摘 要
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了,人们对信息的获取逐渐被网络所取代。目前,人们大多通过搜索引擎获得有用的信息,因此,搜索引擎技术的发展将直接影响人们获得所需信息的速度和质量。
在很大程度上,Web搜索引擎、数字图书馆和其他Web应用都依赖于网络爬虫获取的HTML文档信息。例如为了提供多种搜索引擎服务,谷歌、雅虎和MSN的爬虫定期遍历数十亿网页,网络购物智能代理通过价格比较未用户推荐价格优惠的产品。本文通过爬取影视数据通过分析让为用户观影时提供决策支持。
关键词:爬虫;电影;抓取;分析
1 网络爬虫的背景及研究现状
1.1 网络爬虫的背景
进入 21世纪,特别是第二个十年,世界互联网取得了惊人的快速发展。根据分析师玛丽・米克尔 (Mary Mikel) 2016年发布的一份互联网趋势报告,到2016年年中,全球互联网用户超过30亿,约占全球总人口的40%,中国超过6.9亿互联网用户维持了多年来全球最大的互联网用户市场。互联网的快速发展,同时互联网产生的数据量也随着互联网用户的不断涌入而产生了爆炸性的增长,世界进入了"大数据"时代。欧洲最大的电子优惠券应用提供商Vouchercloud在2015年发布的一份报告显示,每天在互联网上生成的数据高达2.5万亿字节 (五分之一字节),这些数据可以充满超过1亿张蓝光光盘 (25GB)容量)。因此,如何在互联网上查询海量信息中的有价值数据,成为一个需要解决的问题。
作为搜索引擎技术核心元素之一,网络爬虫源于上个世纪90年代的Google等搜索引擎,爬虫用于抓取互联网上的Web页面,再由搜索引擎进行索引和存储,从而为我们提供检索服务。网络爬虫位于搜索引擎的后台,并未直接与用户接触,属于幕后技术,因此在较长的时间内并未被广大开发人员所关注。
2005年以来,人们对网络爬虫技术的关注度快速上升。其中,很大的推动力来自于各种个人、中小型爬虫。爬虫是一个实践性很强的技术活,互联网上爬虫数量的增长速度剧增。爬虫技术历经20多年的发展,技术已日趋多样。
1.2 网络爬虫的研究现状
随着网络信息资源的指数化增长和网络信息资源的动态变化,传统搜索引擎提供的信息检索服务已不能满足人们对个性化服务日益增长的需求,正面临着巨大的挑战。以什么样的网络接入策略,提高搜索效率,已成为近年来专业搜索引擎网络爬虫研究的主要问题之一。
网络爬虫是搜索引擎的重要组成部分,目前比较流行的搜索引擎有百度、谷歌、雅虎、必应等,可以说没有网络爬虫的存在,就可能没有搜索引擎的存在,出于商业保密的考虑,各种搜索引擎使用的爬虫系统的技术内部人员一般不公开,现有文献仅限于摘要介绍。
2 Python及Pycharm简介
2.1 Python简介
Python是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。Python的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。Python语言是人工智能和大数据的标准语言,随着云计算、大数据、物联网、人工智能、区块链等技术被广泛应用于各行各业。自20世纪90年代Python语言公开发布以来,由于其语法简洁、类库丰富,适用于快速开发活动,已经成为当下较为流行的一种脚本语言。Python语言具有强大的数据分析功能,可以应用到网站开发、图像处理、数据统计和可视化表达等多个领域。
2.2 Pycharm简介
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
3 运行环境和系统结构
运行环境:Windows操作系统下的Python3环境。
系统结构:本爬虫系统分为数据爬取模块(爬取豆瓣TOP250排行榜以及电影详细数据)、数据分析模块(数据预处理及分析)、数据可视化模块(词云展示以及绘图展示),如图3.1所示。
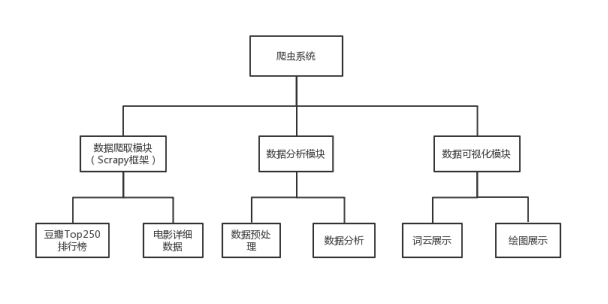
图3.1 系统结构
4 结语
通过完成了简单的爬虫,更重要的是学习了许多重要的知识。整个过程中,涉猎了Scrapy的使用、Scrapy对接Selenium、分布式爬虫原理、Scrapy分布式实现、Scrapy-Client的使用等爬虫相关技术。不仅学会了很多概念性的知识,还极大地锻炼了动手能力,发现错误,不厌其烦地寻找错误根源并想办法去解决问题的能力,还丰富了学识和见解。相信给以后的学习和生活中能够带来十分多的帮助和支持。
参考文献
[1]安子建. 基于Scrapy框架的网络爬虫实现与数据抓取分析[D].吉林大学,2017.
[2]赵绿草,饶佳冬.基于python的二手房数据爬取及分析[J].电脑知识与技术,2019,15(19):1-3.
[3]孙瑜. 基于Scrapy框架的网络爬虫系统的设计与实现[D].北京交通大学,2019.
[4]丁忠祥,杨彦红,杜彦明.基于Scrapy框架影视信息爬取的设计与实现[J].北京印刷学院学报,2018,26(09):92-97.
[5]韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019,29(02):139-142.
[6]李刚.疯狂Python讲义[M].电子工业出版社,2018,12(01).
