目录
程序运行说明 1
背景及任务定义 4
提出方法 5
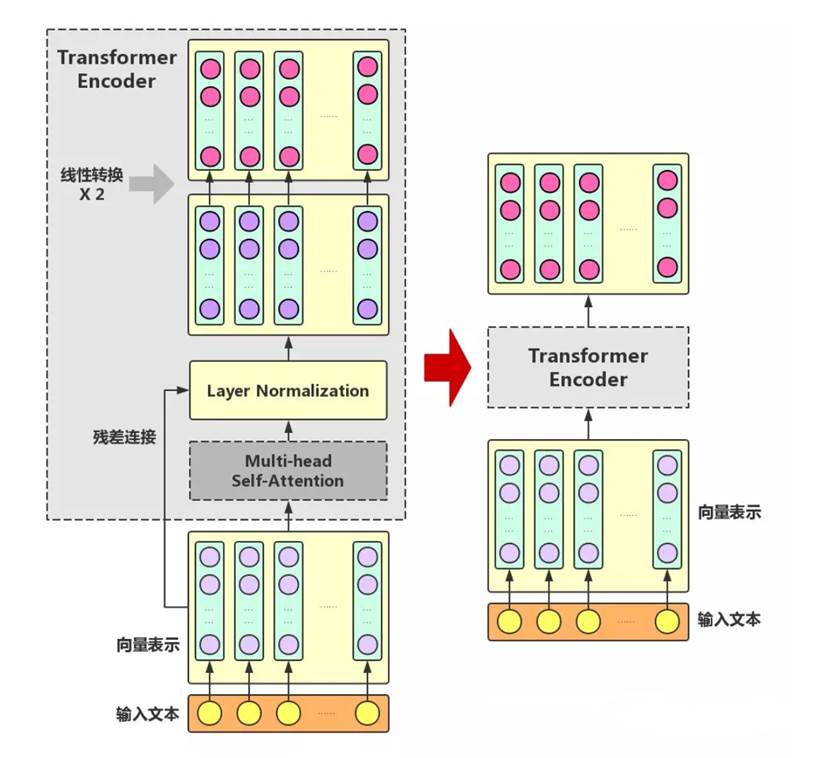
1. 残差连接 10
实验 15
结论 17
程序运行说明
硬件
GPU: Tesla V100, 32GB显存
内存:32GB
系统:Linux(训练),Windows(展示)
软件
CUDA版本: 9.2
Pytorch:1.5
其他库:gensim,sklearn,tqdm,flask,numpy等
运行方法
如果直接使用,步骤为:
1.进入"Flask"文件夹,在cmd中执行以下命令:python NLP_flask.py,便可启动 flask 后台,然后在浏览器地址栏输入127.0.0.1:5000,即可看到分类系统界面。
如果需要训练,步骤为:
1.如果想要训练非bert的模型,需要先训练词向量:进入"src"目录下,在terminal中执行以下命令:python train_w2v.py,修改该文件的代码可以设置word2vec的窗口大小、词向量维度等。
2.(./src目录)在terminal中输入python run.py --model model_name --word True/False,即可启动相应模型的训练。model_name是选择的模型,word为True(默认)则进行词级别的训练,否则进行字级别的训练。word参数只针对非bert模型,因为bert是分字的。可选的模型会在后面介绍。
**注意:**训练之前请先下载数据集和bert的相关文件,在相应的文件夹内有README说明文档,内附有百度云盘下载链接。
代码文件说明
下面解释./src目录下的代码:
run.py 训练主程序
train_eval.py 具体的训练逻辑
utils.py 工具类函数
train_w2v.py 训练词向量
global_config.py 全局参数设置,如batch_size等
./model 下是不同模型的实现
./temp 下存放了预训练的词向量