新技术在 Visual Question Answering中的应用
摘要
Visual Question Answer (VQA) 是对视觉图像的自然语言问答,作为视觉理解 (Visual Understanding) 的一个研究方向,连接着视觉和语言。问题的格式是给定一张图片,并提出关于这张图片的问题,获得该问题的回答。
使用了BOW词袋模型和Word To Vector单词矩阵化的技术来分别处理label和输入的单词向量,及LSTM网络和Attention机制,VIS+LSTM网络结构,搭建了VQA问题的新模型。在我们的模型中,拥有3个LSTM网络分别处理:文本,图像,文本和图像。在可视化输出结果中,正确回答在Top5回答中的可能性很高。
关键词: BOW Word To Vector LSTM Attention VIS+LSTM VQA
目录
1 问题说明 1
1.1 问题背景 1
2 问题分析 1
3 猜想 1
4 模型的建立 1
4.1 模型概述 3
4.1.1 数据集的使用 3
4.2 VGG19模型 3
4.2.1 VGG19 效果分析 3
4.2.2 VGG19 参数分析 3
4.3 LSTM 模型 3
4.3.1 LSTM 效果分析 3
4.3.2 LSTM 参数分析 3
4.4 Word To Vector 模型 3
4.4.1 Word To Vector 效果分析 3
4.5 综合模型分析 4
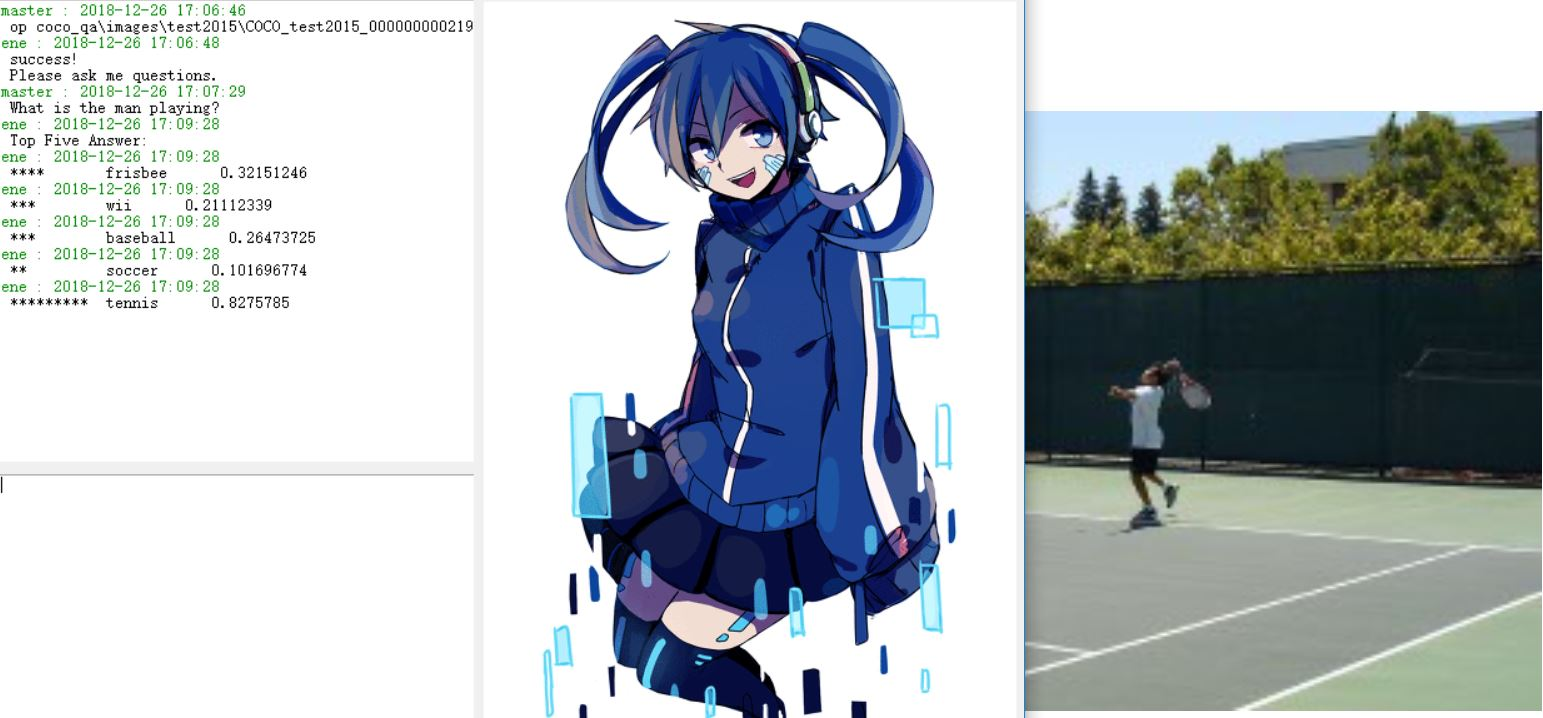
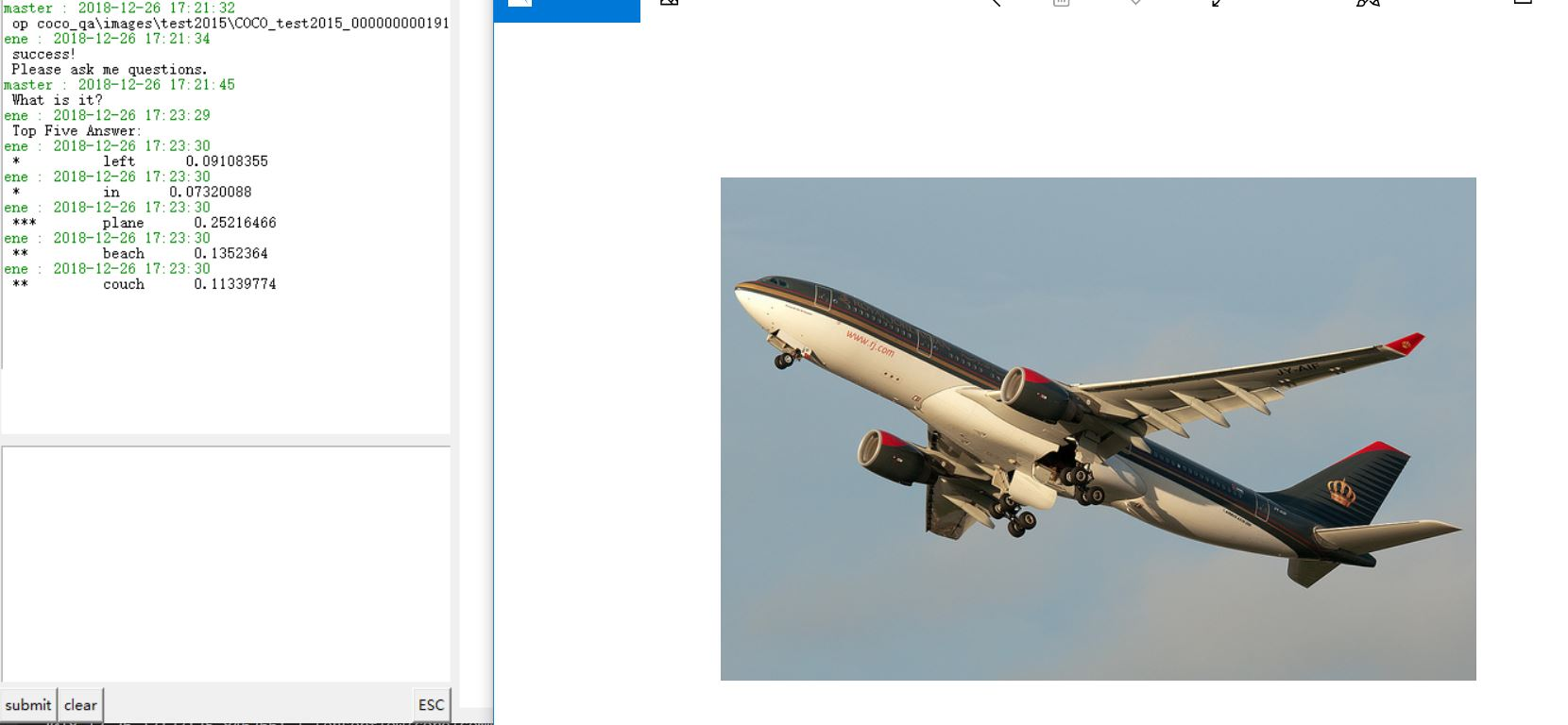
5 模型的效果 4
6 模型的提升 5
引用 6
1 问题说明
1.1问题背景
Visual Question Answer (VQA) 是对视觉图像的自然语言问答,作为视觉理解 (Visual Understanding) 的一个研究方向,连接着视觉和语言,模型需要在理解图像的基础上,根据具体的问题然后做出回答。
随着深度学习的不断发展,我们对于VQA问题的解答也有了飞跃。从早期的VIS+LSTM模型[1]和它的变种VIS+双向LSTM网络,到目前兴起的attention机制[2],还有诸如外链知识库和Word To Vector的发展,无疑都大大推动了我们的研究。本文将使用包括但不仅仅是以上的几种思路,设计我们自己的VQA模型,其中的创新之处在于,我们同时运用了多种新技术,使用了在不同维度上的感受器分别感受空间和实体,并将其巧妙地融合在一起。
2 问题分析
解决VQA问题需要NLP+CV的共同合作才能完成,因此我们的主体框架仍然紧紧围绕视觉感知+自然语言处理的方向。
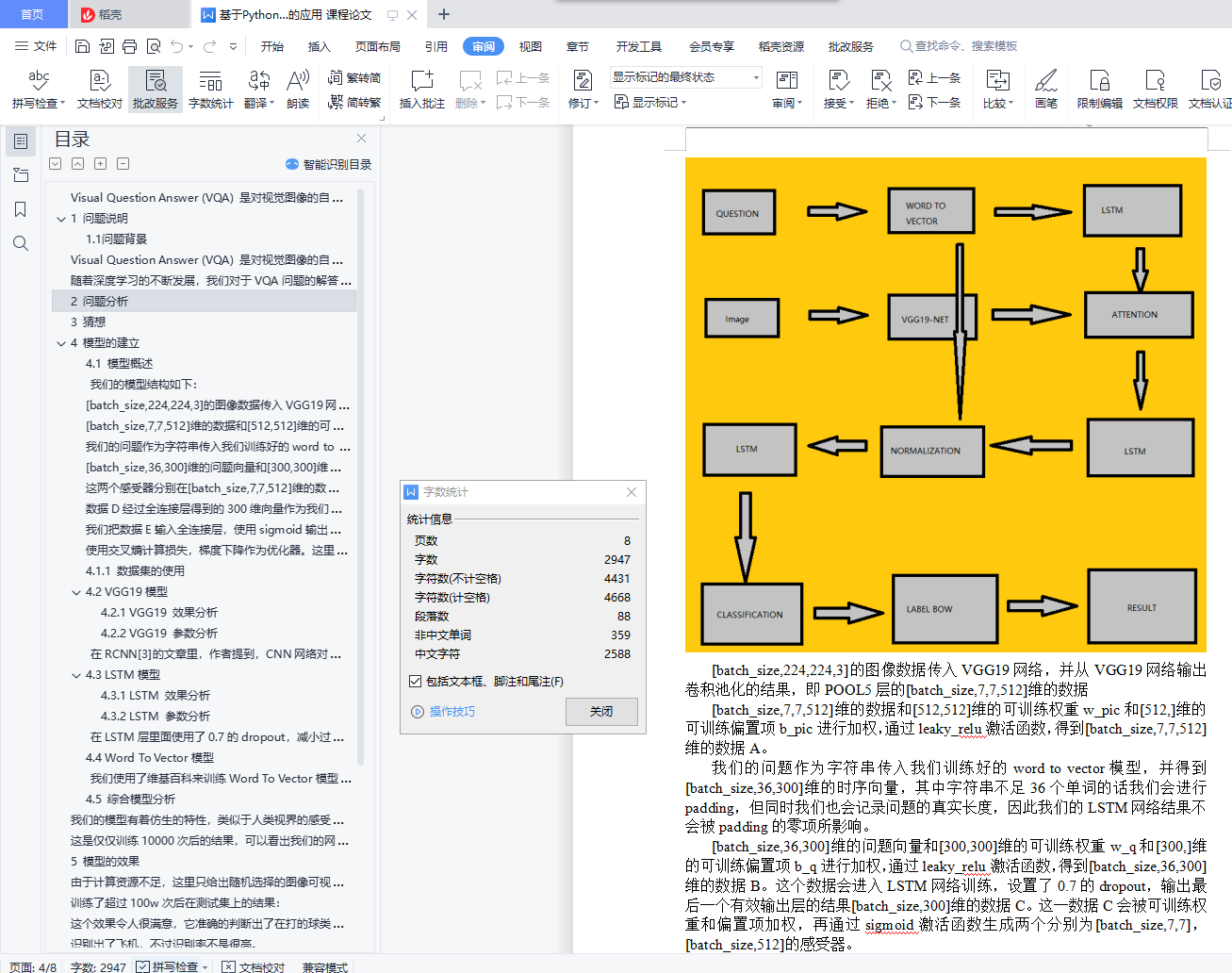
其中,我们使用一个训练好的VGG19网络作为视觉感受器,并使用LSTM网络处理我们的问题。在LSTM处理之前,我们会使用Word To Vector的模型,使用维基百科的句子训练词向量,并建立字典,将每个英文单词映射到一个300维的向量空间。
我们目前拥有的数据集是一个非常大型的数据集COCO-QA,它的训练集有80000多张图片,测试集有80000多张图片,验证集也有40000多张图片,每张图片有数量不等的问题,每个问题有10个回答,并且标注了每个回答的信心程度。
3 猜想
我们猜想LSTM网络最后一个输出层的结果包含的问题的信息可以很好地生成空间感受器和类别感受器,用于给图像加入attention机制。这个attention我们加载到了图像进入VGG19网络后输出的第一个全连接层前面的那个池化层上。我们希望这两个感受器能够感受到我们想要的物品和空间位置信息。