摘 要
近年来,互联网技术的高速发展,行业竞争也越来越激烈,行业发展形势也形成了改变,网络的高速发展,深刻改变了企业的生产、经营、管理模式,据调查传统行业所受影响稍微较小,而电商等行业正在发展向上。
当今中国上市公司也需要对数据进行分析和处理,而我国大多上市公司对数据方面还不怎么敏感,因为我国相比其他国家可能对大数据更晚发展,所以现在我们需要发展,需要更多的人来研究对数据的准备、挖掘和分析等。数据挖掘是人工智能和数据库领域研究的热点问题。而本次研究我将对上市公司的数据进行采集和研究。
本文采用python和java结合的方法实现对上市公司数据的采集和分析,通过python对上市公司的公开数据进行采集,然后存入mongodb数据库,通过java构建一个系统,实现通过java调用python来实现实时的采集数据,然后利用采集到的数据对行业发展进行分析。通过CR4来计算行业的集中度,来建议未来创业者的选择。
关键词:数据挖掘 java系统 行业发展
ABSTRACT
In recent years, with the rapid development of Internet technology, the industry has become increasingly competitive and the development of the industry has also changed. The rapid development of the net has changed the company's production management model deeply. According to the survey, the traditional industry has little influence, and the rate of industrial development such as electronic commerce is faster.
The present Chinese society is in the age of computerization, and information technology has already permeated in the Chinese society. Listed companies need data analysis and processing, but many listed companies in China are not very sensitive to data. The development of big data in Japan may be slower than other countries, so development is now needed. More people need to prepare, excavate and analyze data. Data mining is a hot spot problem in artificial intelligence and database research. Data mining refers to a particular process for disclosing information about the earlier unknown and potentially valuable information hidden from large database data. This study collects and collects data of listed companies.
In this paper, we collected and analyzed the data of the listed company in a combination of Python and Java. Through python, collect the public data of the listed company and store it in the mongodb database. A Java based system calls Python through Java and realizes data collection. We analyze the development of the industry using the collected data. Cr4 is used to calculate industry centralization and suggests the choice of future entrepreneurs.
Keywords: Data mining;Java System;Industry Development
目 录
摘 要
ABSTRACT
1 绪 论
1.1 数据挖掘的发展历史
1.2 本课题的研究意义
1.3 国内外的现状
2 系统相关理论基础
2.1 体系结构
2.2 Freemarker简介
2.3 Jpa的简介
2.4 Mongodb简介
3 数据采集scrapy
3.1 什么是scrapy
3.2 scrapy的优点
3.3 中间件的运用
3.4 验证码的处理
3.5 采集的方式
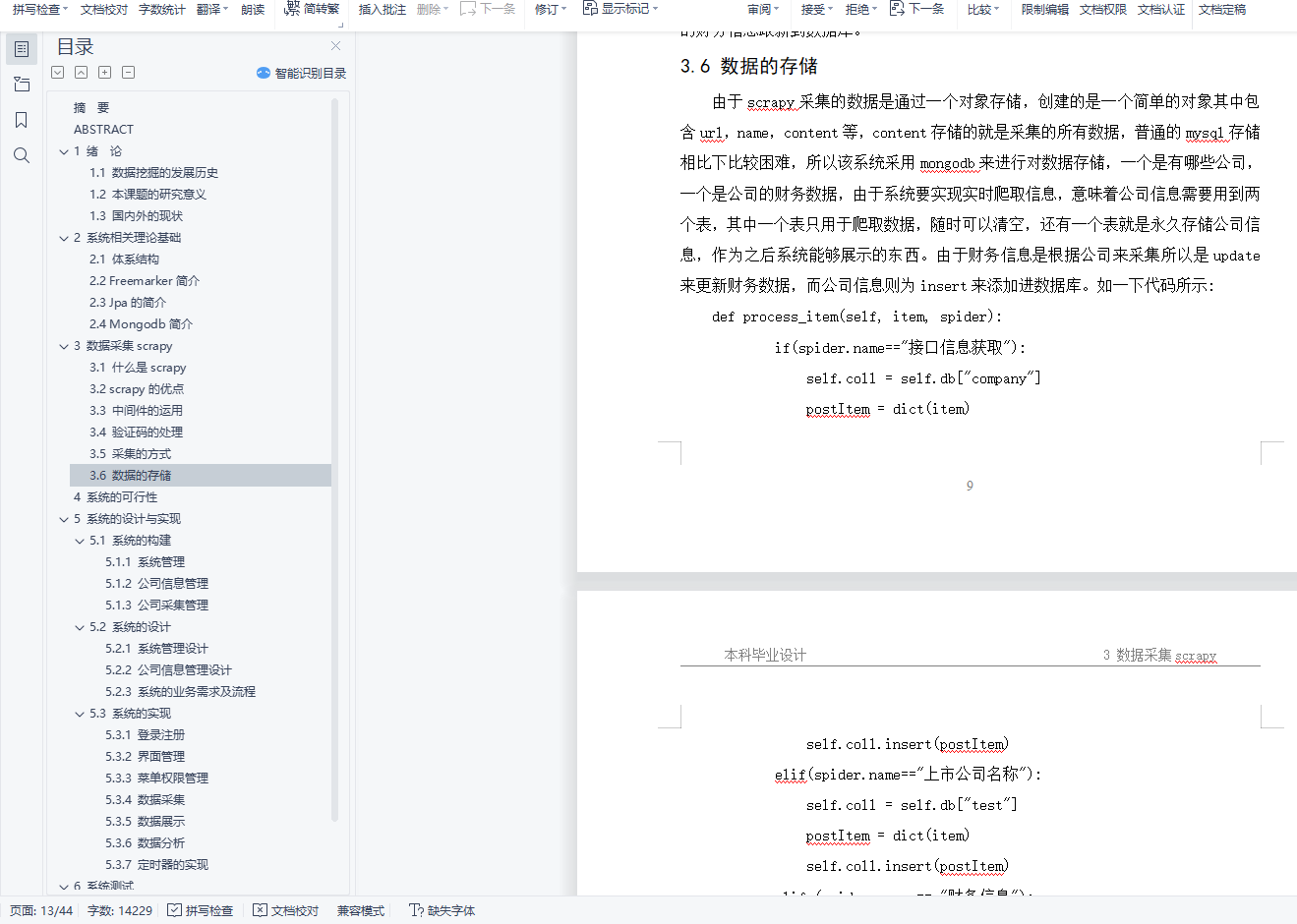
3.6 数据的存储
4 系统的可行性
5 系统的设计与实现
5.1 系统的构建
5.1.1 系统管理
5.1.2 公司信息管理
5.1.3 公司采集管理
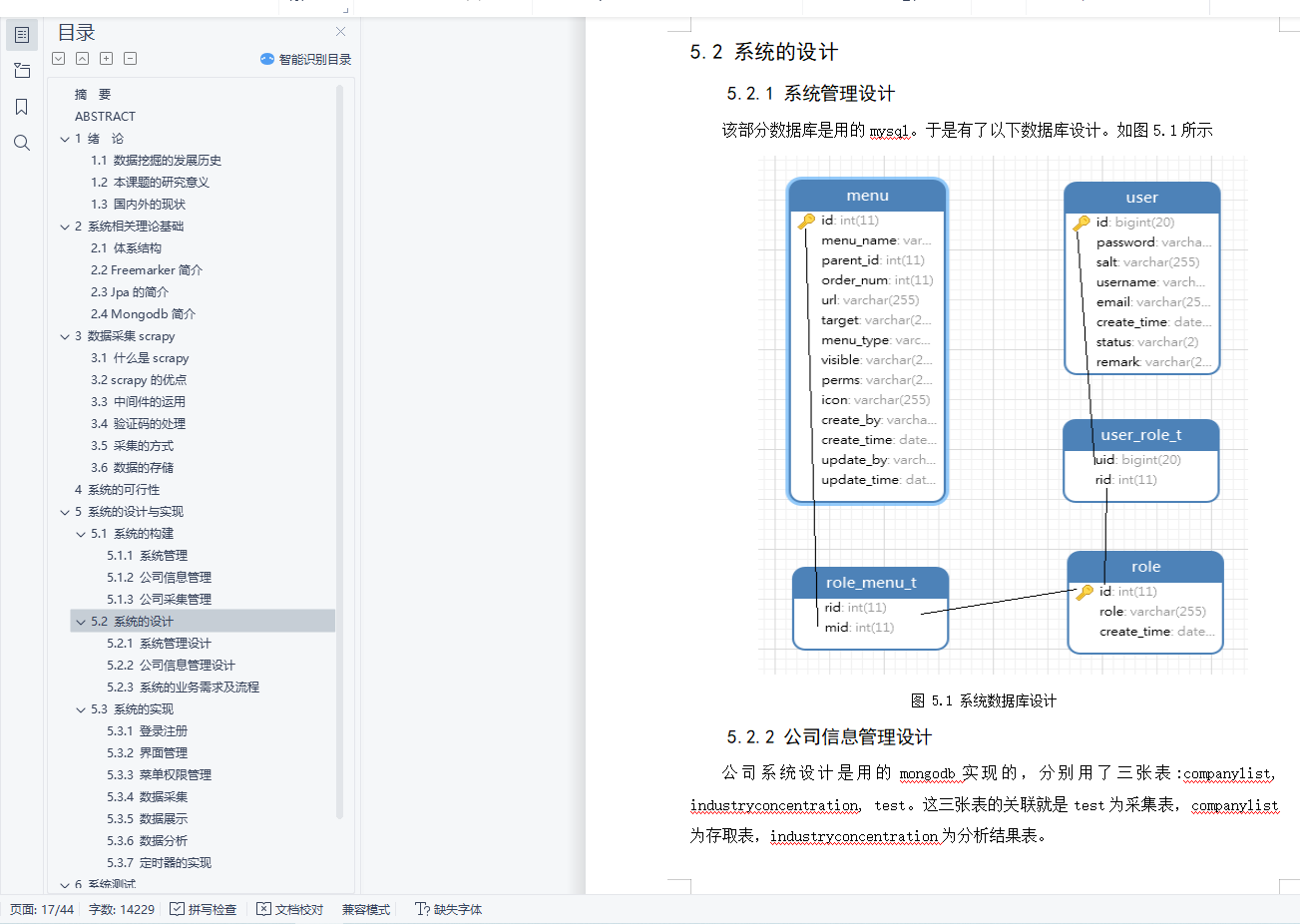
5.2 系统的设计
5.2.1 系统管理设计
5.2.2 公司信息管理设计
5.2.3 系统的业务需求及流程
5.3 系统的实现
5.3.1 登录注册
5.3.2 界面管理
5.3.3 菜单权限管理
5.3.4 数据采集
5.3.5 数据展示
5.3.6 数据分析
5.3.7 定时器的实现
6 系统测试
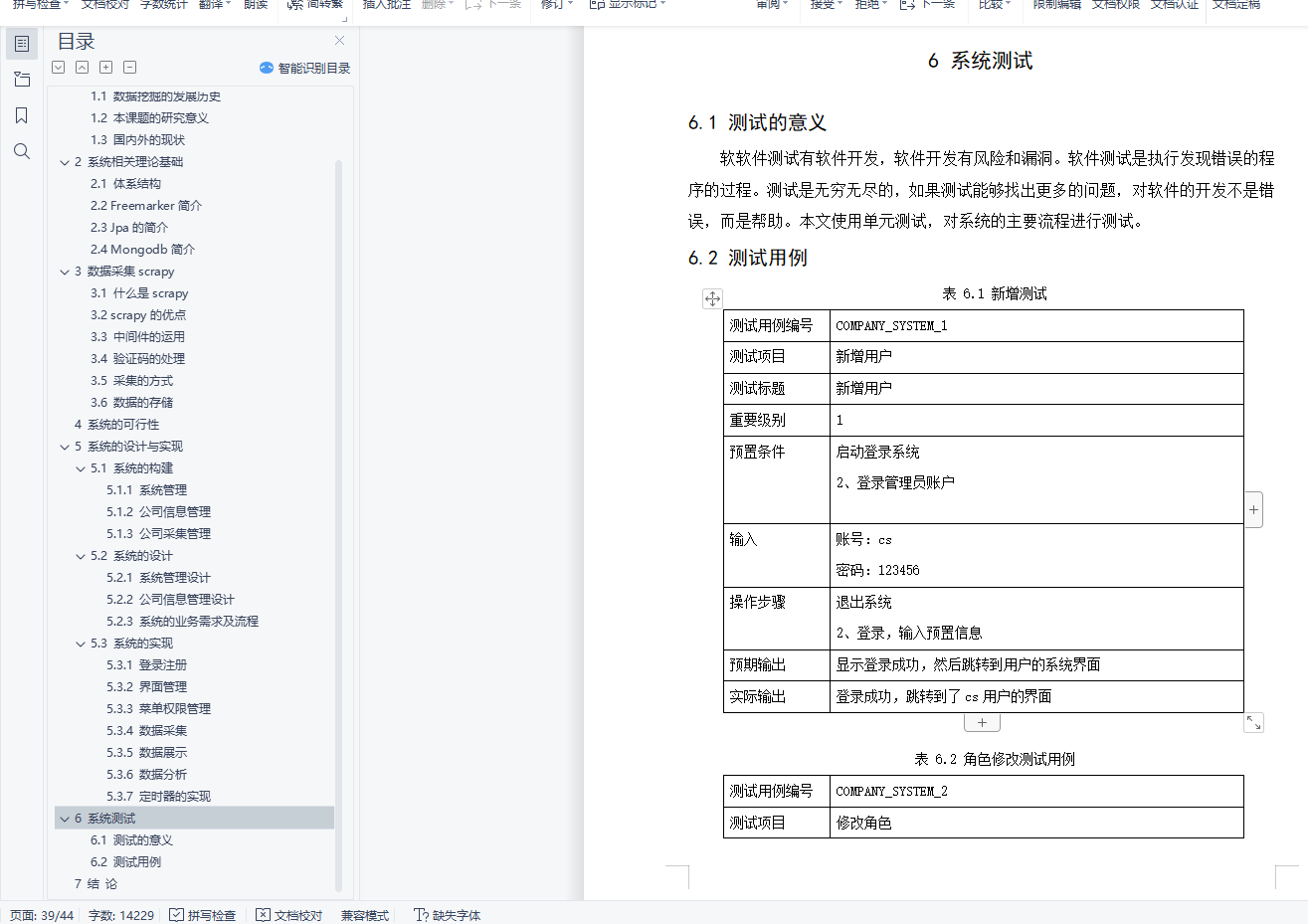
6.1 测试的意义
6.2 测试用例
7 结 论