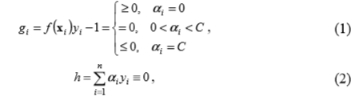ʹ������ͼ���������Ӧ����֧���������ij�������:
����������е�Ӧ��
ժҪ����ͼ����������У����������ı仯������ƹ⡢�����λ�õȻ�����Ӱ��֧����������SVM���������ı��֡����磬֧��������ʹ�ð����ȡ��ͼ�������ڷ���ʱ����ֲ��ѱ���ҹ���������Ƭ���ڱ����У������о����ڲ�ͬ�ij�������������ѧϰ�����Ч������֧����������ͬһͼ����з��ࡣһ������Ӧ֧���������������㷨��������������Ӧ���ڵ��������������仯������������⣬�������λ�úͰ�������ϻ�ȡ������ͼ��ķ��ࡣͨ������ѵ������˷���֧�����������ܡ�
1.����
֧����������SVM������Чѵ��ͨ����Ҫ������ѵ����Դѵ�����ݼ���Ȼ����Ϊ֧��������ѧϰ�ռ����ݼ���Ҫ������ʱ����Ҫ�������Դ��һ��ѵ���ã�SVM�������Ͳ�����Ӧ�õ��Ӳ�ͬ�����»�õ������ݼ�����������ͬһ���⡣Ϊ�����磬��ͼ����������У����������ı仯�����������������λ�õȶ���Է������ǿ��Ӱ�쾭��ѵ����֧��������������ʹ����Щ�������IJ�����Ӿ�����ս�Եġ����磬���ǴӰ�װ����Ϊ���ܽ�ͨϵͳ��ITS����ɲ��ֵĹ�·���·�����������������Ұ�ڵ��������м�������Ĵ��ڡ������������⣬����Կ�ʼ��һ������������ռ�ͼ����ȡ����Щͼ����ѵ�����ݼ�����Ϊ�������ѵ��֧��������������ѵ����֧���������ܹ��ܺõش������л�õ�ͼ���������Ȼ����������������������ͼ��һ��ʹ��ʱ������ѵ�������ڳ��������IJ�ͬ�������������ܿ��ܺܲ���ͬ���ĵ�����֧��������Ҳ����ʹ�ð����ȡ��ͼ�����ѵ����Ȼ��Ӧ�ö�ҹ�������ͼ����з��ࡣ�����������һ���취��Ϊÿ�������ͼ��ѵ��֧��������������������ܷdz�������Ҫ������Դ��������Ҫ������ʱ�䡣��ˣ�����Ľ���������ܹ�ʹ�����еĴ��ͼ���ѵ�����ݼ��Գ���ѵ��֧����������ʹ����Ӧ�µ�ʹ�����������ĸ���ѵ���������������漰�����ӳ�ʼѵ����ѧϰ����֪ʶת�Ƶ��µĻ����С����������ת��ѧϰ�������йأ�����[1-3]�������ܵ������ص��Ǵ���ͬ�µĹ���[3]�����������һ���µ�ת��ѧϰ��������û�ʹ�������������±�������Լ������ľ����ݹ����������ķ���ģ�������ݵ����������Ե���ѵ��ģ�͡���͵�����[4] ������ʹ�ø�������Դ��Щ����Դ���Ժܷḻ�����ǵ����������֧���������ľ��ȡ�ʹ��δ��ǵ����ݸĽ�Raina����[5]Ҳ����˼ලѧϰ����ļ�Ч���ڱ����У������о���ʹ������֧��������[6-7]���Ľ���ͬ����������ͬһ��ͼ��ķ��ࡣ���Ǽ������һ�����Կ���Ϊ��ʼѵ�������ĵ������������ѵ��������������֧�����������г�ʼѵ����һ���DZ������������¼�ơ���������Լ��ѵ��һ�ǣ���Թ��ϵ�֧��ʩ����һЩ����Լ��ѵ��ѧϰ�����е���������ѵ��SVMͨ����ʹ����������ͼ������ת��ѧϰ�Ρ�ʹ�õ��㷨����ϸ˵������һ�ڡ������ǵ�ʵ���У�����ʹ���˴������������ͼ��פ�����ձ�����Ҫ��·���ٹ�·�ϡ�������������ȡ��������·�����䷽���ݶ�ֱ��ͼ��HOG��[3]����ġ�Ȼ������HOG������Ϊ֧��������ѧϰ��ѵ��������
2.���Ϻͷ���
�ڱ����У��������ȼ�Ҫ�����˱�����֧���������ӽ�����Լ��ѵ������Լ��ѵ��������������һС�ں�����������ѵ����
2.1�绰��ջ
����֧��������[6-7]ѧϰͨ��һ��ѵ������Ż�����һ��������������ʹ������ѵ��������������ģʽ���ϡ��Ѿ�����˼��ַ���������Щ�������ֻ�ṩ���ƽ�[9-10]��2001�꣬����֧���������ľ�ȷ������Cauwenberghs��Poggio�����CP��[6]����CP�㷨�У�Kuhn-������ǰ������ѵ�������ϵ�Tucker��KT�������ڡ����ȡ���⼯������������
���������f��x��=�Ʀ�i yiK��xi��x��+b������ѷ���i=1������ѵ������ϯ����Ӧ�ı�ǩY=��1��KT�������Ա�д�ɣ����[1]��
��C��������ʱ����i��չ��ϵ��������bƫ����������������Ч�ؽ�ѵ��������Ϊ�����飬����Ե֧��������gi=0��������֧��������gi<0���ͷ�֧��������gi>0����
��CP�㷨�У�һ���µ�ѵ������ͨ�����Ƚ����ֵ����Ϊ0��Ȼ��ʹ�ù�ʽ��1��������gֵ������ǵĻ�����0�����µ�ѵ�������Ƿ�֧�������������Ǵ����DZ�Ҫ�ġ�������ǣ���ѵ�������Ǵ���������֧���������������ֵΪ0�ij�ʼ������Ч����ֵ�ǵݹ�ص�����������ֵ��ͬʱ����KT�������������ϵ�����������������У�ʹ��ԭCP�㷨����ѵ������Ϊ��Լ����Լ��ѵ����ȵ�ѵ���������������ۡ�����Ҳʹ�ô��㷨���ڲ�ʵ�֣�ʹ��C֧������֧��������ѧϰ��
2.3������ѵ��
��Լ��ѵ���У�ֻ�����Գ�ʼѵ����X��������ѵ����Ŀ�꼯Z����������������ѵ�����С���������ѵ����ѵ����֧��������ʹ�����������������Ʒ����ͼ22.2������˼����SVM�Ѿ�ʹ�����ݼ�������ѵ��ͨ����Լ����Լ��ѵ����������������ѵ���������ݼ�Z�е����������ϲ���ѵ�����֧��������������Ӧ���µ����ݼ�������ת��ѧϰ�Ρ����յĽ����֧����������һ���������������е�Ӧ����Ŀ�����ݼ�Z��ʾ.
ͼ2:��������ѵ���Ļ����ϣ�������Լ����Լ���ķ����Գ�ʼѵ��������ѵ����Ȼ����������֧����������Ŀ�꼯������ѵ��
2.2Լ��ѵ��
����������һ����ʼѵ���������ΪX={��x1��y1������x2��y2����K����xn��yn��}����n�ܴ������ǵ������У�ѵ������ϯ����HOG�������������Ը��������ͼ����ǩy�����ҡ��г�����1����������0����ͬ������Z={��z1��y1������z2��y2����K����zm��ym��}��ʾ��һ�����ݼ�������һ���������m<<n�����Ƕ�����Լ��ѵ����X��ѡ���ʵ���֧����������ʹ�����ݼ�ZΪ���Լ���֧���������������ܡ�Ӧ��ע�����X��֧��������һ������Z�����ŷ��ཫ��ʾ�ڽ���С����ǣ����ܴ���X��һ���Ӽ��ɵ���Z����ѷ�����������ҵ����Ӽ���Ŀ����Լ��ѵ����
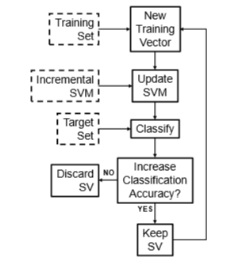
ͼ1����������֧����������Լ��ѵ����1����ѵ����X.2��ʹ�����������������е�֧����������3�� ���Ը���֧��������ʹ��Ŀ�����ݼ�Z.4��������ྫ����ߣ�����֧��������SV��������������5�� �ظ���1��ֱ����������ѵ��������
�м��ַ�������ʵ��Լ��ѵ����һ�������Ǵ�X�������ȡ�Ӽ���ʹ����Щ�Ӽ�ѵ��SVM��Ȼ��ѡ�������Z�������ྫ�ȵ��Ӽ�����֧��������������ͼ1��ʾ���㷨���㷨�ӷ�Լ�������ʼ�����˸���Լ��������ʾ��������ÿ���µ�ѵ������ʱ��ʹ��ִ��Ŀ�����ݼ�����������е�Z�����¼����֧����������������˷��࣬�������������н⼯�н���֧����������ȷ�ԣ�����֧�������ή�ͷ��ྫ�ȱ����������㷨ȷ��ֻ֧���������Ŀ�꼯���ྫ�ȵ�֧��������������Ч�����µ�����X�ķ��뺯�����Ը���һ�����ŵĴ�Z������Ʒ����ʹ�ú��ߵ��κ���Ʒ�����һ��֧��������X�������Ӽ���
2.3������ѵ��
��Լ��ѵ���У�ֻ�����Գ�ʼѵ����X��������ѵ����Ŀ�꼯Z����������������ѵ�����С���������ѵ����ѵ����֧��������ʹ�����������������Ʒ����ͼ2������˼����SVM�Ѿ�ʹ�����ݼ�������ѵ��ͨ����Լ����Լ��ѵ����������������ѵ���������ݼ�Z�е����������ϲ���ѵ�����֧��������������Ӧ���µ����ݼ�������ת��ѧϰ�Ρ����յĽ����֧����������һ���������������е�Ӧ����Ŀ�����ݼ�Z��ʾ��
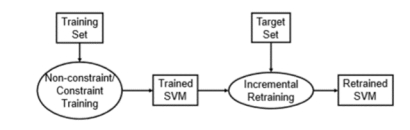
ͼ2����������ѵ���Ļ����ϣ�������Լ����Լ���ķ����Գ�ʼѵ��������ѵ����Ȼ����������֧����������Ŀ�꼯������ѵ��
3.����
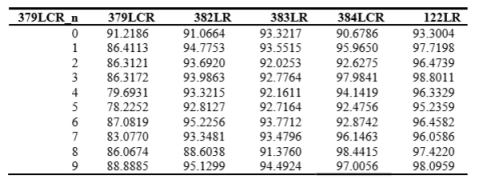
���ձ���Ҫ��·���ߵ������ͬ�ص㰲װ����̨���������������������ͼ����ÿ�����ͼ��16 x 16 sub-����������û��������ͼ����ȡ��������Щѡ����ͼ��ʹ�þ���4�������ص���8 x 8�ص���ת��ΪHOG�����ܹ�9��������ÿ��������ݶȷ����Ϊ8����Ч�ؽ�ÿ��16��16ͼ��ת��Ϊ72ά�����������ɴ��γ��������ݼ�����������£�379LCR��58453������������382LR��56405������������383LR��50058������������122LR��12762��������������384LCR��61214��������������379LCR��382LR��383LR��ͼ�����ڰ�������ģ�����122LR��384LCR��ҹ���á�Ȼ��ÿ�����ݼ��ֳ�10���Ӽ�������ÿ���Ӽ�����ѵ��һ��֧����������Ȼ��ʹ����һ�����в����Ӽ�������֧���������ˣ������ԡ�����ʽ��RBF�ͣ���״�ˣ�����صĺ˲�������һ��ʮ����ѡ��IJ����ռ�����������֤������ÿ���Ӽ������в�ͬ�����ź˺ͺ˲����������ǵĵ�һ��ʵ���У������о���֧���������ķ�������ʹ����Լ������ѵ�������ڷ���ʹ�����ڶ�ͬһ��������������磬ʹ����һ��ʹ��379LCR_0ѵ����֧������������379LCR_n������n=1������9�����ǻ������˿������ʹ�ô�һ������ѵ����SVM�����ݽ��з����������һ�顣
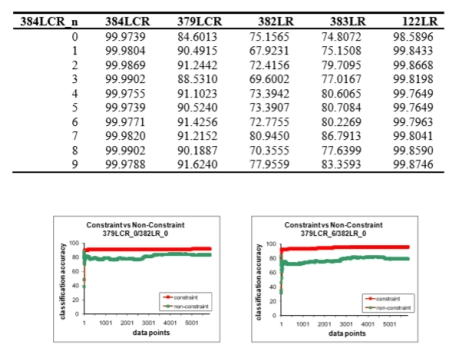
��֧ͬ���������ķ�������384LCR���1��ʾ����һ�б�ʾ����ѵ��֧������������������ʾ���ྫ�ȡ��ڶ����������ڷ���Ľ��������3��6�ǿ������Ľ�����������ڷ��࣬����ȷ����������99%��ͬ���ı��ֿ���˵����δ��ʾ���������ݼ�����һ���棬����ı��ַ������������Լ������ݼ����졣����ijЩ���ݼ����ܿ��Ըߴ�99%�����磬��1����6�У��������������ˣ�����Ե���70%�����1��4�У�������384LCR��֧���������ǽϲ�ķ���������382LR��383LR�������ռ����ݼ��������ڶ�379LCR���ռ����ݼ�����122LR��ҹ�����ݼ�������
���ࡣ
��1��384LCR�Ӽ�ѵ��֧���������ķ��ྫ��
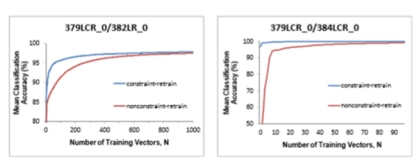
ͼ3��Լ������ɫͼ���ͷ�Լ������ɫͼ���ڼ�ķ��ྫ�����źϲ��������������Ӷ����е���ѵ������������У�ʹ����382LR_0��ΪĿ��/���Լ�����379LCR_0����379LCR_6���ң���Ϊѵ����
����һ��ʵ���У������о����Ƿ��п��ܸ��ƽ���ʹ��Լ��ѵ��������ྫ�ȡ����ǻ��Ƚ���ʮ��Լ��������Լ�����ľ�������ѧϰ�е�����ࡣ�����ͼ33��ʾ��Ϊ����Լ��ѵ����Ŀ�꼯�ķ��ྫ����֧���������������ӡ�����ʾ������������ɫͼ�С���ΪԼ��ѵ��ֻ���ǿ�������Ŀ�꼯�ķ��ྫ�ȣ��Ժ�ɫ��ʾ��ͼ���������ӡ���Ȥ���ǣ�ʹ��Լ��ѵ���ķ��ྫ�ȳ����˼�ʹ�������������Ҳ����Լ���ġ�ͨ����ѧϰ�����У�����֧����������ΪĿ�꼯�����������ܵõ��˺ܴ�ĸ��ơ�
��2��Լ��ѵ��֧���������ķ��ྫ��379LCR��Ϊѵ������382LR U 0��ΪĿ�꼯
��3��������ѵ���ķ���ȷ�ʣ�%�������379LCR���Ӽ�������ѵ������384lr0������Ŀ�꼯
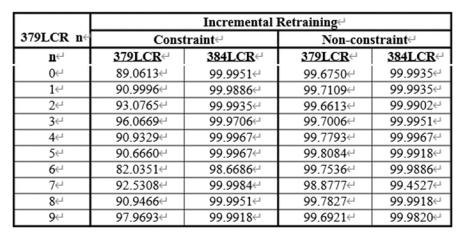
��2��ʾ�˴�Լ����ѵ��֧���������ķ������ܡ����Թ۲쵽����Ӱ�졣����Ԥ�ڵ���������������ȷ��һ������£����ǵ��������ݼ��������ӡ���Ŀ����˵����������ݼ����ڱ�������382LR�����������10%���ң���3��������һ���棬�����ڲ�Ҳ���Թ۲���ྫ�ȣ���2����������������֮�е�����Լ��ѵ����Ϊ���Ż�Ŀ�꼯�ķ������Ƶģ�����ܲ��ᵼ��ԭʼѵ���������Ž⡣����������ʹ��������ѵ������������������Ŀ�꽫���ݼ�����ѵ�������У�������������SVM��ʹ����Լ����Լ���������г�ʼ��ѵ�������˵��顣��������ڱ�333�С�����Ӽ�379LCR��Ϊ��ʼѵ�������õ���svm�ǵ�����ʹ��384LR_0����ѵ����ͨ��������ѵ�������ྫ��Ŀ�����ݼ���384LCR������99%���ϣ�����һ�������ĸĽ���������������ȡ����⣬������Լ����ʼѵ������ʼѵ�����ݼ��ķ��ྫ�ȣ�379LCR����Ȼ�ܸߡ��������������ѵ�ڼ䣬���Ƕ�ÿ���˽����˷����������֧���������ķ�չ����������֧����������������ذѶ���ϴ���˶����ѵ�����������뵽ѵ�������У�������������ƽ��ֵ������ͼ��ͼ4��ʾ����������ʾ�����ʹ��379LCR_0��Ȼ��ʹ��382LR_0����������ѵ������һ���棬384LCR_0����������������ѵ��������嶼��ʾ��ʼѵ����Լ����������ͼ��ʹѵ�����֧����������Ӧ��ʹ�ó�ʼѵ������Լ��������������������£�ֻ������Ϊ��ʹ֧����������Ӧ�µ����ݼ�����ҪĿ��������
4.����
֧�������������ѵ�������ݼ���³�����������Ի�ȡ��ʼ���ݼ���ijЩ�����ĸ��Ŀ�������Ӱ������������ܡ�Ŀǰ���ڿ��ǵİ����ǴӰ�װ����Ҫ��·�ϵ�����ͷ�м��ͼ���е��������ӽ����������ͬ�ص������������ͬ����Ӱ���ʹ�����ݼ�ѵ����֧���������ķ������ܴ�һ��λ�ã�����1�������ڲ�����Щ��������Ϊÿ��λ��ѵ��һ��֧�����������Ի����������С�Ͳ�������ơ������ڴ��ģӦ�ã�������Ƿdz��ɱ��߰�����Ҫ������Դ�����Һ�ʱ�ϳ�����ˣ�����ʵ�ʡ��ڱ����У�����չʾ��һ�ֿ˷���һ�����ʵ�÷������ơ��÷���Ҫ�����ݼ��ij�ʼ���ϣ����������ṩ������ͷ�������µIJ��������Ŀ�������ͼ��Ȼ��ʹ�ø�ͼ��ʹ���з�������Ӧ�µ�ͨ��ת��ѧϰ�ij�����������Ϊ�÷�����������֧����������Ҳ����������ѧϰ��һ����뷨�Ǵ�һ��ʼ���ϣ�����ѡ��һ���Ӽ����Ż�ʹ��Լ��ѵ���������ݼ���Ȼ�����ɵ�֧�����������Ե���ʹ�ø��ӣ�Ŀ�꣩���ݼ�����ѵ���Խ�һ���Ľ��������ݡ�
��2�еĽ����ʾ��Լ��������ȡ��ʼѵ�������Ӽ��������Ŀ���趨����Ȼ��ʼ���ݼ��ķ��ྫ�Ƚ����ˣ��������ؽ�Ҫ�ģ���Ϊ����Ŀ���ǸĽ��µ����ڲ�������ݼ���Ȼ����ȡ���Ӽ�������������ѵ��Ŀ�꼯��һ�����Ŀ����������������33��ʾ���������ĺô����ܹ��������Ӧ�����ݼ���֧������������һ���棬�Գ�ʼֵʹ����Լ������ѵ�����������Ŀ�꼯�ķ��࣬���һ������˳�ʼ���ݼ���ȷ�ԣ�����33����������Dz���ʧȥ��ʼѵ�����ķ��ྫ�ȣ����統-ѵ��֧������������Ӧ��������ϵ�ͼ���������������Ҫʵ�ָĽ���ֻ��Ҫ���ٸ���������ݼ������õ�����ˣ�������ú�������Դ�����١�������ʹ������֧���������Ƿdz��ؼ��ġ�ʹ������֧��������ѵ�������������ӵ�ѧϰ�����У��������ͷ��ʼ��ѵ�������ǵ�ѵ���Ƿ����м������ܼ������������ǣ�����ʽ֧������������������ʡѵ��ʱ�䡣��Ҳʹ�����ܹ����������ӵ������Է���Ĺ�����֧�������������ܡ�
��Ϊһ��Ӧ�ó��������ܹ�Լ�������乱�������ڽ���������е�֧�������Է����ȷ�ԡ��ⷴ��������������ֻѡ���������Ż�Ŀ�꼯�ij�ʼѵ�����ݼ������ң���ѵ���̱�������ѡ�ι��̡��ټ���һ��������ѵ����Ŀ�����ݼ����Ժ����غϲ������յ�֧�����������������չʾ�˷�Լ��/Լ�������ʹ��֧��������ͼ��������ij�ʼѵ����������ѵ���ڳ��������¡���Ӧ���������������ʱ�������ش�ͨ����֤����������ѵ������������������ݼ�ʹ��������ʵ�ã������ڴ��Ͳ��������ܽ�ͨϵͳ�����ڸ��ӳɱ���������Դ������С�ġ�
�����
[1] Thrun, S., and Mitchell, T.M.: Learning one more thing. Proceedings of the 14th International Joint Conference on Artificial Intelligence (1995).
[2] Caruana, R.: Multitask learning. MachineLearning 28(1), 41�C75 (1997)
[3] Dai, W., Yang, Q., Xue, G-R., and Yu, Y.:Boosting for Transfer Learning. Proceedings of the 24th International Conference on Machine Learning (2007)
[4] Wu, P., and Dietterich, T.: Improving SVM Accuracy by Training on Auxiliary Data Sources. Proceedings of the 21st International Conference on Machine Learning (2004)
[5] Raina, R., Battle, A., Lee, H., Packer, B., and Ng, A.: Self-taught Learning: Transfer Learning from Unlabeled Data. Proceedings of the 24th International Conference on Machine Learning (2007)
[6] Cauwenberghs, G. and Poggio, T.: Incremental and Decremental Support Vector Machine Learning. In: Leen, T.K., Dietterich, T.G., and Tresp, V. (eds) Advances in Neural Information Processing Systems, vol. 13, pp. 409-415. MIT Press (2001)
[7] Laskov, P., Gehl, C., Kruger, S., and Muller, K.R.: Incremental Support Vector Learning: Analysis, Implementation and Application. Journal of Machine Learning Research 7, 19091936 (2006)
[8] Dalal, N. and Triggs, B.: Histograms of Oriented Gradients for Human Detection. Conference on Computer Vision and Pattern Recognition (2005)
[9] Ralaivola, L. and d Alche Buc, F.: Incremental support vector machine learning: A local approach. LNCS 2130, 322-329 (2001)
[10] Kivinen, J., Smola, A. J. and Williamson, R. C.: Online learning with kernels. In: Diettrich, T.G, Becker, S., and Ghahramani, Z. (eds.) Advances In Neural Information Processing Systems (NIPS01). pp. 785-792 (2001)