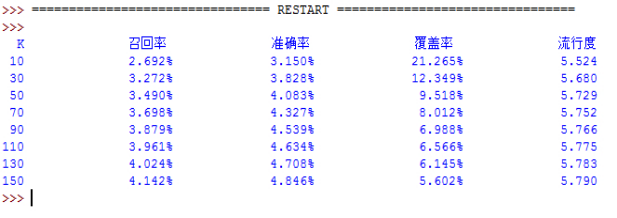
�ٴΣ����Ļ�����John S. Breese����Ľ��ۣ����á��ͷ����û���ͬ��Ȥ�б���������Ʒ���������ƶȵ�Ӱ����һ�������Ľ����û����ƶȵļ��㣬ͨ��Ϊ�˱�֤����ָ�겻�ǹ���ϵĽ��������ʮ�۽��淨���н�����֤��ʹ���ٻ�����ԭ�������19.523%������19.550%��ȷ�������22.842%������22.874%�������������31.084%������32.711%��
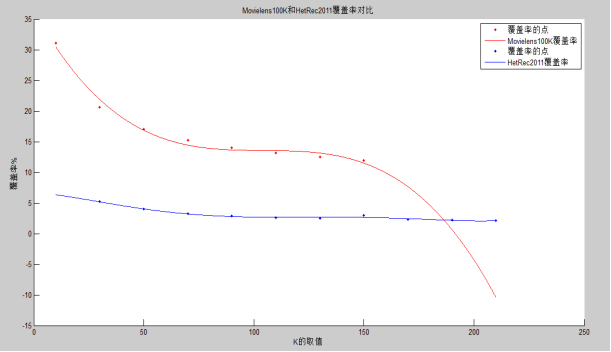
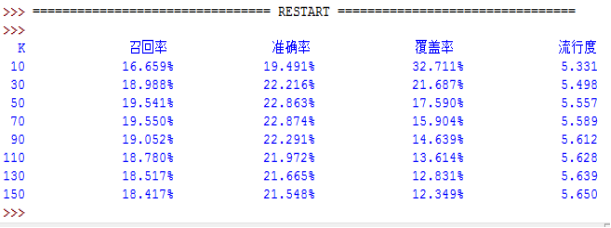
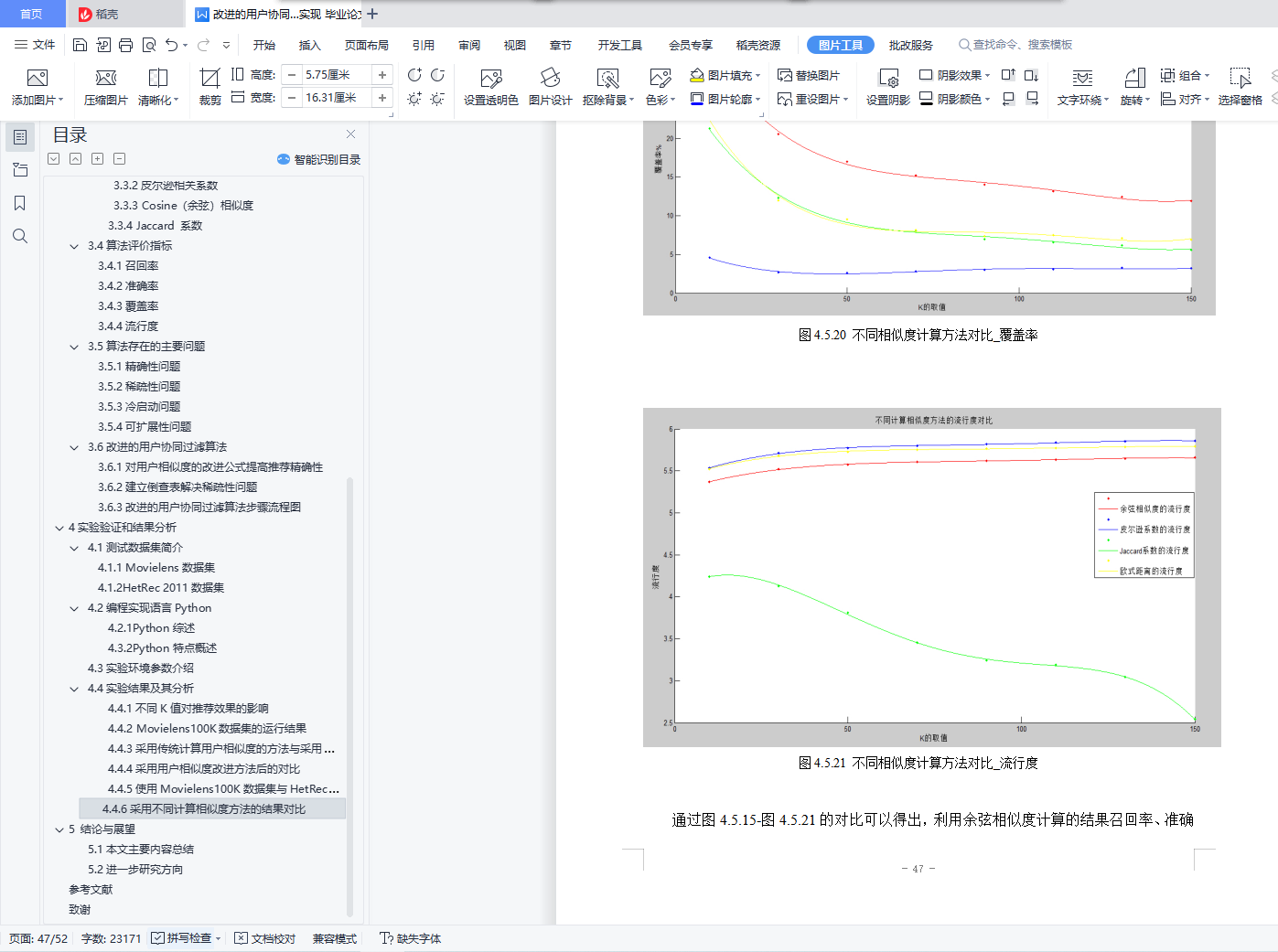
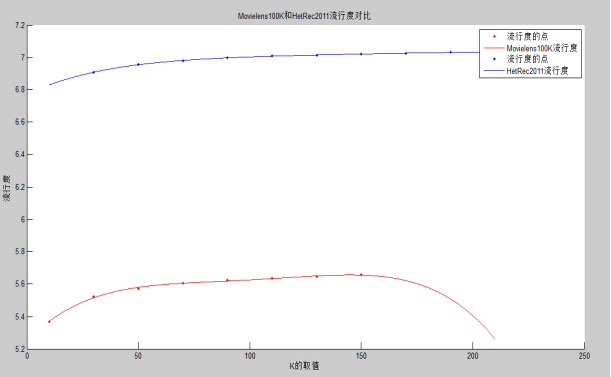
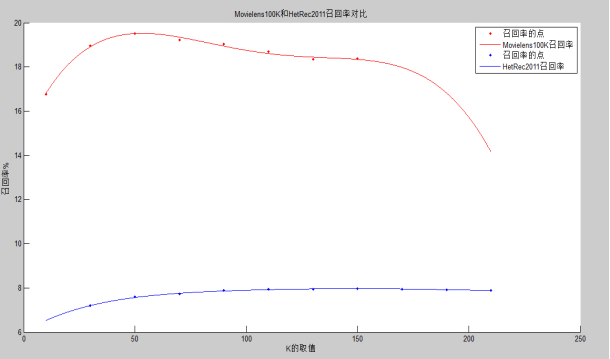
����ĶԱ�����������ͬ��ģ���ݼ�Movielens100K��HetRec 2011���ݼ��µ����н����ǰ���Ƽ�Ч����õ�KֵΪ50��������Ϊ150����ʵ���˼����û����ƶȵ�����������Jaccardϵ����ŷʽ���롢Ƥ��ѷϵ���������������ƶȷ������жԱȣ��ó��������ƶȷ��������������ƶ����Ľ��ۡ�
���Ľ��漰���Ƽ��㷨�������о�����һ����Ҫ�������Ľ��ġ����ڱ����ݼ���ʵ�ʵ�����������������֤֮����Ƽ��㷨������һ�����弴�õ�ģ�飬���ɵ������ܵ������������ۺϷ���ϵͳ���С�������ܵ����������ݷ���ƽ̨�ļ��ɲ��Ժ�ϵͳ���Ժ�Ͷ���Բ���Ӫ����ȡ����ᾭ��Ч�档
�ؼ���: �Ƽ��㷨��Эͬ���ˣ������û������������ϡ���ԣ�����������ƶȼ��㣻ʮ�۽��淨
Abstract
With the popularization and development of the Internet, people are becoming more and more difficult to obtain the personalized information they need from huge amounts of information. Recommendation system has solved this problem, and it recommends personalized information that meets users�� requirements referring to users�� historical information and access records. Collaborative filtering recommendation is one of the earliest and most widely used technologies. According to the actual demand of Yardi (Xiamen) science and technology co., LTD, this paper discusses the contrast and implementation of improved User based collaborative filtering recommendation algorithm.
First of all, the algorithm is implemented after the deep understanding and expounds of the algorithm. And the commonly used four indicators: recall ratio, accuracy, coverage and popularity are used to analysis the results. In the process, Cosine similarity was used to calculate the similarity of users, based on the Movielens100K data set, and the best recommend effect of K value (number of nearest neighbors) was about 50.
Secondly, aiming at the existing data sparseness of collaborative filtering recommendation algorithm, this paper establish items �C user inversion table, just calculate with the users similarity which users have same rating items. In this way, the complicated traditional method and calculation of users�� similarity was avoided, and about 10% run time was saved.
Moreover, according to John S. Breese��s conclusion (reduce the influence of hot items for users�� similarity), user similarity computing is improved. The recall ratio enhance from 19.523% to 19.523%, accuracy from 22.842% to 22.842%, coverage from 31.084% to 32.711%.
Finally, the results from two different scale data sets: Movielens100K and HetRec
2011 were compared. The former best recommend effect of K value is 50, while the latter is 150. Other methods of computing the user similarity (Jaccard coefficient, Euclidean distance, Pearson coefficient) were implemented, and compared with Cosine similarity, concluding Cosine similarity is more suitable for similarity measures.
As a module, there works finally integrated into the Intelligent Electronic Commerce Data Comprehensive Analysis System.
Keywords: recommendation algorithm, collaborative filtering, user based, K value, inversion table, similarity calculation
Ŀ¼
ժҪ - 2 -
Abstract - 3 -
1 ���� - 7 -
1.1����������� - 7 -
1.2�������о���״ - 9 -
1.3���ĵ����ݼ��ṹ - 10 -
1.3.1���ĵ���Ҫ���ݺ���֯�ṹ - 10 -
1.3.2���ĵĴ��µ� - 11 -
2 ����������Ի��Ƽ�ϵͳ - 12 -
2.1���������Ƽ�ϵͳ���� - 12 -
2.2���������Ƽ�ϵͳ�Ľṹ - 13 -
2.3���������Ƽ�ϵͳ������ - 15 -
2.4�Ƽ�ϵͳ���� - 16 -
2.4.1Эͬ�����Ƽ����� - 16 -
2.4.2�������ݵ��Ƽ����� - 17 -
2.4.3���ڹ���������Ƽ����� - 19 -
2.4.4����֪ʶ���Ƽ����� - 20 -
2.4.5����Ƽ����� - 20 -
2.4.6��Ҫ�Ƽ������Ա� - 20 -
3 �����û���Эͬ�����㷨����Ľ� - 21 -
3.1�㷨��� - 21 -
3.2�㷨���� - 23 -
3.3���ֳ��õļ������ƶȵķ��� - 24 -
3.3.1ŷ����£�ŷ�ϣ����� - 24 -
3.3.2Ƥ��ѷ���ϵ�� - 25 -
3.3.3 Cosine�����ң����ƶ� - 25 -
3.3.4 Jaccard ϵ�� - 26 -
3.4�㷨���ڵ���Ҫ���� - 26 -
3.5�Ľ����û�Эͬ�����㷨 - 27 -
4ʵ����֤�ͽ������ - 30 -
4.1�������ݼ���� - 30 -
4.2�㷨����ָ�� - 31 -
4.3���ʵ������Python - 32 -
4.3.1Python���� - 32 -
4.3.2Python�ص���� - 33 -
4.4ʵ�黷���������� - 34 -
4.5ʵ���� - 35 -
4.5.1��ͬKֵ���Ƽ�Ч����Ӱ�� - 35 -
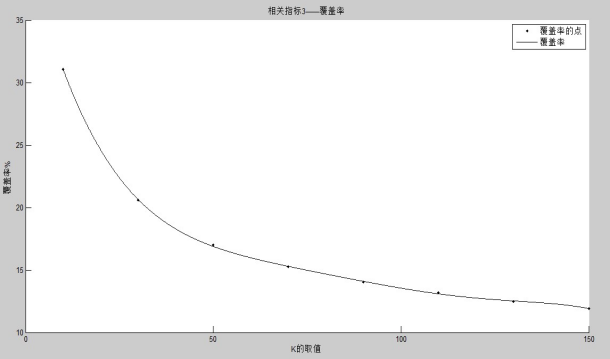
4.5.2 Movielens100K���ݼ������н��������Matlab����ͼ����� - 36 -
4.5.3���ô�ͳ�����û����ƶȵķ�������õ������������ʱ��ĶԱ� - 38 -
4.5.4�����û����ƶȸĽ�������ĶԱ� - 39 -
4.5.5ʹ��Movielens100K���ݼ���HetRec 2011���ݼ��Ա� - 39 -
4.5.6���ò�ͬ�������ƶȷ����Ľ���Աȣ�Jaccardϵ����ŷʽ���룬Ƥ��ѷϵ���� - 42 -
4.6ʵ�����ķ�����Ƚ����۽�� - 45 -
4.6.1��ͬKֵ���Ƽ�Ч����Ӱ�� - 45 -
4.6.2 Movielens100K���ݼ������н������ͼ - 45 -
4.6.3��ͳ�����û����ƶȵķ����뵹�����������ʱ��ĶԱ� - 45 -
4.6.4�����û����ƶȸĽ�������ĶԱ� - 46 -
4.6.5ʹ��Movielens100K���ݼ���HetRec 2011���ݼ��Ա� - 46 -
4.6.6���ò�ͬ�������ƶȷ����Ľ���Աȣ�Jaccardϵ����ŷʽ���룬Ƥ��ѷϵ���� - 46 -
5 ������չ�� - 47 -
5.1������Ҫ�����ܽ� - 47 -
5.2��һ���о����� - 47 -
����� - 48 -
��л - 50 -