目录
一、实验选题、实验内容及功能说明 1
二、设计方案与设计思路 2
① 爬取信息(spider.py) 2
② 数据结构建模(spider.py) 3
③ 建立B+树(BPlus.py) 3
④ GUI设计(UI.py,UIdesign.py) 3
⑤ 检索(BPlus.py) 3
⑥ 异常处理(UI.py) 3
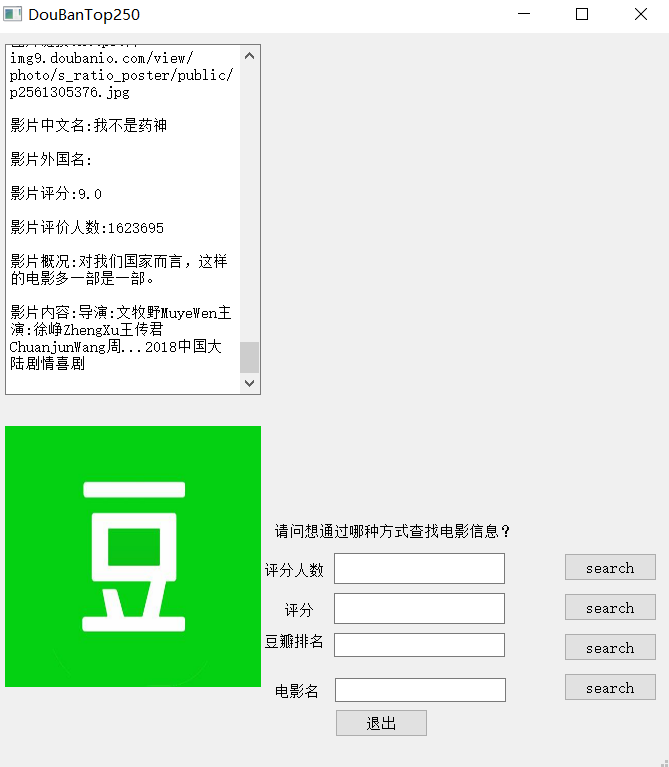
三、程序运行效果 4
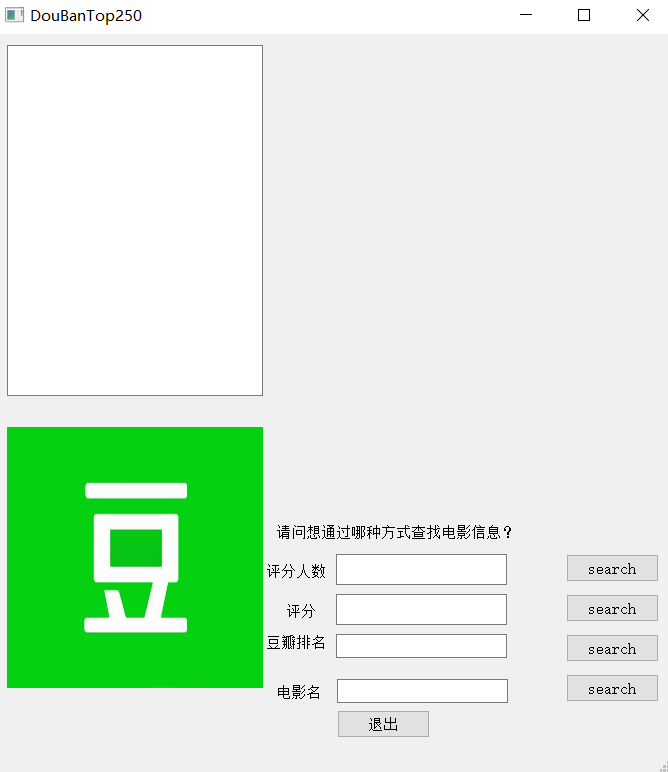
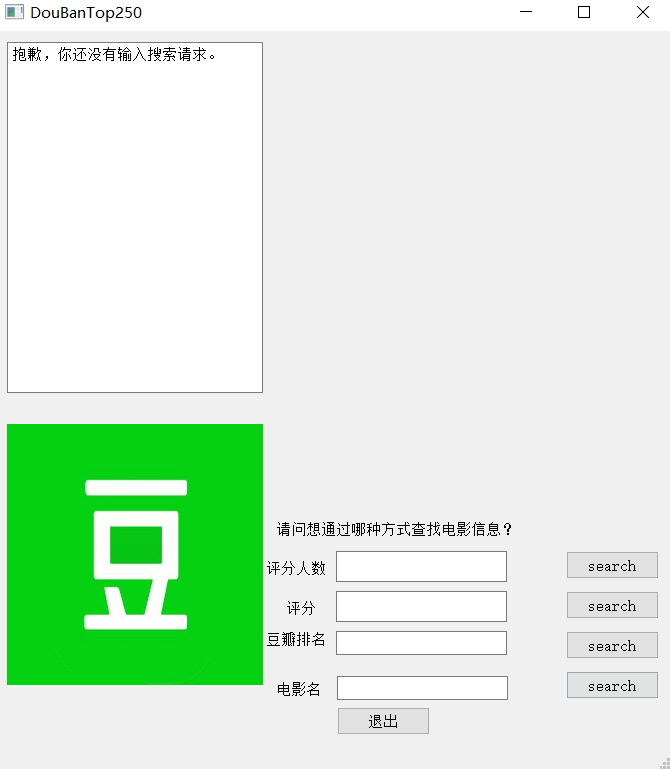
打开程序: 4
豆瓣排名搜索: 5
电影名搜索: 7
评分模糊搜索: 9
评价人数模糊搜索: 11
异常处理展示: 13
(所有搜索窗无输入) 13
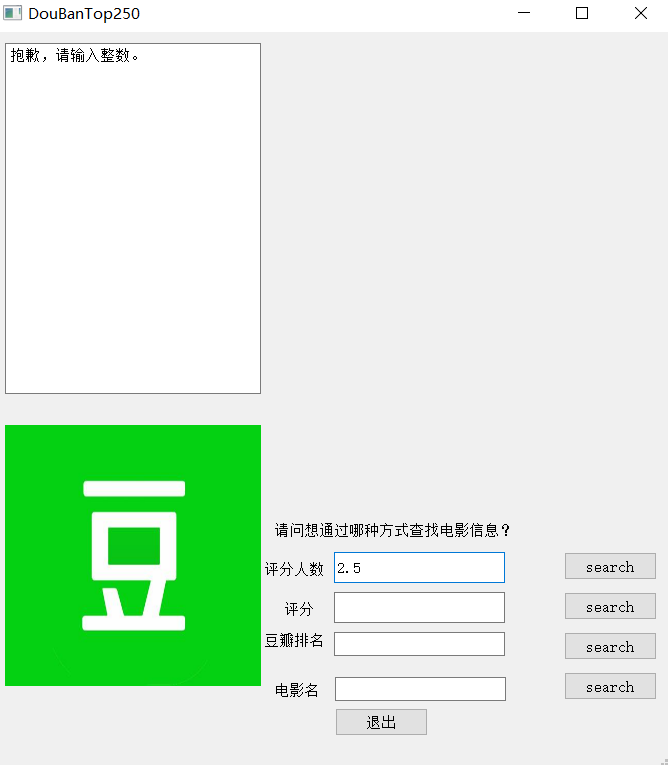
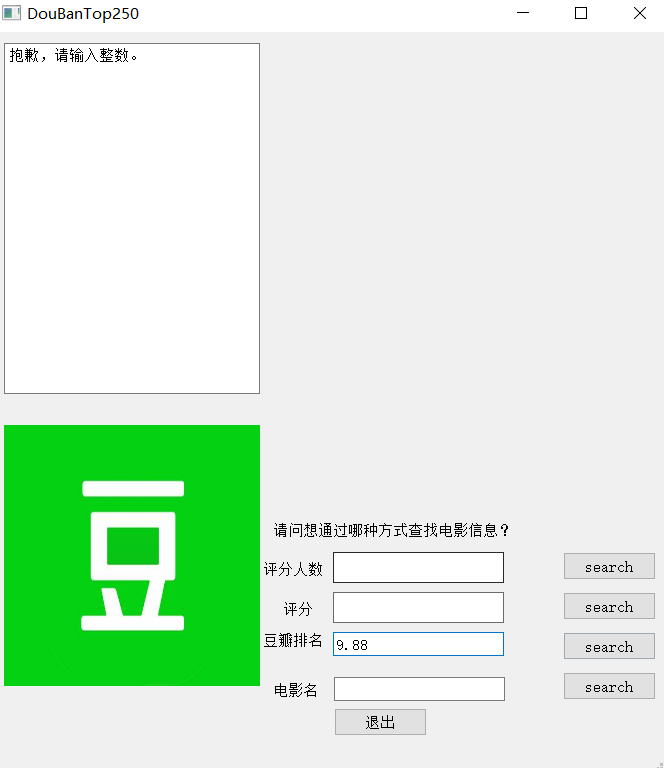
(整数要求) 15
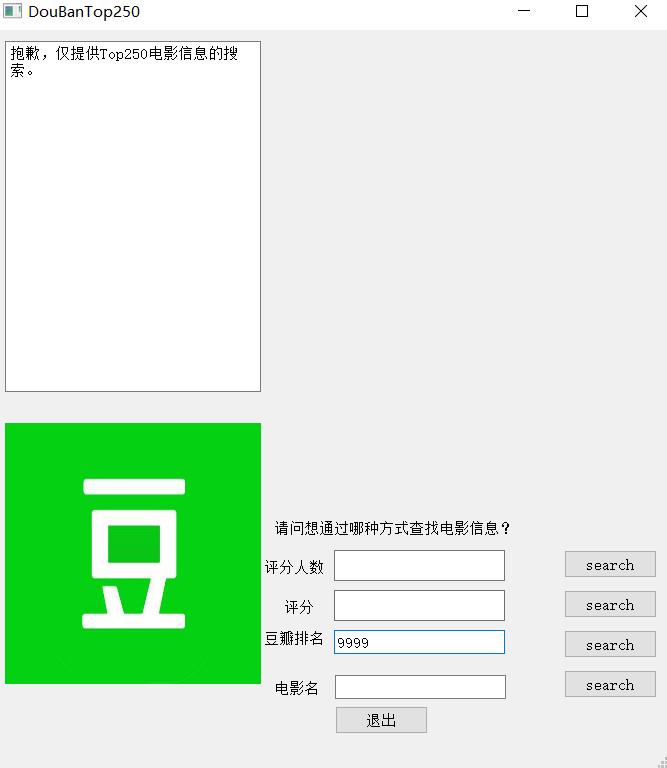
(排名限制) 16
(评分限制) 17
(库中无目标电影) 19
第三方库函数: 19
四、设计亮点 20
五、实验总结 21
① 不知道怎么把网页上的信息保存下来 21
② 不知道怎么保存信息和读出信息 21
③ 不知道怎么反反爬 21
④ 不知道B+树是干嘛的,怎么写,怎么用 21
⑤ 不知道怎么设计GUI 21
⑥ 使用过程中程序经常崩溃 21
一、实验选题、实验内容及功能说明
①实验选题
爬虫检索系统
②实验内容
从豆瓣Top250电影榜单上爬取所有电影的相关信息(包括影片海报、影片海报链接、影片中外文名、影片评分、影片评价人数、影片概况、影片缩略信息,例如:导演,部分演员,上映时间,电影类型等等),将海报以.jpg形式、将其他信息以excel文件的形式存在本地,数据量足够支撑现场演示的检索需求;在爬取信息的同时产生了一个字典,以排名为键,中文名为值,将其存在本地,方便爬虫完毕后的查找。
以豆瓣榜单中的排名为键,以待查电影存在本地的图片路径和excel路径组成的元组为值,建立B+树,为了扩充查找功能,建立一个hash表,键为豆瓣排名,值为中文名和评分人数,以及评分组成的列表。当要查找排名时,通过键的比对可以迅速定位磁盘路径,减少对磁盘的读取次数,提高查找效率,查找其他信息时通过hash表映射,将在磁盘中的搜索转化为在内存中的搜索,大大提高检索效率。
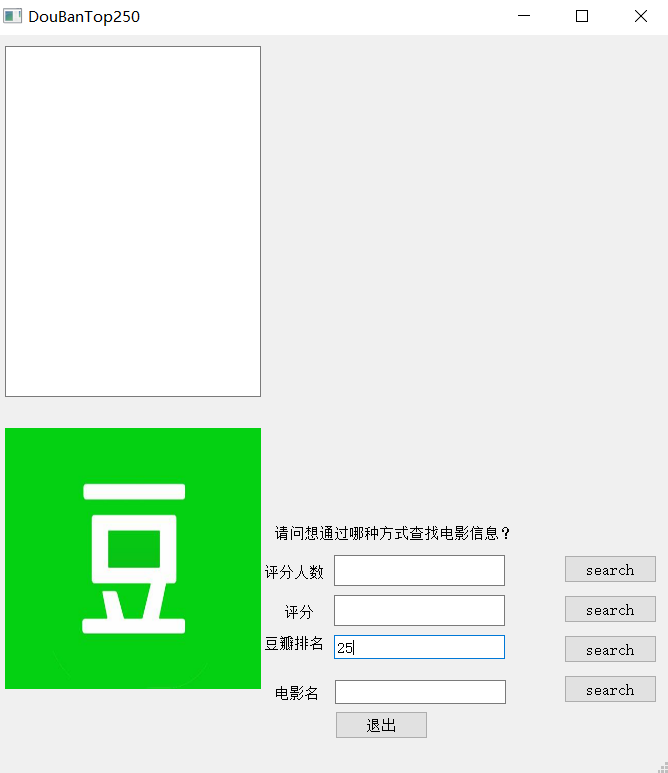
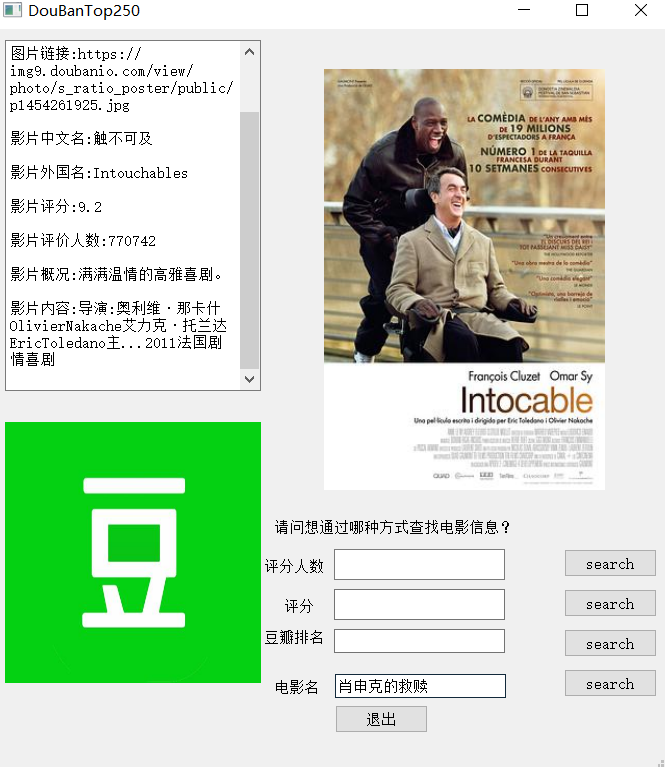
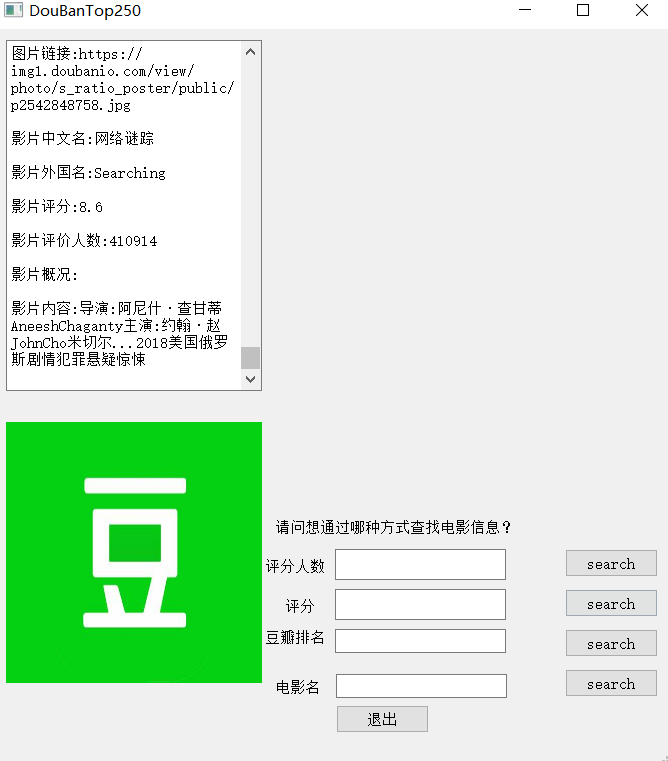
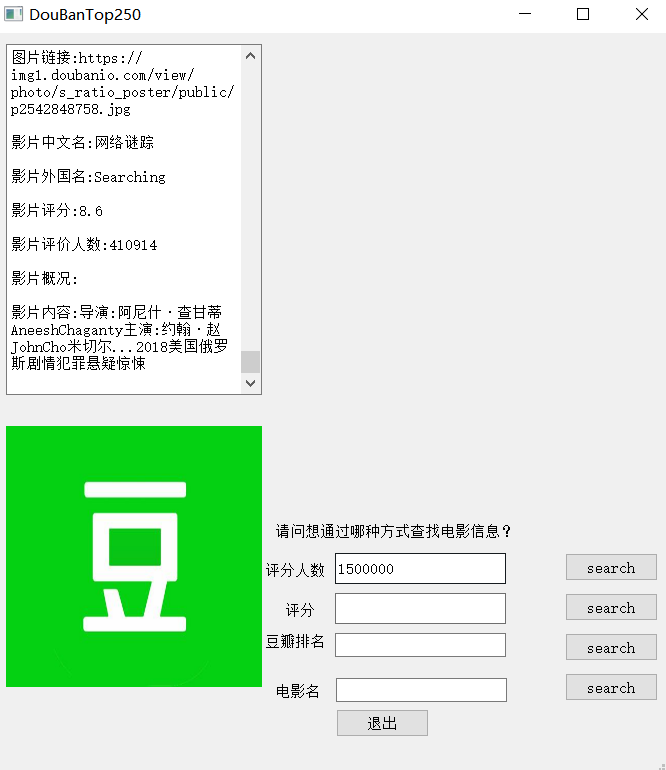
在GUI界面提供了豆瓣榜单排名准确查找,电影名准确查找,评分区间模糊查找,评分人数区间模糊查找(即查找符合要求区间的所有电影,由于数量过多此时不呈现电影海报)。
为查找的过程提供了异常处理,提高了该查找软件的用户友好度。