目录
一、实验室名称:立人楼B105 0
二、实验项目名称:使用词带模型进行场景识别 0
三、实验原理: 0
四、实验目的: 0
五、实验内容: 1
微小图像 1
Kmeans 1
SIFT 1
SVM 2
六、实验器材(环境配置): 2
七、实验步骤及操作: 3
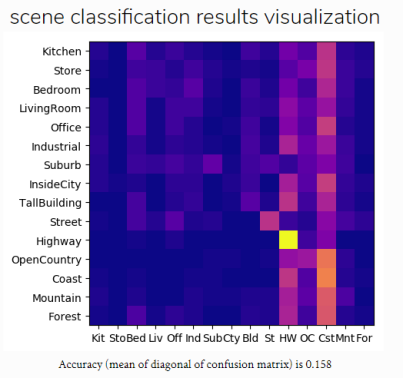
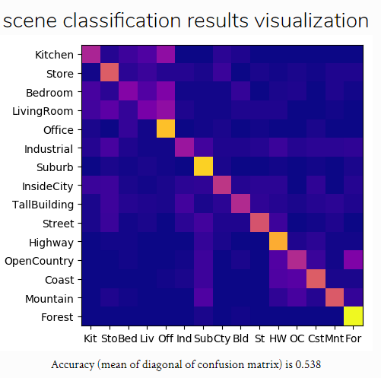
八、实验数据及结果分析: 9
九、实验结论: 11
十、总结及心得体会: 11
十一、对本实验过程及方法、手段的改进建议: 11
报告评分: 11
指导教师签字: 11
一、实验室名称:立人楼B105
二、实验项目名称:使用词带模型进行场景识别
三、实验原理:
先从非常简单的方法(微小图像和最近邻分类)开始检查场景识别的任务,然后转向更高级的方法 - 量子化局部特征和支持向量机学习的线性分类器。
词袋模型是受自然语言处理中使用的模型启发的用于图像分类的流行技术。该模型忽略或淡化单词排列(图像中的空间信息),并基于视觉单词频率的直方图进行分类。视觉词“词汇”是通过聚类大量局部特征来建立的。
四、实验目的:
图像识别。特征提取+分类器构建和使用
五、实验内容:
实现2种不同的图像表示:
- 微小图像和SIFT特征包
以及2种不同的分类技术:
- 最近邻和线性SVM。
在撰写中,特别要求您报告以下组合的性能,并且强烈建议您按以下顺序实现它们:
微小的图像表示和最近邻分类器(精度约为18-25%)。
基于SIFT特征的词带模型的表示和最近邻分类器(精度约为50-60%)。
基于SIFT特征的词带模型的和线性SVM分类器(精度约为60-70%)。
从实现微小图像表示和最近邻分类器开始。它们易于理解,易于实施,并且可以非常快速地运行我们的实验。