目录
项目开发报告 1
题目:互联网虚假新闻检测 1
计算机科学与技术学院 1
项目开发报告 3
1.1项目目的 3
1.2问题分析 3
1.3设计与分析 4
1.3.1 数据分析 4
1.3.2 算法流程设计 4
1.3.3 机器学习算法设计 5
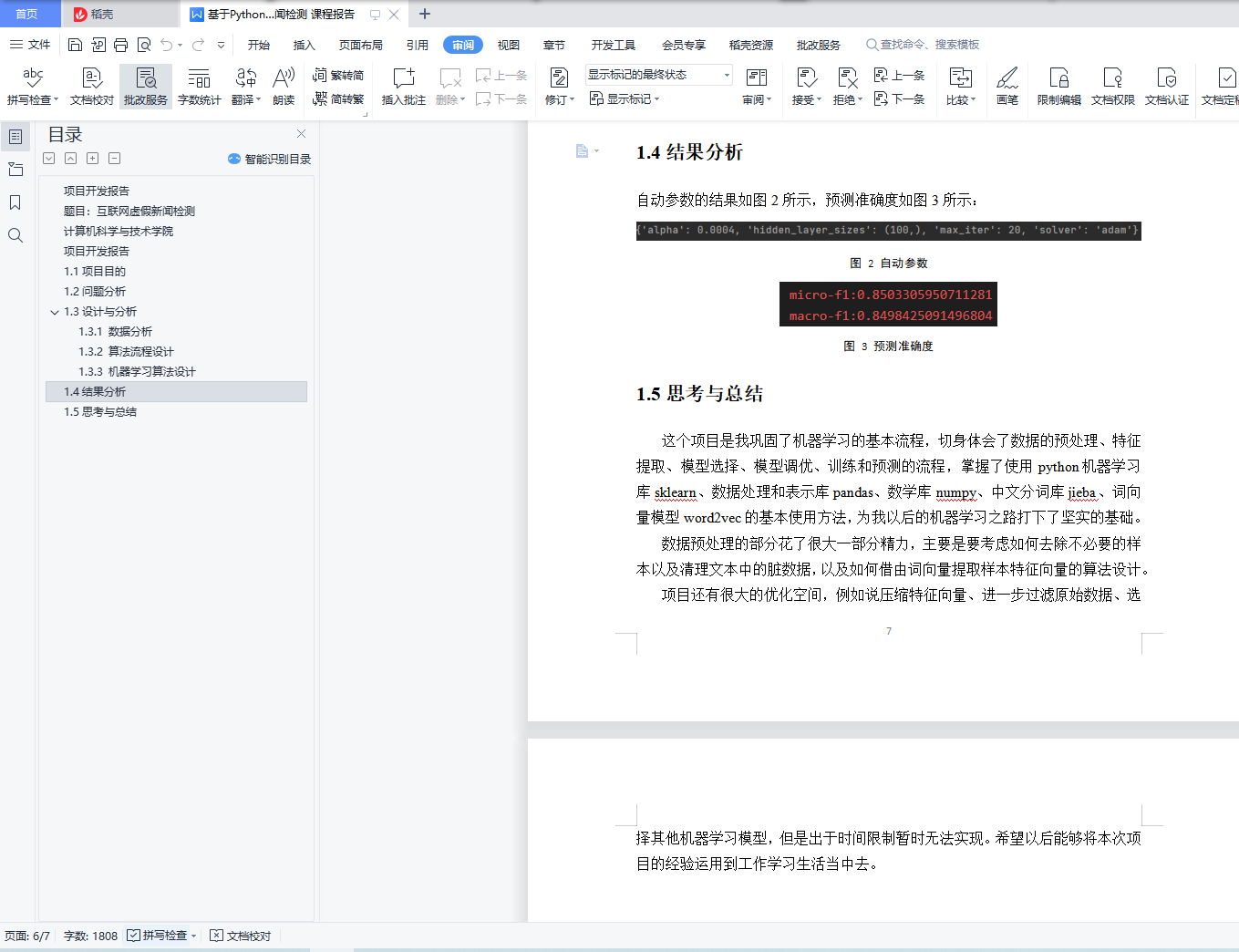
1.4结果分析 6
1.5思考与总结 6
项目开发报告
1.1项目目的
随着互联网的飞速发展,家家户户都逐渐牵上了网线,凭借着网络的便利性,外界信息得以轻松的得知,对于百姓们熟知的新闻信息的获取也能在须臾之间完成。然而任何事物的发展都具有两面性,互联网虽说使得信息的产生和获取更加便捷,也滋生了不少虚假新闻扰乱民众的视听,倘若放任不管甚至可能导致谣言泛滥成灾,最终影响到现实社会秩序。
本项目旨在通过机器学习训练出具有一定可靠性的互联网虚假新闻检测模型,更具体一点是通过监督学习训练出一个判断新闻是否虚假或者无需判断的分类模型,从而为网络环境的精华献出一份力量。
1.2问题分析
互联网虚假新闻检测可以视为一个三分类监督学习问题,主要难点在于如何将新闻材料中的信息主体和评论两种文本转化为特征向量,以及筛选、过滤掉对模型训练无用的信息。为方便后续分析,可以构建如下模型:记一条新闻的新闻内容为content,全部评论为comment_all,新闻真假为label,这样的三元组(content, comment_all, label) 为一个训练样本,二元组的集合{(content, comment), …}为待预测的数据。
于是问题转化为:
①数据清理(清理无用样本,对content、comment_all分词,停用词过滤)
②特征向量提取(首先训练出词向量模型然后组成文本向量)
③选择训练模型
④ 预测和评价
1.3设计与分析
1.3.1 数据分析
首先通过粗略地观察数据集可以发现存在部分N/A空值,这些不完整地信息肯会干扰到后续数据清理,因此要事先调用pandas库进行空值填充;文本信息中通常会夹杂着一些表情代码(通常以中括号包裹)和@字段,这些对于新闻真假的判断来说作用不大可以去掉。
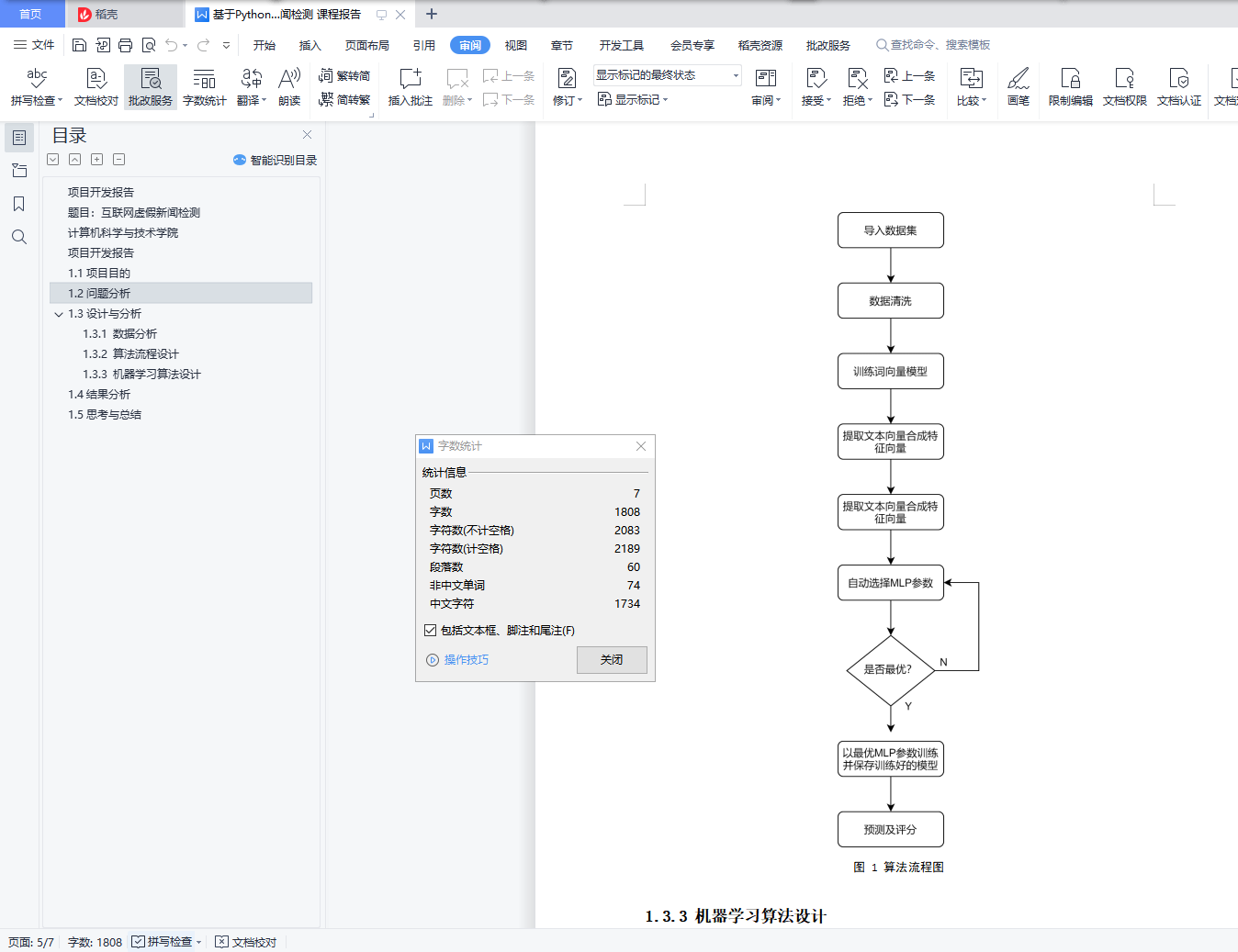
1.3.2 算法流程设计
本项目主要分为以下几个步骤:
①预处理proccess;这个阶段要进行数据导入,数据清理和分词工作,此外还要生成词向量模型,再根据得到的词向量模型构建样本的特征向量。
②模型参数自动调优 optimize;
③模型训练 fit;本项目将采用多层感知机的机器学习模型,该模型是一个多分类的线性分类模型。
④预测 predict;
⑤分析优化 analyze;
由于中文分词、训练词向量、模型参数选择、模型训练这四个部分耗时较大,为了避免不必要的时间浪费,我将分词结果、词向量模型、模型参数、训练好的MLP模型分别保存,方便下一阶段直接使用,以实现模型的持久化。
总体的算法流程图描述如下: