摘要
如今Pubmed文献检索系统上发表的医学文献的数量十分庞大,且数量逐年增加,研究人员如果想人工地去查看找出Pubmed文献里面的知识是绝对不可能,因此,人们转而利用计算机去获取文献里面的知识。
本篇论文介绍了如何借用文本挖掘技术去挖掘出Pubmed文献里面的知识,并且结合了目前文本挖掘技术,讲述了如何实现了一套蛋白质磷酸化修饰的文本信息挖掘系统。
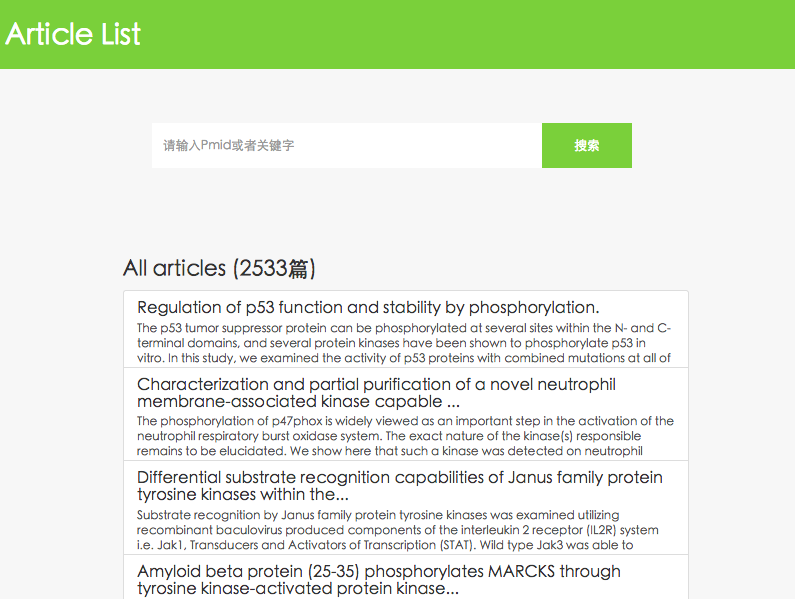
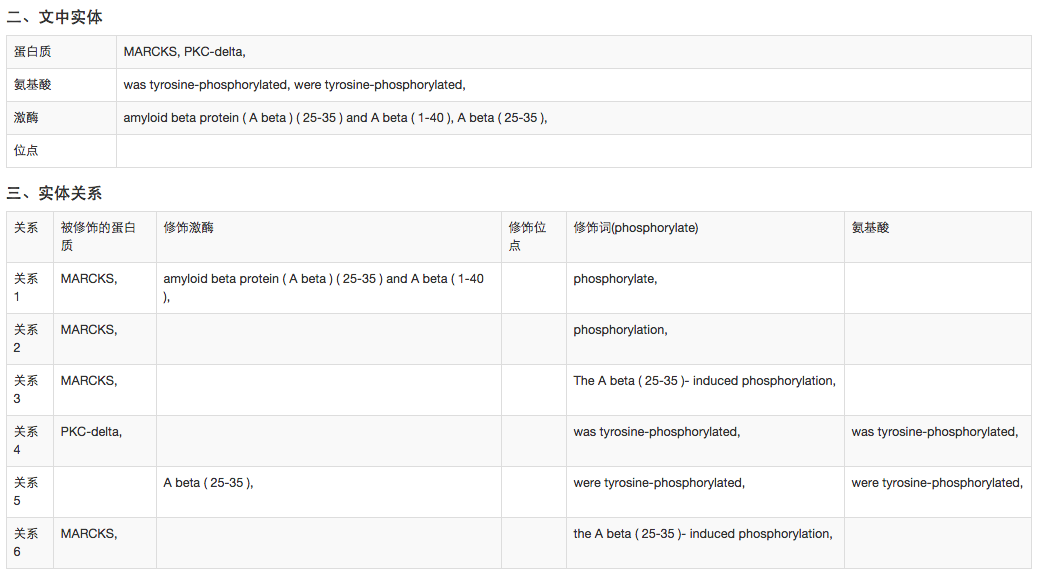
本系统主要应用于挖掘出Pubmed文献里面蛋白质磷酸化的修饰的一些信息,包括被修饰的蛋白质,激酶,修饰位点,以及它们之间的关系。
本文详细叙述了整套系统瀑布流模型的软件过程,首先是需求,然后是设计,再是实现,依次展开。在实现的阶段里面又包含了文本预处理阶段,命名实体识别阶段,实体关系提取阶段,数据可视化阶段,其中着重介绍了文本挖掘技术中两个的关键也是核心阶段的原理:命名实体识别和关系提取。同时也介绍了Abner工具和Rlims-p工具的原理和应用。此外文献数据库的数量庞大,为了提高程序性能和用户体验,于是介绍了几种提高效率,提高用户体验的解决方案,其中有多线程处理,缓存机制,预处理机制。
关键词:文本挖掘;软件工程;Pubmed;多线程
Abstract
Nowadays, The number of published medical literature on Pubmed document retrieval system is very large, growth year after year. It is absolutely impossible to researchers manually discover knowledge among the Pubmed literatures. As a result, researchers turn to use the computer to acquire knowledge inside the literature.
This paper introduce how to acquire knowledge in Pubmed literature by using the technology of text mining and how to implement a text mining system for extracting protein phosphorylation information among Pubmed literature using the current text mining technology. This system is main used for extracting protein phosphorylation information among the Pubmed literatures such as substrate, kinases, sites, and relation among these substances. With the current text mining technology, I
This paper describes the waterfall model of software process about this system. First step is requirement, second step is design, and then implementation, step by step.In the step of implementation, there are four steps as follow: text preprocessing, named entity recognizeation, relationship extracting, Visualization. This paper highlights the principle and application of two very important steps in text mining: named entity recognization, and relationship extracting. At the same time, Abner tools and Rlims-p tools are also introduced in this paper. Moreover, the number of the Pubmed literatures in database is very large, and in order to improve the program performance and user experience,this paper had introduced several method for improve the program performance and user experience such as multithreading, caching, preprocessing.
Keyword: Text mining, Software engineering, Pubmed, Multithreading
目 录
摘要
Abstract
第一章 引言
1.1 概述
1.2 选题的背景和意义
第二章 入门概念
2.1 蛋白质以及翻译后修饰概述
2.2文本挖掘技术概述
2.3 Pubmed生物医学文献检索系统
第三章 需求分析和系统设计
3.1需求
3.2 需求分析
3.3 用户用例分析
3.4 系统设计
3.4.1 系统工作流程和场景
3.4.2 模块化设计
3.4.3 软件开发架构
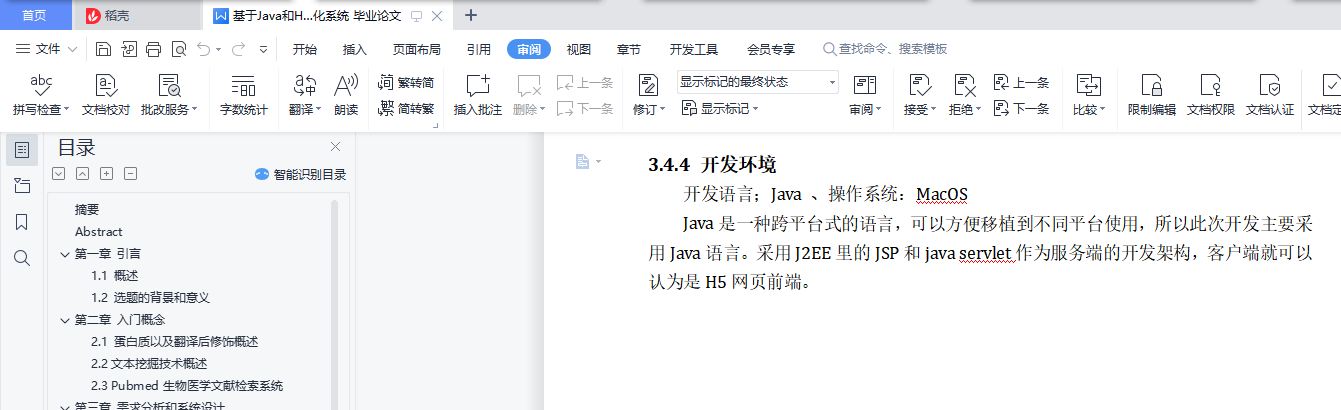
3.4.4 开发环境
第四章 程序设计和系统实现
4.1 程序设计
4.2 文本数据源获取
4.3 文本预处理
4.4 命名实体识别和实体关系提取
4.4.1命名实体识别概述
4.4.2 ABNER命名实体识别工具
4.5 实体关系提取
4.5.1 关系提取概念
4.5.2 Rlims-p工具介绍及其工作原理
4.5.3 嵌入使用Rlims-p工具
4.6 多线程处理文档优化
4.7 文档预处理和缓存机制
第五章 数据库设计和数据可视化
5.1数据库设计
5.2 数据可视化
第六章 总结及展望
6.1 总结
6.2 展望
结束语
参考文献
D4WSOH}$FX3~9W.png)
R8G05$JN7%3NQCTWBFE2P.png)
$6}S1AN){%942W(S`JVK0A.png)

1.png)



Q3`M_VVM`%ZWNG~7NFYLF.png)