目录
1. 背景 2
2. 小组人员分工 2
3. 文本分类定义 3
4. 模型算法 4
4.1 CNN 4
4.2 LSTM 7
5. 实验分析 9
5.1 数据集介绍 10
5.2 基准系统介绍 10
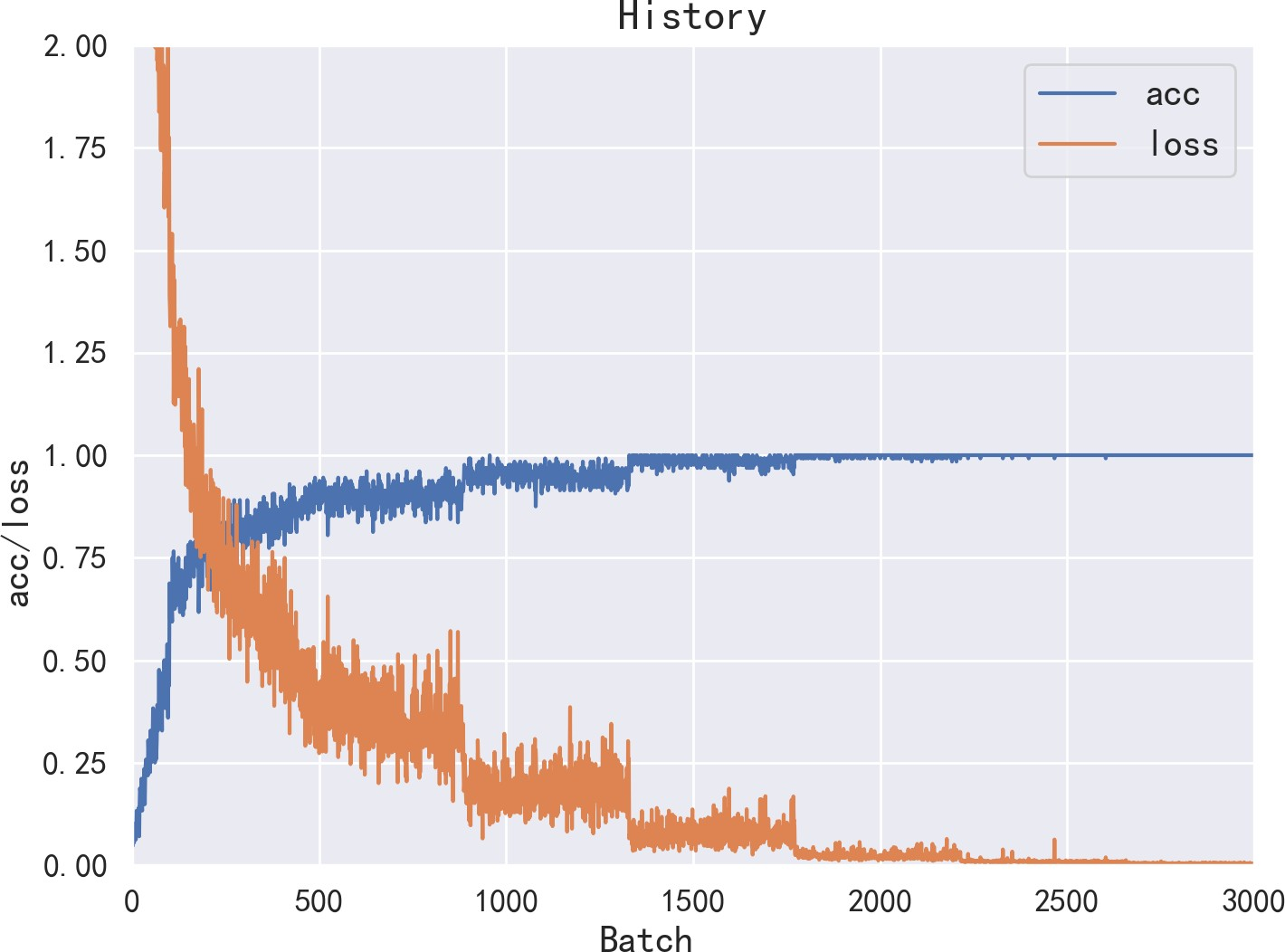
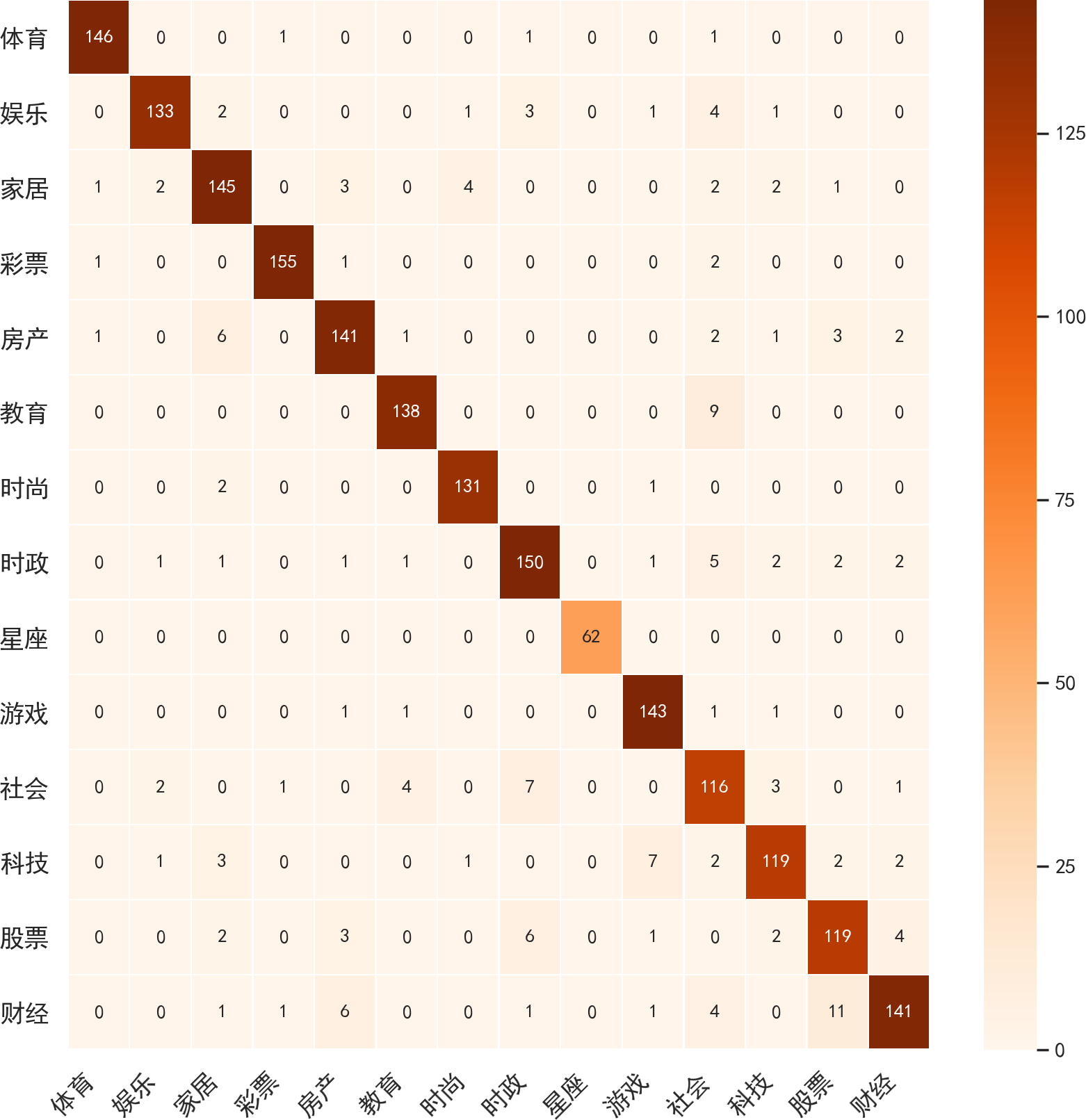
5.3 实验结果 10
5.3.1 CNN 10
5.3.2 LSTM 12
5.3.3 朴素贝叶斯 14
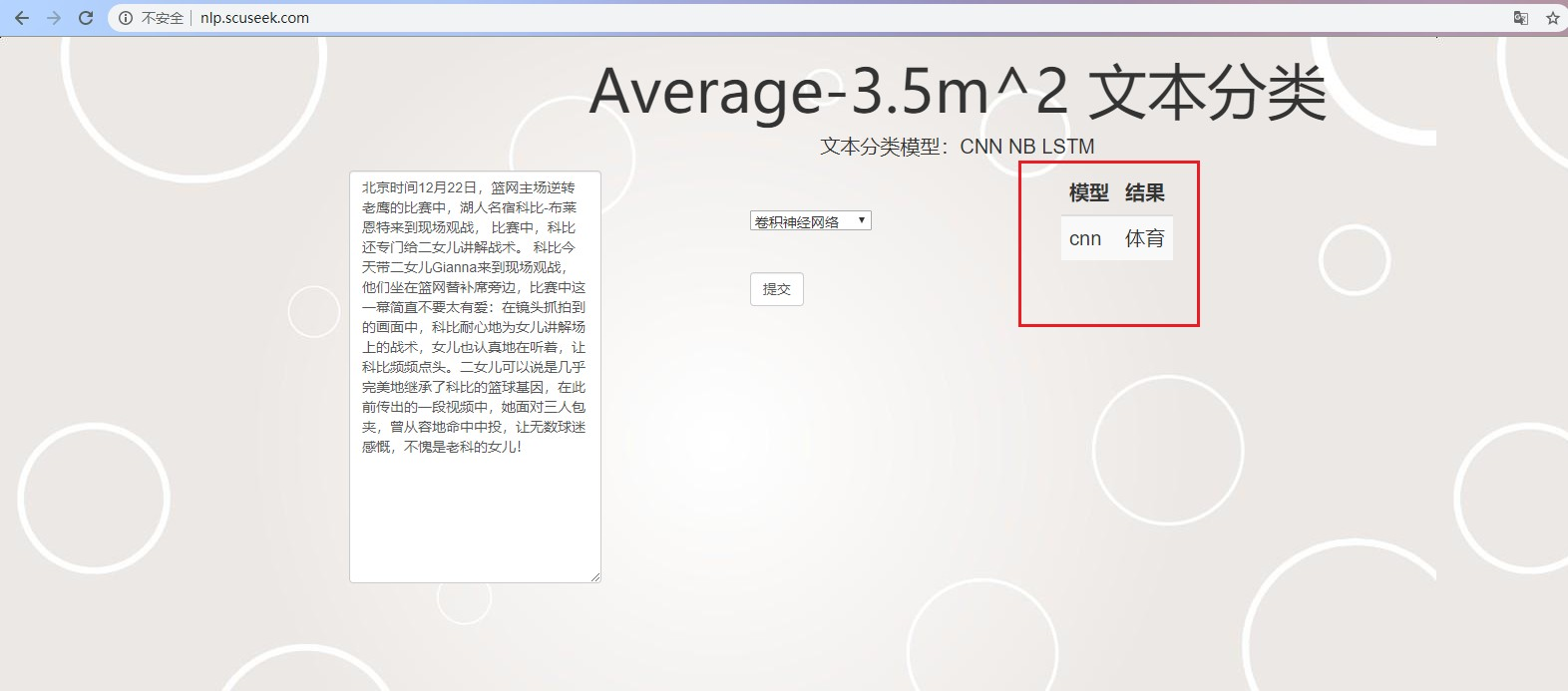
6. 部署与使用 15
6.1 环境要求 15
6.2 安装与部署 16
6.3 使用介绍 16
7. 总结 17
参考文献 17
1.背景
随着互联网的发展,网络中的数据和信息呈现指数级爆炸式增长。由于网络上电子文档越来越多, 如何对这些信息和数据进行自动有效地组织和管理是一个巨大的挑战,基于内容的信息检索和文本数 据挖掘渐渐成为了研究人员关注的领域。其中,文本分类技术近年来得到了广泛的关注和研究。文本分类是自然语言处理任务中的一项基础性工作,主要任务是在预先给定的类别标记 (label) 集合下,根据文本内容判定它的类别,目的是对文本资源进行整理和归类,同时文本分类也是解决文本信息过载问题的关键环节。随着技术的发展,文本分类已经在各个领域中落地和应用,比如:邮件分类、网页分类、文本索引、自动文摘、信息检索、信息推送、数字图书馆以及学习系统等。
本文实现了一个文本分类系统,通过深度学习,朴素贝叶斯、支持向量机等模型实现文本分类,实验表明基于深度学习的方法得到的效果最好。最后,通过 Web 的形式进行展示。
本文的组织结构如下:
1.第 1 章介绍了本项目的背景;
2.第 2 章介绍了小组成员信息以及人员分工;
3.第 3 章介绍了文本分类的任务定义;
4.第 4 章介绍了文本分类系统的系统架构,系统中相关模型、算法的设计与实现;
5.第 5 章介绍了模型的实验,包括数据集、基准系统的介绍,并对实验的结果进行比较和分析;
6.第 6 章介绍了文本分类系统的环境要求、系统部署以及使用的方法;
7.第 7 章进行概括性的总结;
2.小组人员分工
本次项目的小组人员分工如表1所示。项目的任务分配和管理主要由组长同学负责,各位组员都负责了文本分类模型的搭建以及评估,包括 CNN 模型,LSTM 模型,朴素贝叶斯等,具体的内容见表1,同学负责了本系统中的 Web 的搭建以及前端展示的设计,并且,文档各个部分由各位同学撰写,最终由同学进行整合。