基于MATLAB的噪声环境中单一声音的识别系统
摘 要
声音中包含了大量生活环境和事件的信息,人可以通过声音察觉自己的所处的场景,例如忙碌的街道、办公室、商场等,识别其中独特的声音,例如汽车通过的声音、脚步声、说话声等。识别声音源的技术在许多应用中有十分重要的作用,例如按照音频内容在多媒体库中检索,制作感知环境的移动设备、机器人、汽车,在智能监控系统识别环境中的活动等。在多声音源混合场景中识别单一声音,以致达到识别环境的目的,还需要大量的研究。课题专注于研究在多种声音混合的场景识别单一声音的方法。
本次设计的仿真实验均在matlab2016b上进行,模拟公园或幼儿园的场景,将小孩的哭声、脚步声、小鸟叫声音三种声音混合在一起。课题专注于如何从这三种混合声音中识别出是否有小孩哭声。主要步骤包括:从混合声音中提取目标声音(小孩哭声),提取音频MFCC特征,将特征数据带入根据训练好的隐马尔可夫模型,进行识别分类。对于如何从三种混合声音中提取出目标声音,本文介绍了两种方法。第一种是根据基频处理的方法,将三种声音录制成一段音频,根据待识别声音的基频范围设计对应的滤波器,将目标声音的基频大致过滤提取出来;第二种是盲源分离,利用盲源分离的方法将这三种声音从混合后的观测声音中分离出来,提取出目标声音。在从混合声音中提取出目标声音(小孩哭声)后,经过分帧加窗端点检测后,提取小孩哭声的MFCC特征,将特征数据带入已经训练好的隐马尔可夫模型HMM中,得出识别结果,比较识别结果与实际类别是否相同,得出模型的识别准确率。
本论文从仿真实验模拟为起点,通过将同一场景中混合声音分离,提取出单一目标声音,提取音频MFCC特征,对目标音频分类识别,根据识出的目标声音来推测识别可能的所在场景。
关键词 声音混合;分离提取;提取特征;音频分类
Single Sound Recognition in Multi-sound Scene
Abstract
The sound contains a large number of living environment and event information, people can be aware of their own at the scene, which identify the unique sound, such as a car through the sound of footsteps, voices, etc.. The sound source recognition technology has a very important role in many applications, such as in accordance with the audio content in the multimedia database retrieval, mobile robot, production equipment, to perceive the environment, in recognition of the intelligent monitoring system of activities. A large number of studies are needed to identify a single sound in a multi sound source mixed scene, so as to achieve the purpose of identifying the environment. The topic focuses on the study of the recognition of a single sound in a mixture of scenes.
The design of the simulation experiments are carried out on the matlab2016b, the simulation of the park, zoo or nursery scene, the child's cry, footsteps, the sound of the birds called the sound of three mixed together. In this paper, two methods are introduced to extract the sound from the three kinds of mixed sounds. The first is based on the method of baseband processing, three kinds of voice recorded into an audio filter, according to the design of pitch range corresponded to the voice recognition, voice frequency target roughly extracted second kinds of filter; blind source separation method, by using blind source separation of the three separated from the mixed voice the observation in the voice. After extracting the target sound from the mixed sound, the MFCC features of the audio are extracted, and the three types of audio are trained by using the audio classification model.
This paper from the simulation as a starting point, by separating the extraction of target sound mixed sound in the same scene, MFCC features to extract audio, audio classification, according to the identified target sound recognition in the scene to speculate.
Key words: Multi-sound Scene; separation and extraction; feature extraction; audio classification
目 录
摘 要
Abstract
第一章 绪论
一、 开发背景和意义
二、 国内外研究现状
三、 研究主要内容
(一) 设计的思路
(二) 设计的步骤
四、 论文的组织结构
第二章 音频提取识别相关工作的介绍
一、 开发环境MTALAB介绍
(一) Matlab介绍
(二) Matlab的优势
(三) Matlab的简单使用
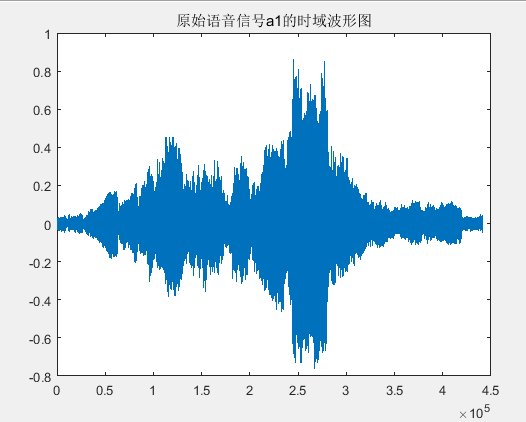
二、 音频信号的时频分析
(一) 声学
(二) 时域分析
(三) 频域分析
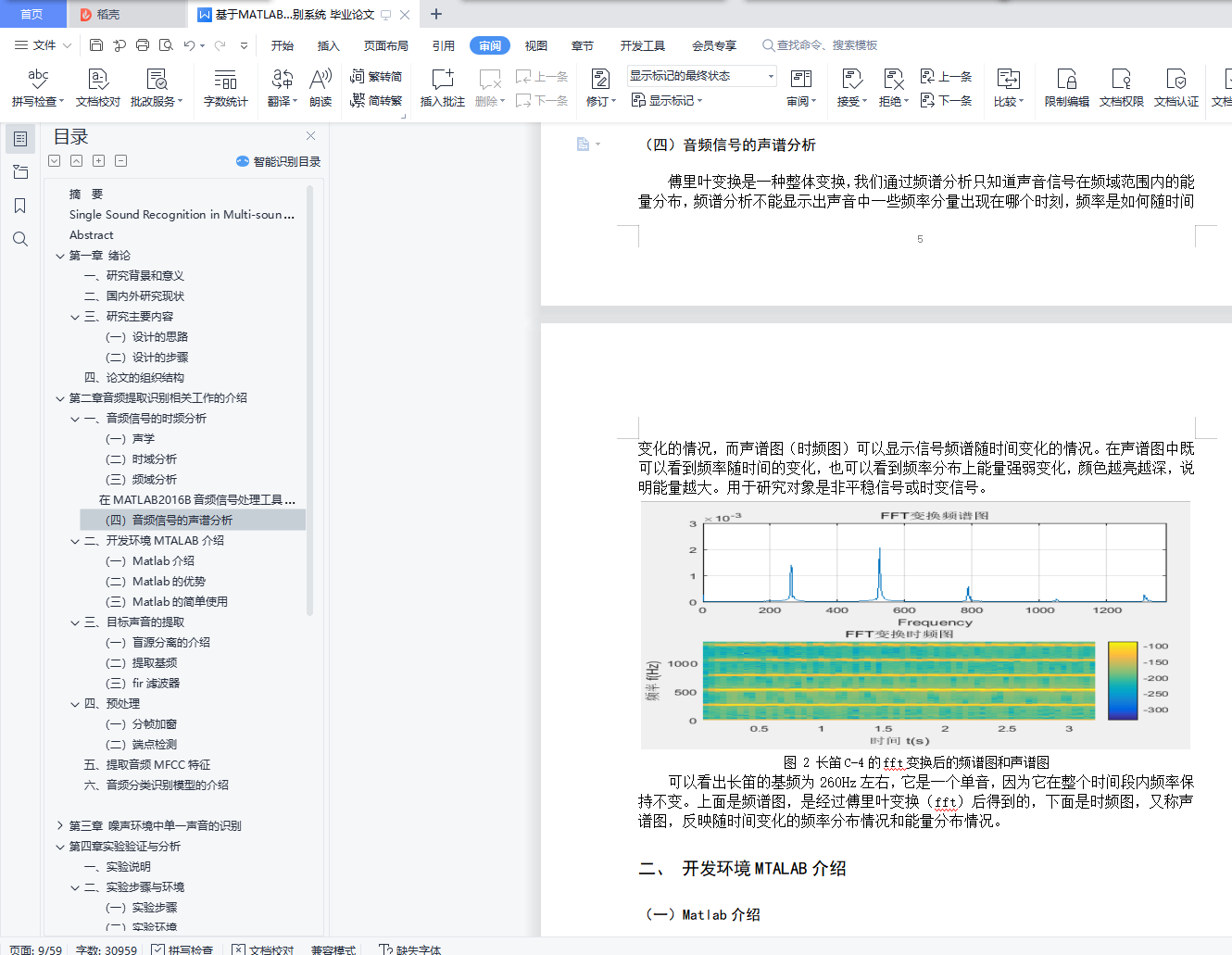
(四) 音频信号的声谱分析
三、 目标声音的提取
(一) 盲源分离的介绍
(二) 提取基频
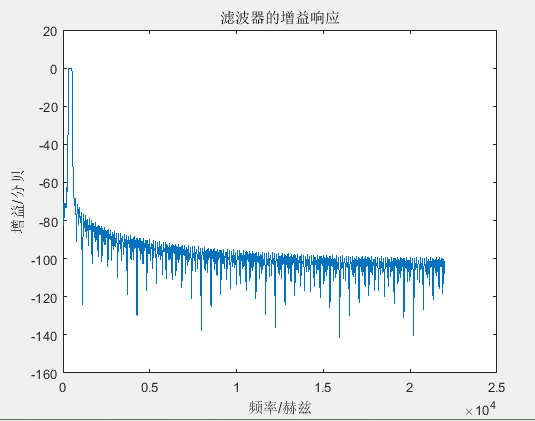
(三) fir滤波器
四、 预处理
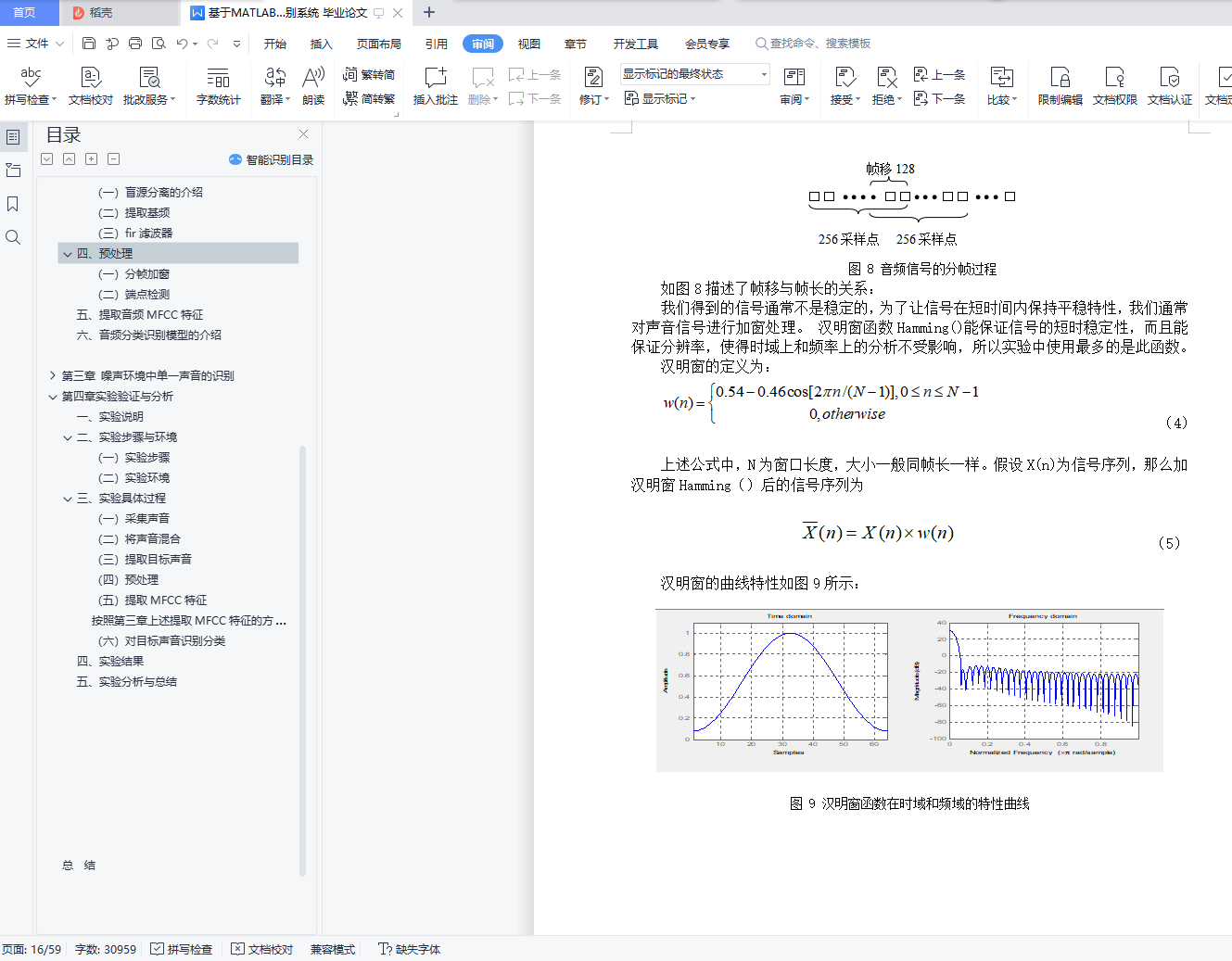
(一) 分帧加窗
(二) 端点检测
五、 提取音频MFCC特征
六、 音频分类识别模型的介绍
第三章 从噪声环境中识别单一声音
一、 整体流程介绍
二、 采集声音
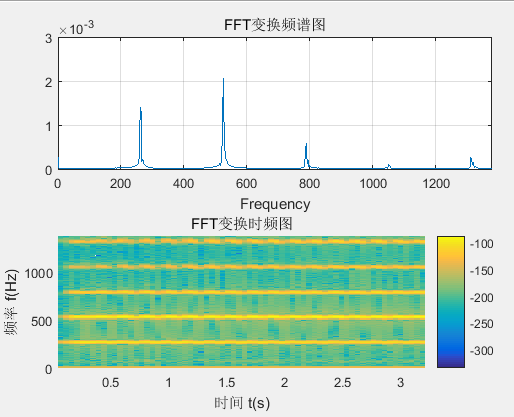
三、 时频分析
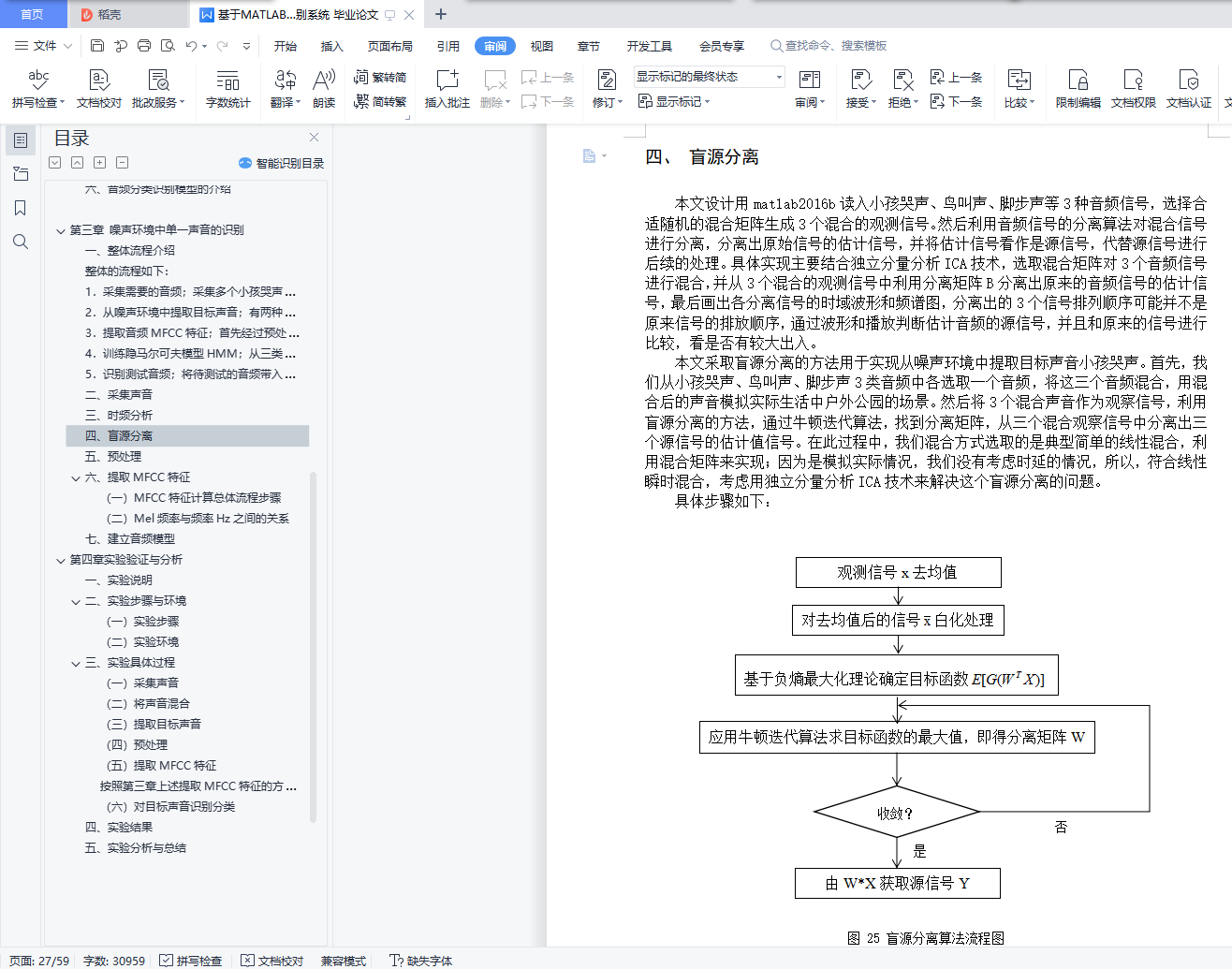
四、 盲源分离
五、 预处理
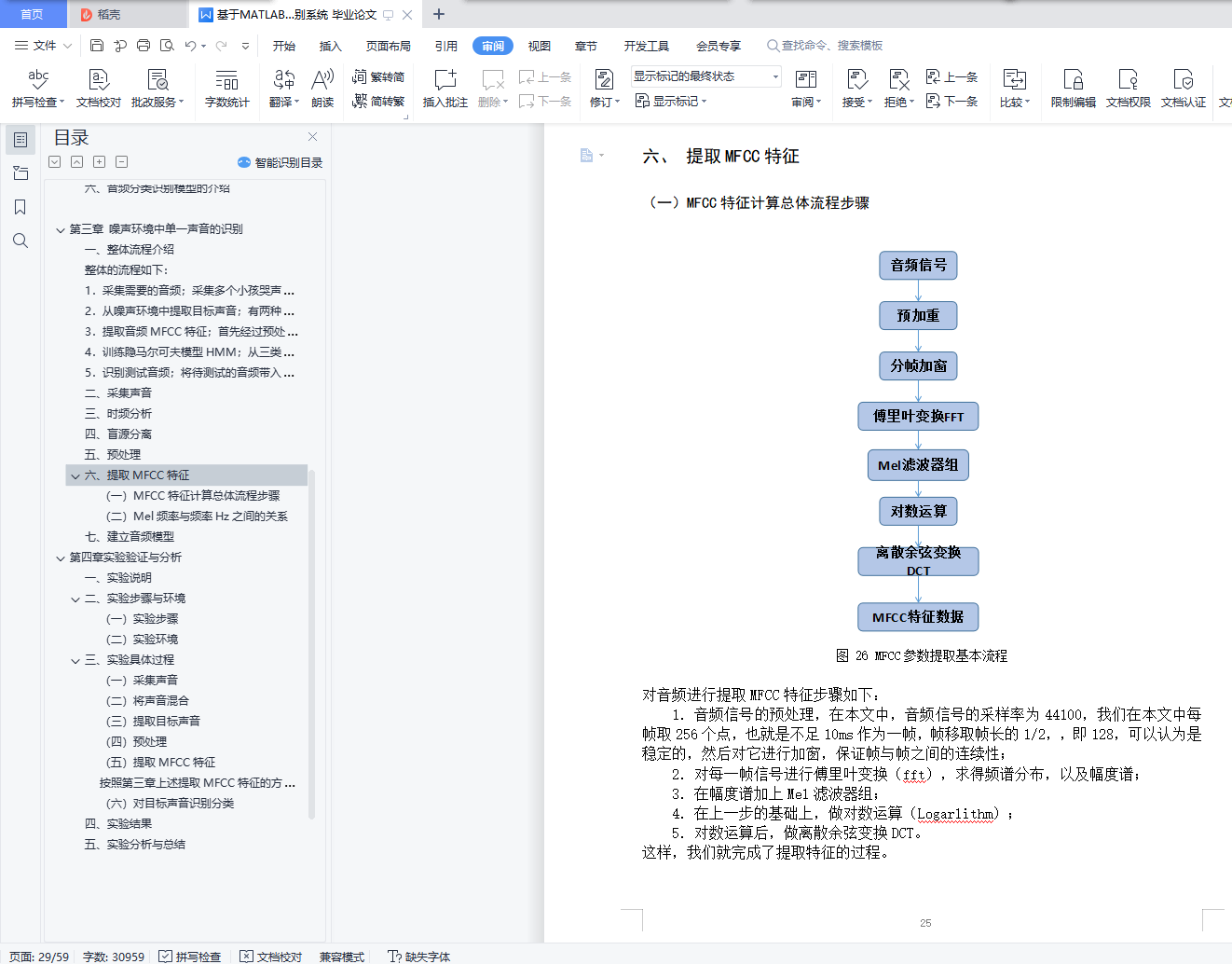
六、 提取MFCC特征
(一) MFCC特征计算总体流程步骤
(二) Mel频率与频率Hz之间的关系
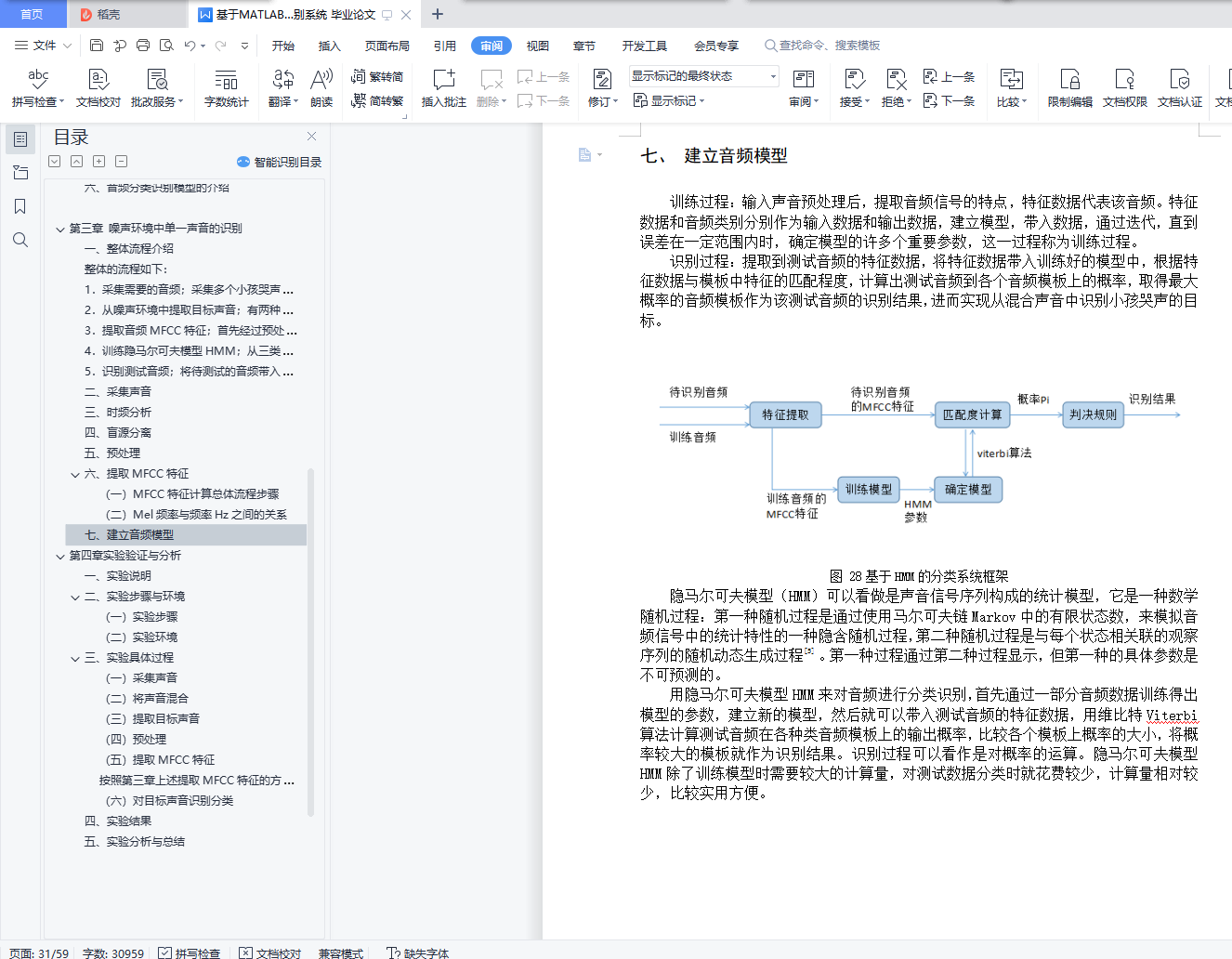
七、 建立音频模型
第四章 实验验证与分析
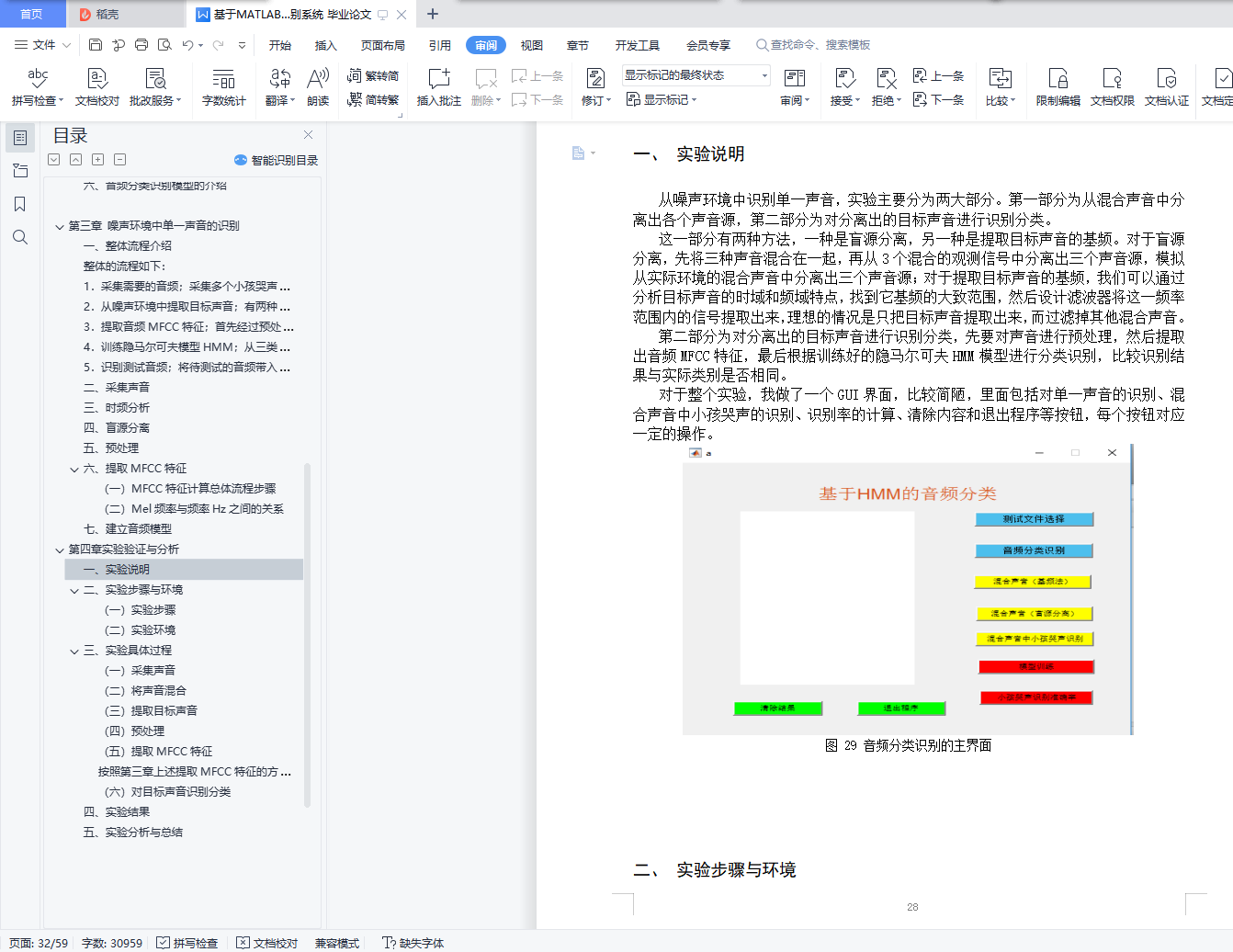
一、 实验说明
二、 实验步骤与环境
(一) 实验步骤
(二) 实验环境
三、 实验具体过程
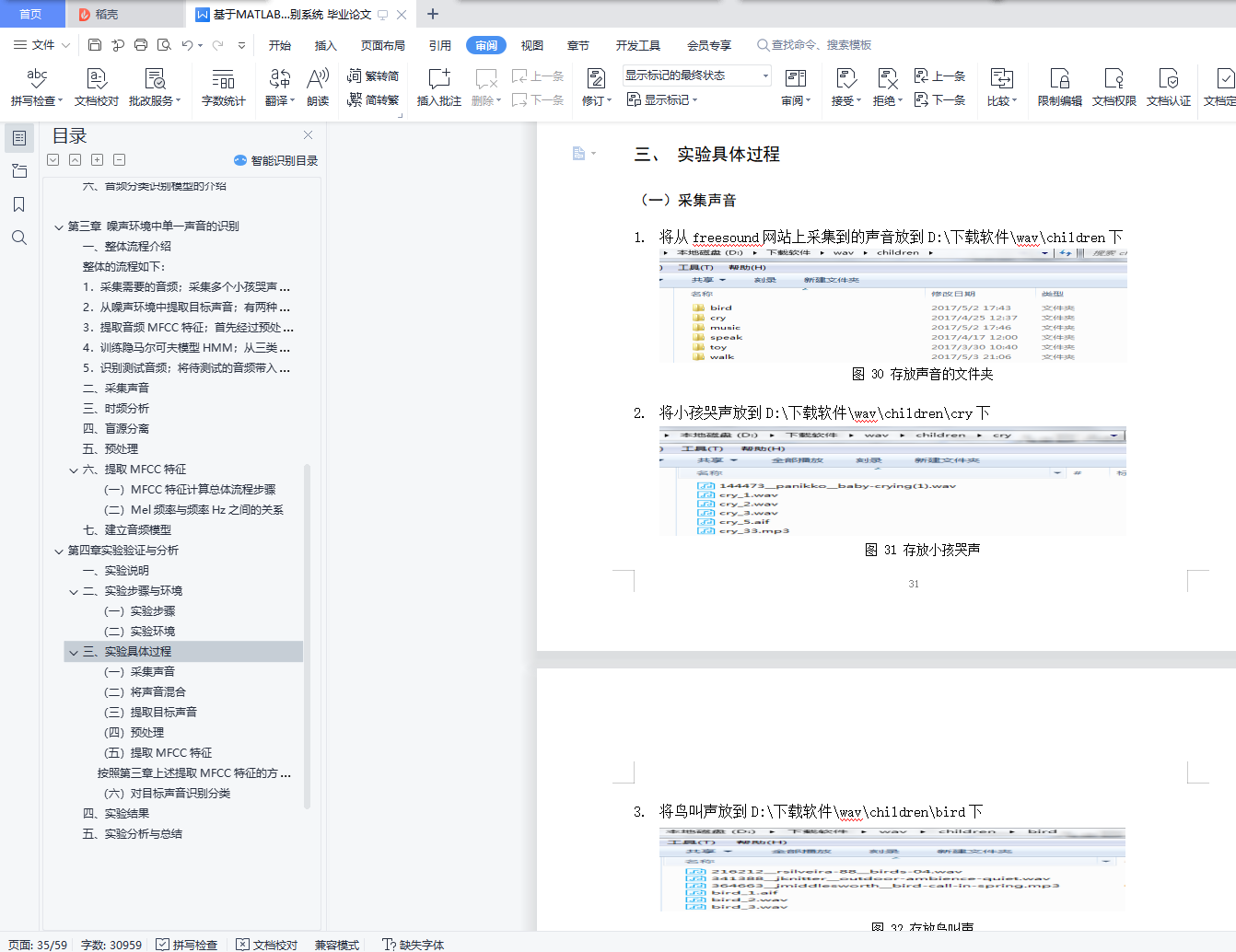
(一) 采集声音
(二) 将声音混合
(三) 提取目标声音
(四) 预处理
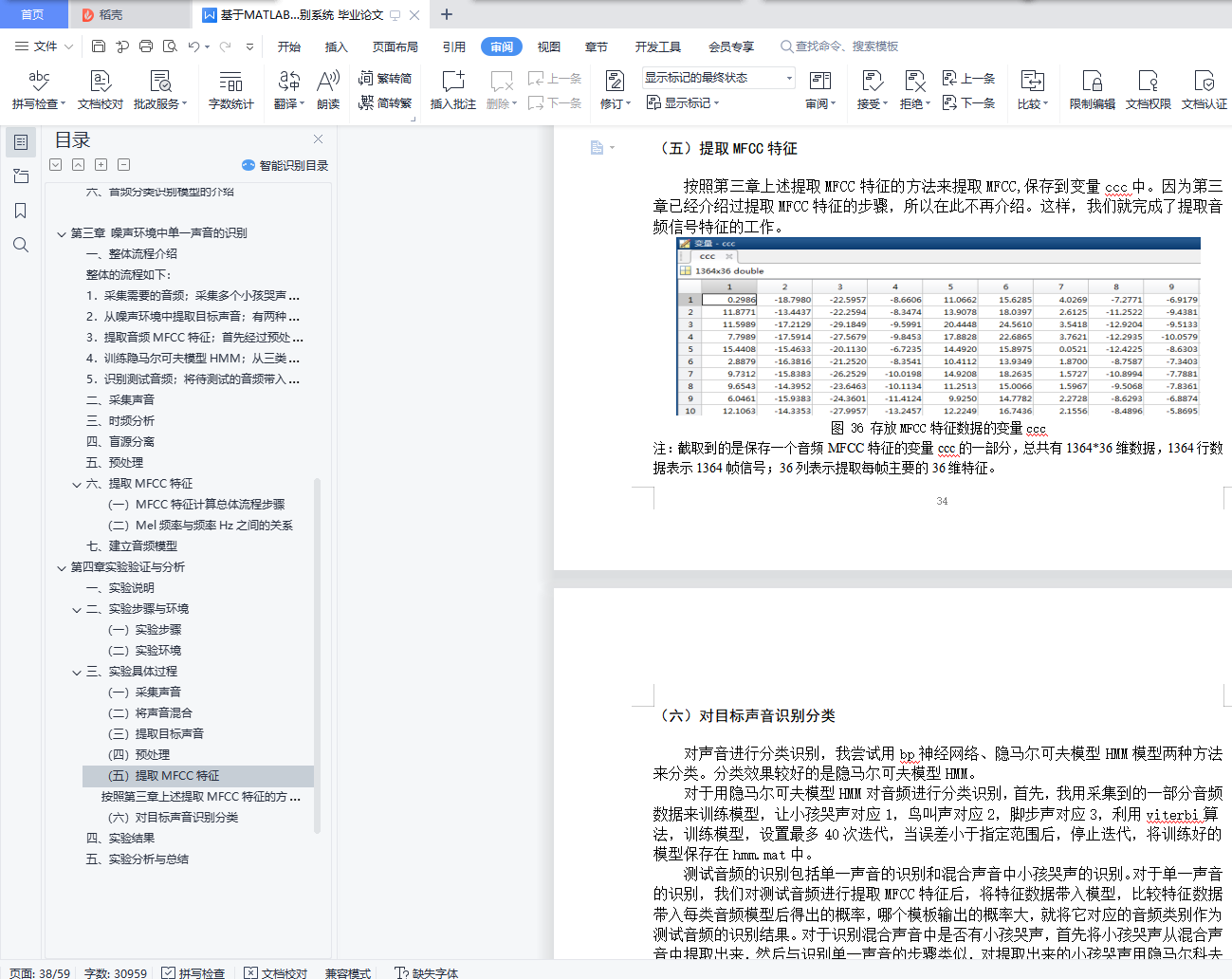
(五) 提取MFCC特征
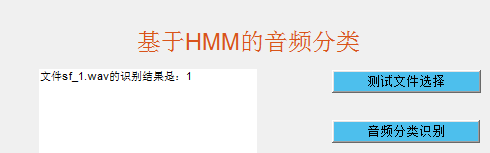
(六) 对目标声音识别分类
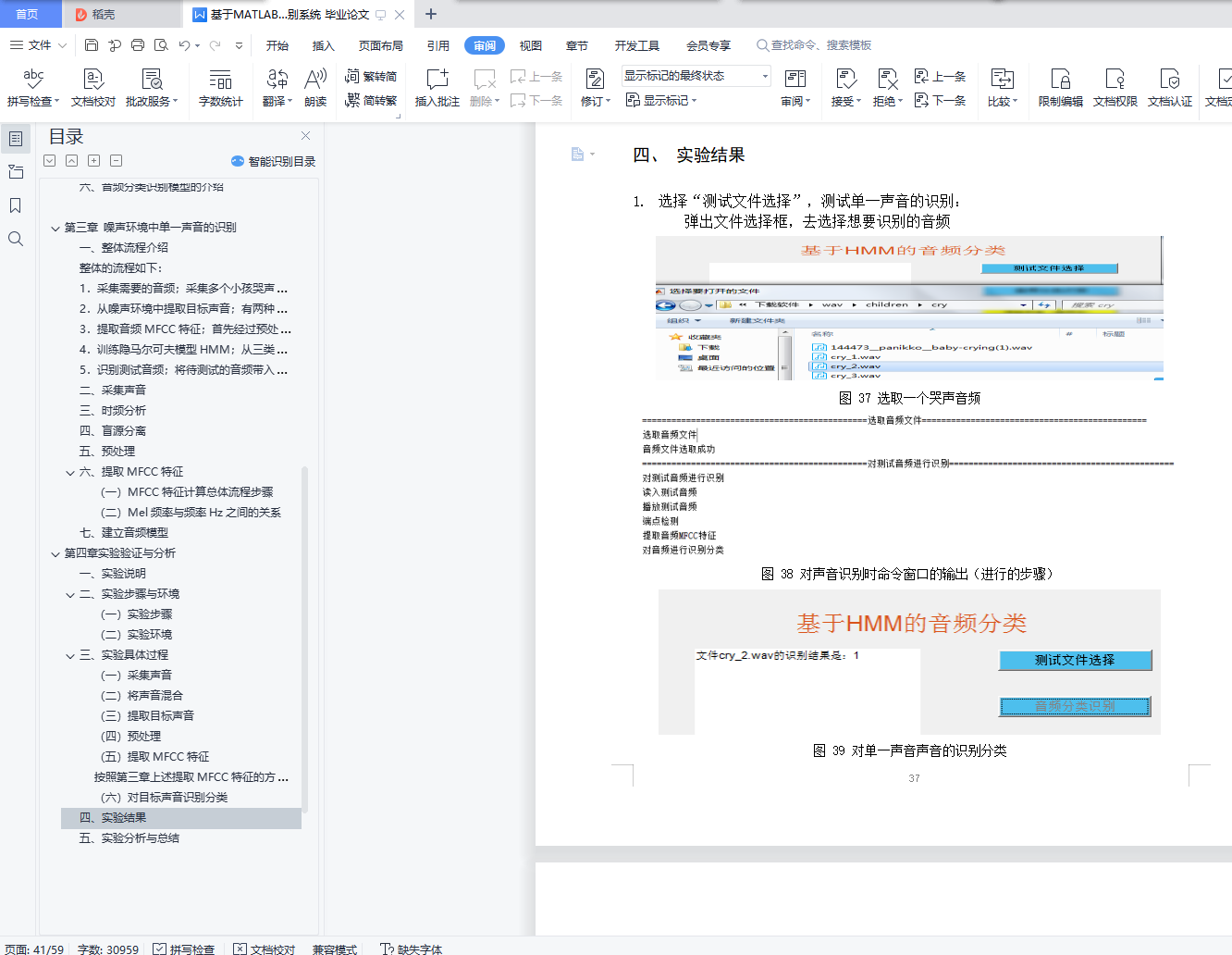
四、 实验结果
总结
参考文献
致 谢