摘 要
时代在发展,技术在进步,互联网改变了全世界,各行各业都在这个互联网时代寻求自身的增长点,人们的日常生活也越来越离不开互联网。
我国工商行政许可人口基数庞大,导致在互联网上寻找合适的工商行政许可成了人们不得不面对的问题。网络中提供工商行政许可信息的网站很多,用户寻找工商行政许可时往往由于使用习惯等原因主要在一个平台上寻找,若找不到心仪的工商行政许可,又将面临辗转各个工商行政许可信息平台,为用户带来不便。
笔者认为,对生活有实际意义的软件系统才称得上是一个好系统,结合以上背景,本系统实现一个基于Web爬虫技术的天眼查站工商行政许可信息爬取及展示系统。首先通过python开源爬虫框架scrapy对天眼查工商行政许可信息进行爬取,依据不同网页的不同特性选择不同的爬取策略,编写爬虫代码,过滤并抽取所需出工商行政许可源信息,建立以城市为区分的工商行政许可信息数据库。数据库部分采用非结构化数据库MongoDB,避免网上信息的非结构性对数据存储的影响。然后采用python开源网站搭建框架Django完成对爬取到的工商行政许可信息的web端展示。
关键词:工商行政许可;Web爬虫;Python;Scrapy;可视化
Abstract
The times are developing, technology is progressing, the Internet has changed the world, all walks of life are seeking their own growth point in this Internet era, people's daily life is more and more inseparable from the Internet.
China's industrial and commercial administrative license population base is huge, leading to the Internet to find the appropriate industrial and commercial administrative license has become a problem people have to face. There are many websites that provide industrial and commercial administrative license information in the network. When users look for industrial and commercial administrative license, they often look for it mainly on a platform because of their usage habits. Will also face each industry and commerce administrative license information platform, brings inconvenience to the user.
According to the author, the software system with practical significance to life can be called a good system. Combined with the above background, this system realizes a system of crawling and displaying the information of industrial and commercial administrative license based on Web crawler technology. Through the python of open source crawler framework scrapy the information of industrial and commercial administrative license is crawled, different crawling strategies are selected according to the different characteristics of different web pages, and crawler code is written. Filter and extract the information of industrial and commercial administrative license source, and establish the database of industrial and commercial administrative license information. Database part uses unstructured database MongoDB, avoid the influence of unstructured information on data storage. Then use python open source website to build a framework Django complete the crawling of industrial and commercial administrative license information web end display.
Keywords: industrial and commercial administrative license; Web crawler; Python;Scrapy; visualization
目 录
1 绪论
1.1 选题背景及意义
1.1.1选题背景
1.1.2目的及意义
1.2 国内外发展现状
1.2.1 爬虫技术现状
1.2.2 工商许可信息发展现状
1.3 研究主要内容
1.4 章节安排
2 系统开发环境及技术介绍
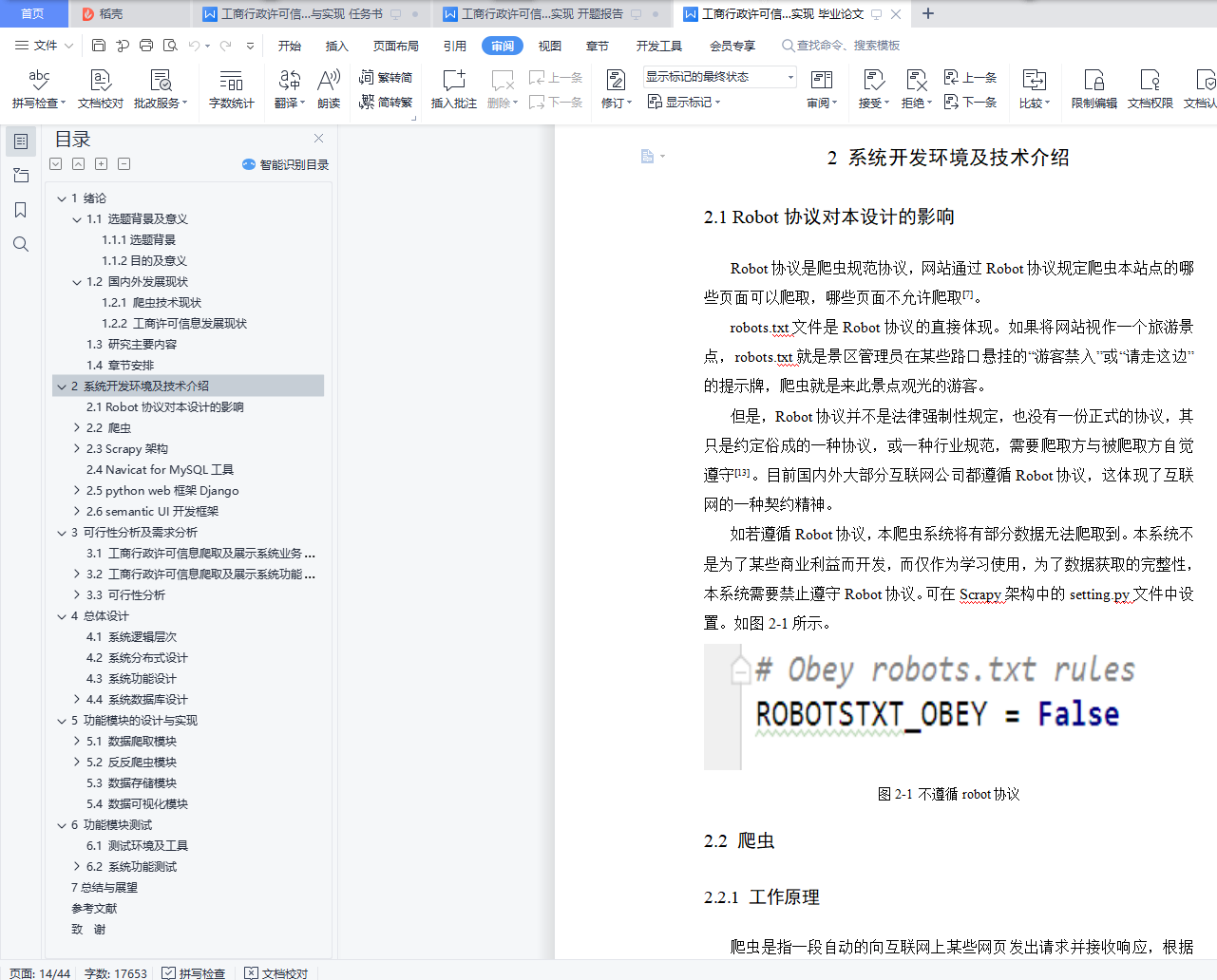
2.1 Robot协议对本设计的影响
2.2 爬虫
2.2.1 工作原理
2.2.2 工作流程
2.2.3 抓取策略
2.3 Scrapy架构
2.3.1 Scrapy:开源爬虫架构
2.3.2 Scrapy框架结构
2.3.3 两种继承的爬虫模式
2.4 Navicat for MySQL工具
2.5 python web框架Django
2.5.1 Django框架介绍
2.5.2 MTV模式
2.5.3 ORM模式
2.5.4 template模板语言
2.5.5 Django工作机制
2.6 semantic UI开发框架
2.6.1 semantic介绍
2.6.2 semantic开发
3 可行性分析及需求分析
3.1 工商行政许可信息爬取及展示系统业务需求分析
3.2 工商行政许可信息爬取及展示系统功能性需求分析
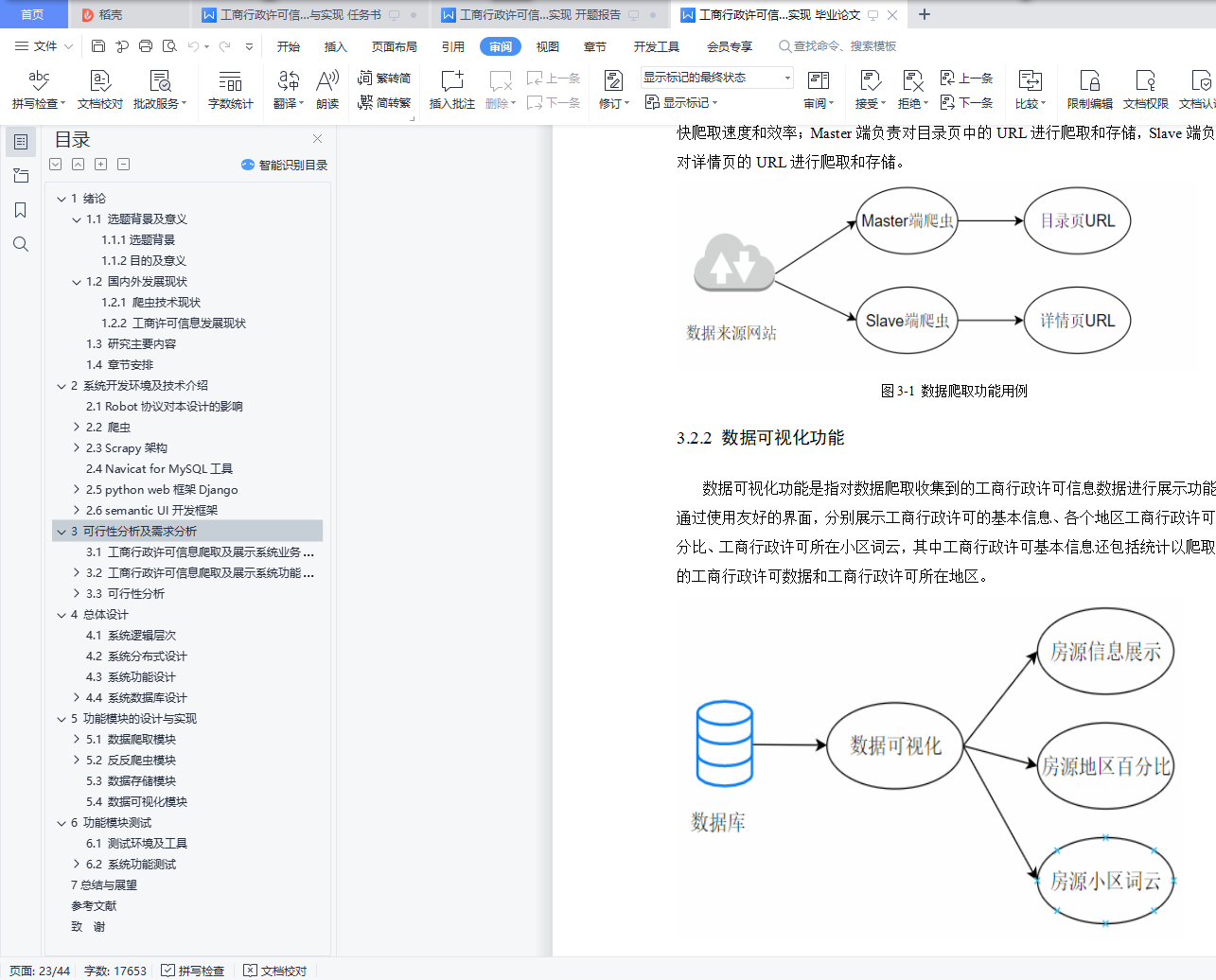
3.2.1 数据爬取功能
3.2.2 数据可视化功能
3.3 可行性分析
3.3.1 技术可行性
3.3.2 经济可行性
3.3.3 法律可行性
4 总体设计
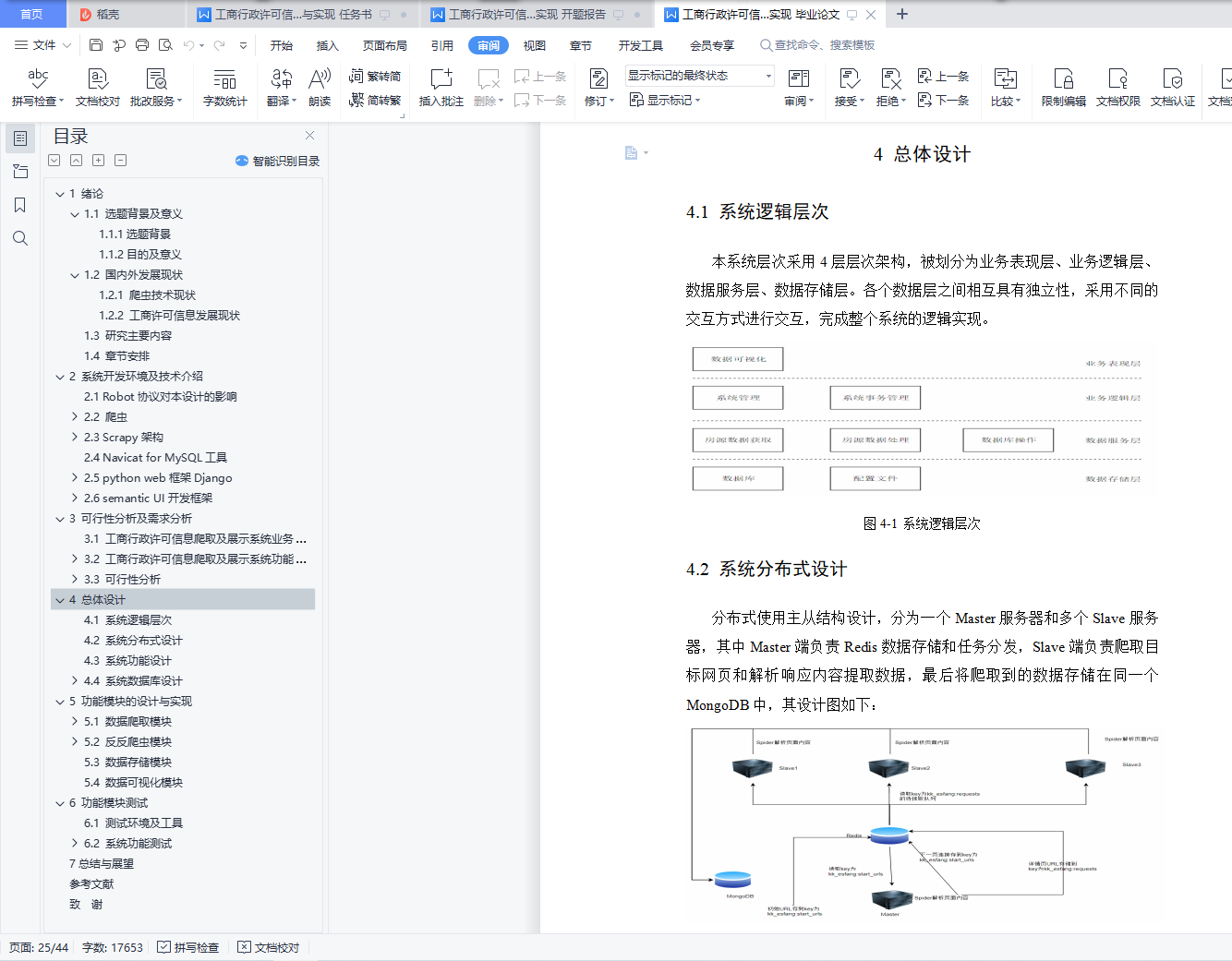
4.1 系统逻辑层次
4.2 系统分布式设计
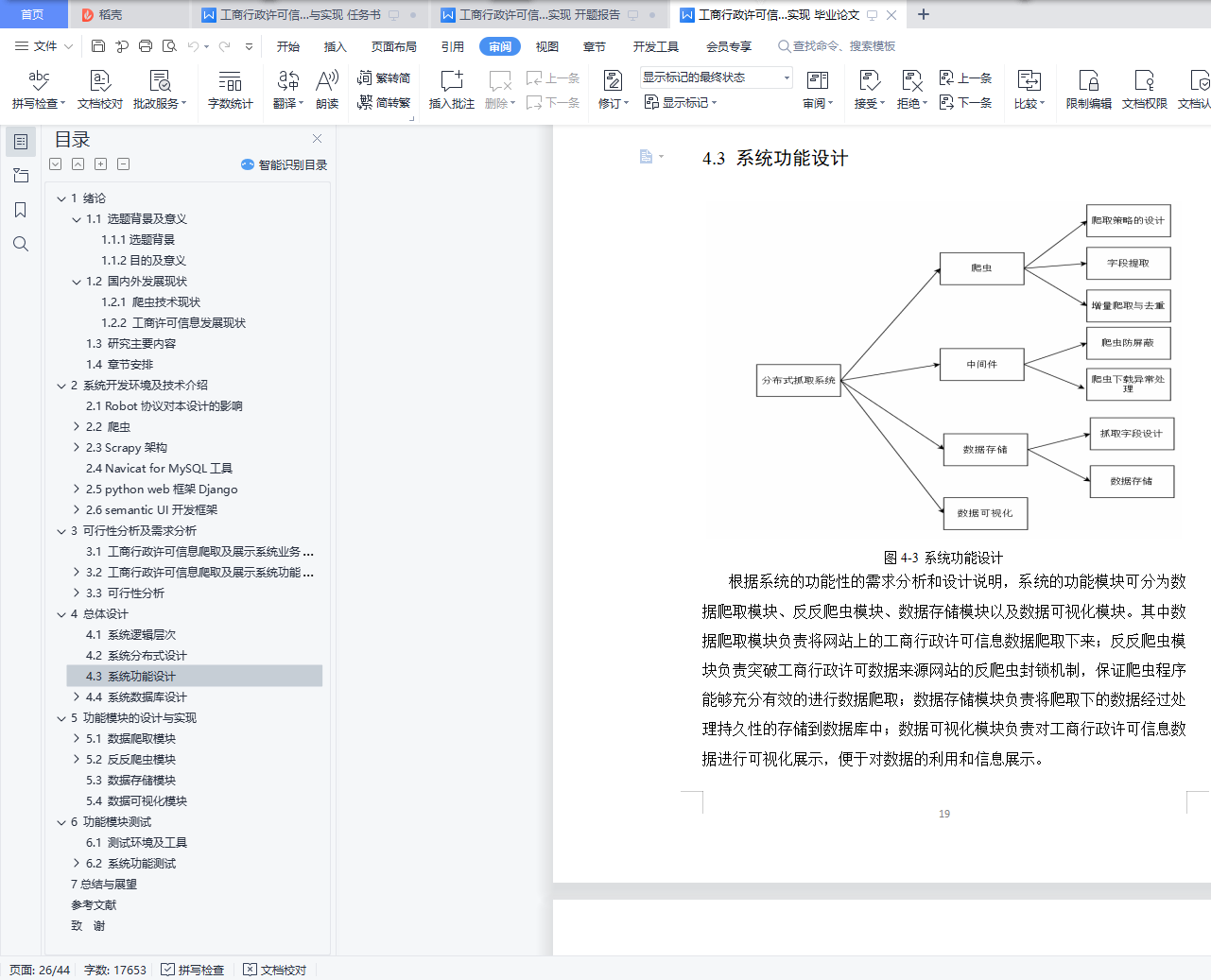
4.3 系统功能设计
4.4 系统数据库设计
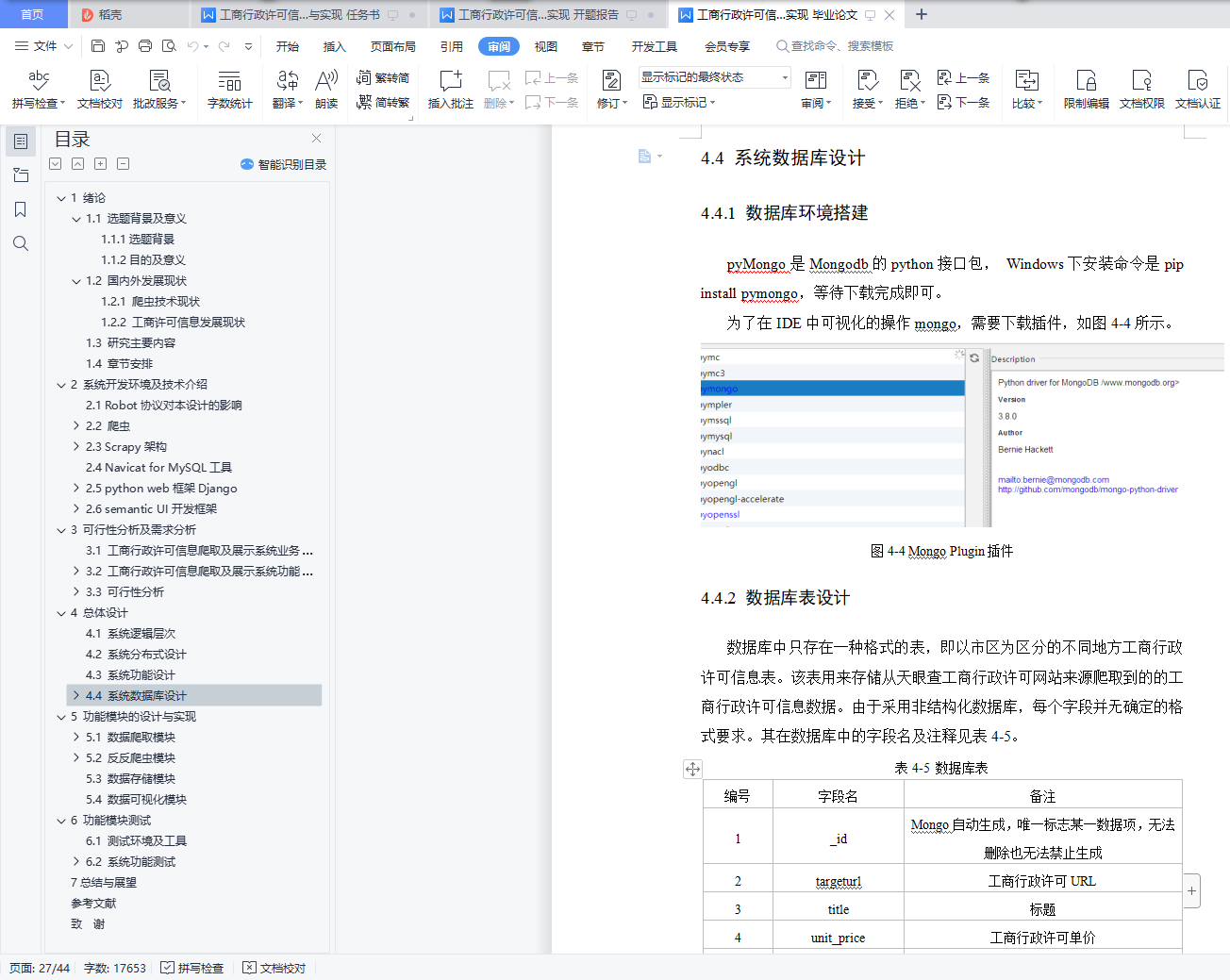
4.4.1 数据库环境搭建
4.4.2 数据库表设计
5 功能模块的设计与实现
5.1 数据爬取模块
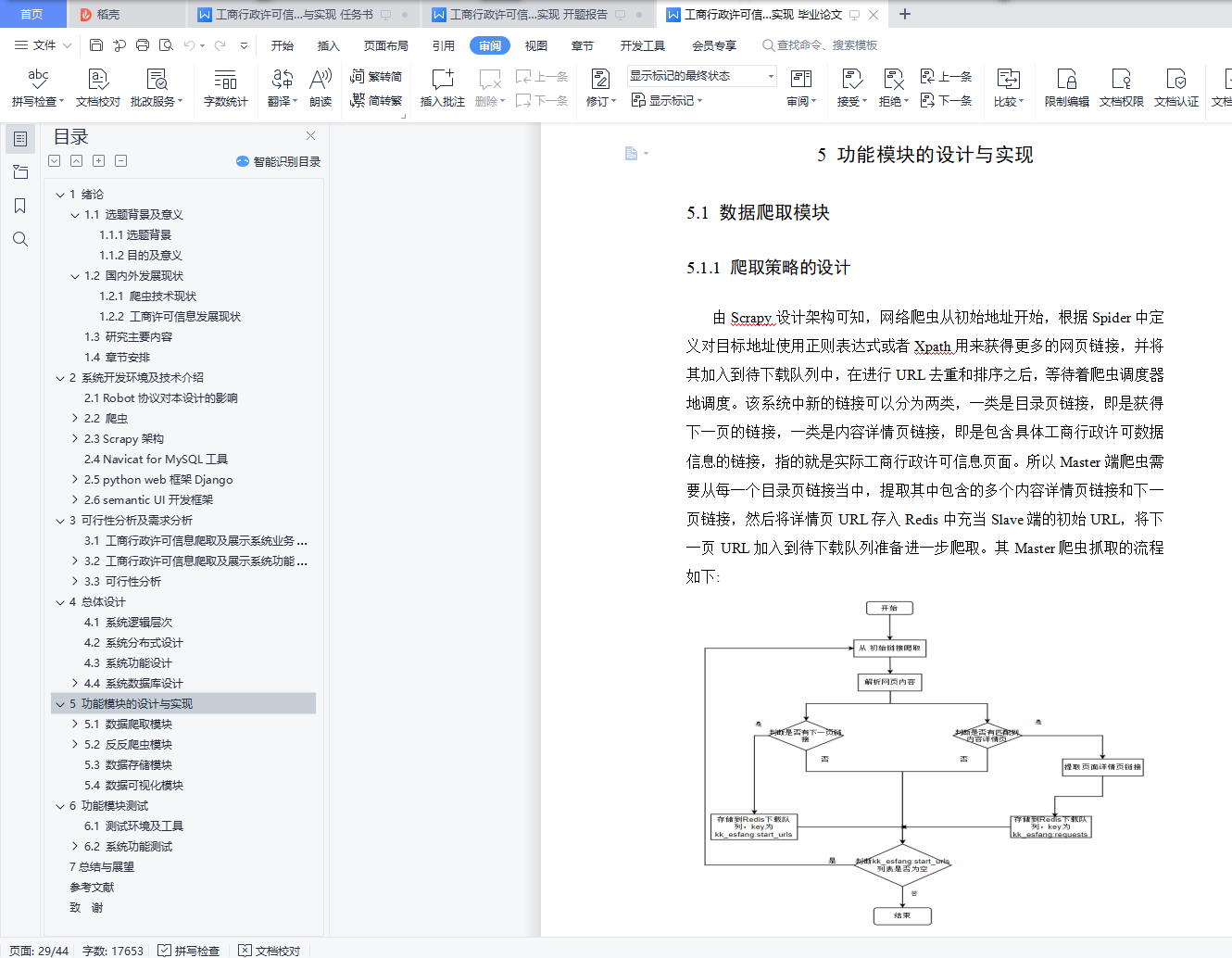
5.1.1 爬取策略的设计
5.1.2 网页数据提取
5.1.3 去重与增量爬取
5.2 反反爬虫模块
5.2.1 模拟浏览器行为
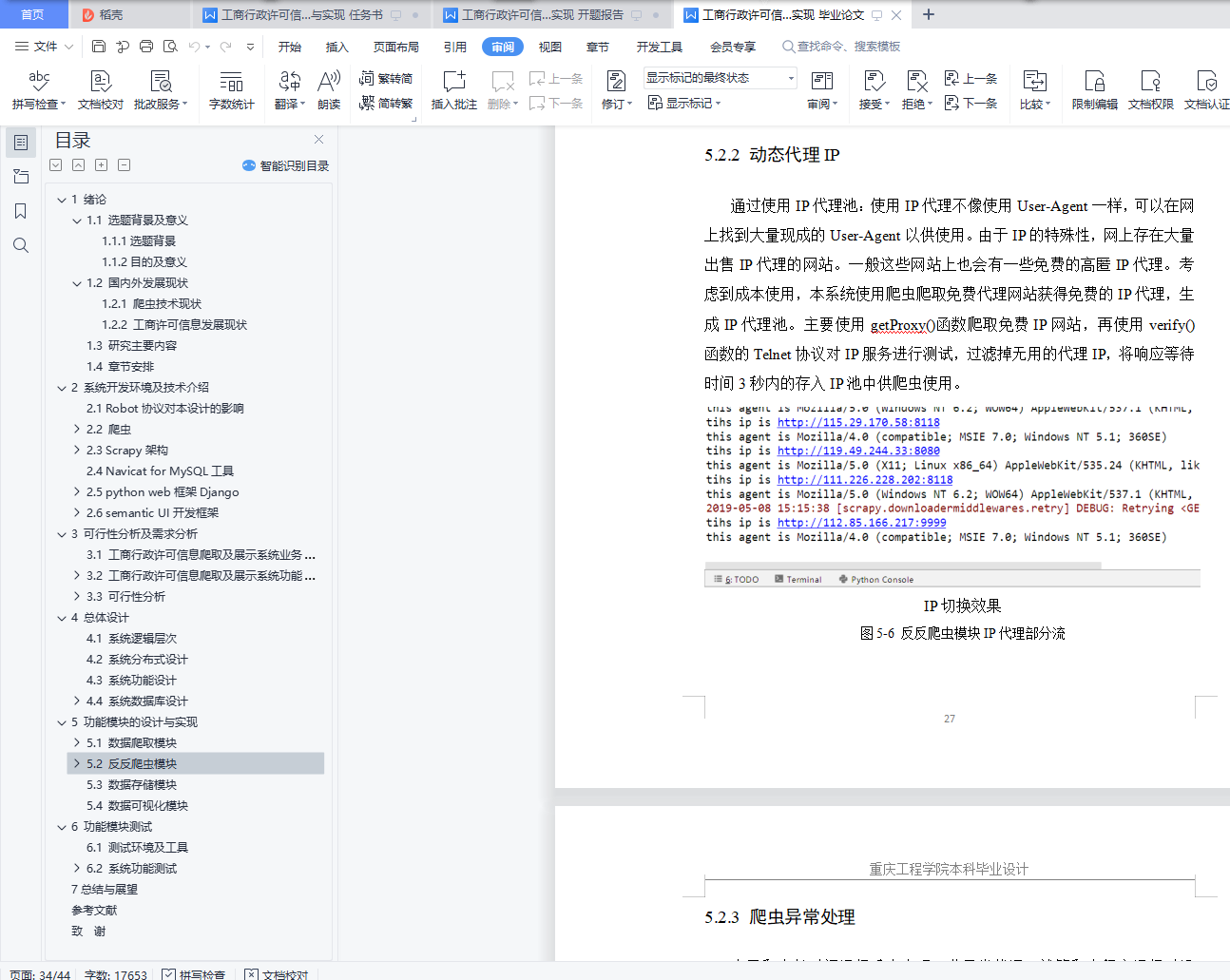
5.2.2 动态代理IP
5.2.3 爬虫异常处理
5.3 数据存储模块
5.4 数据可视化模块
6 功能模块测试
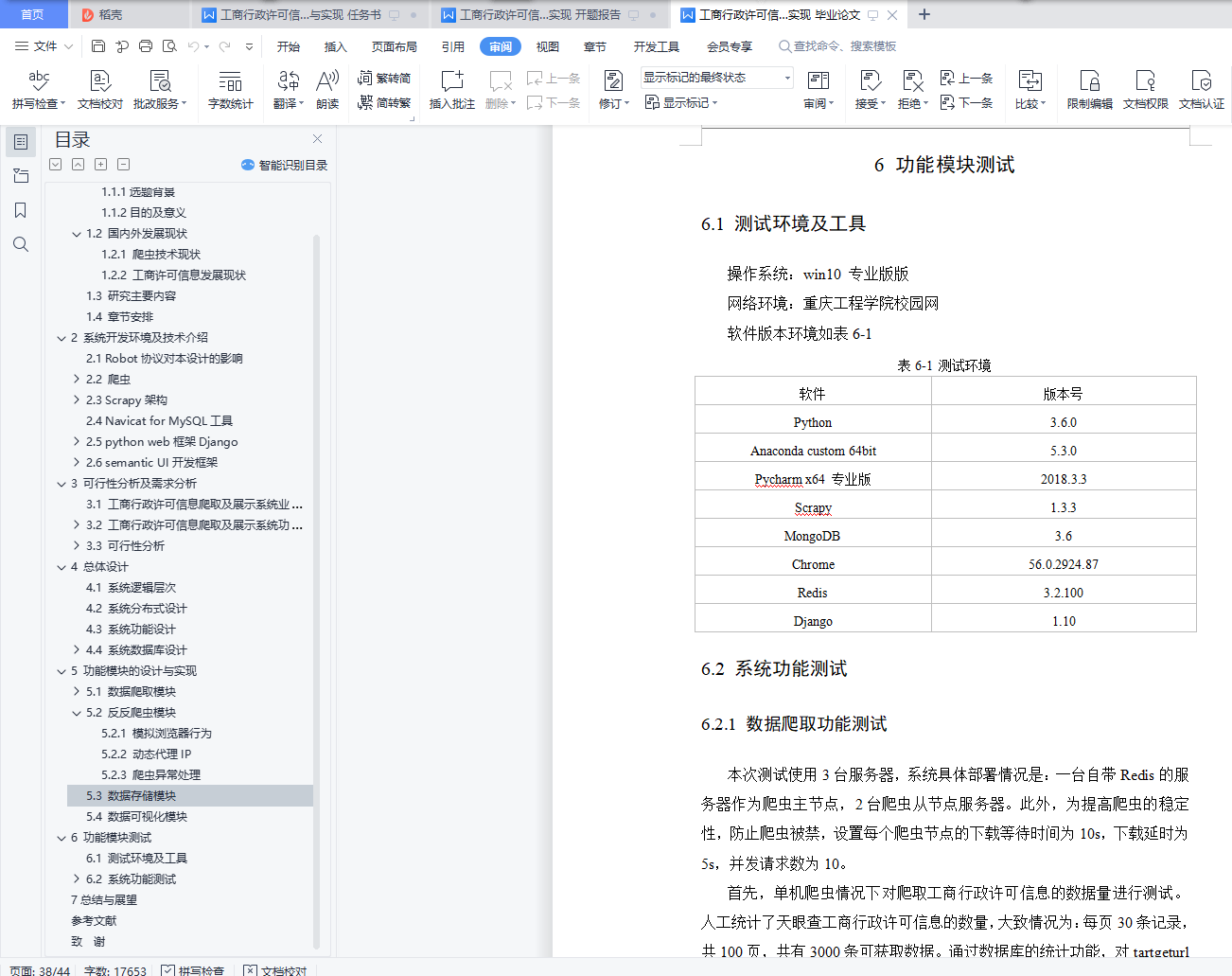
6.1 测试环境及工具
6.2 系统功能测试
6.2.1 数据爬取功能测试
6.2.2 数据存储功能测试
6.2.3 数据反反爬虫功能测试
6.2.4 数据可视化功能测试
7总结与展望
参考文献
致 谢