实验报告
任务一名称:应用Python软件爬虫抓取豆瓣Top250排行榜影片数据
一、 实验目的
1.掌握各类HTTP调试器用法
2.理解网络爬虫编写的基本套路
3.了解网络爬虫编写的各种陷阱
4.能够应对动态网站爬取
5.能够应对带有验证码的网站
6.能够应对需要浏览器渲染的网站
7.能够应对分布式抓取需要
8.能够应对反爬虫技术
9.能够应对无界面抓取
10.能够利用爬虫平台
二、 实验环境
1、运行环境和系统结构
运行环境:Windows操作系统下的Python3环境。
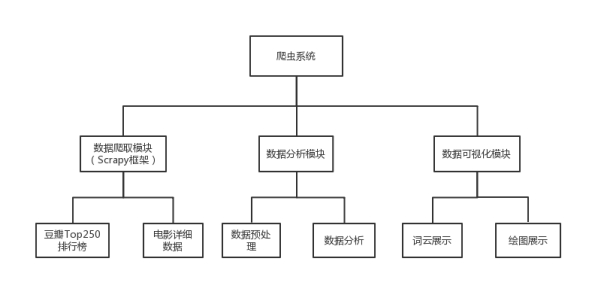
系统结构:本爬虫系统分为数据爬取模块(爬取豆瓣TOP250排行榜以及电影详细数据)、数据分析模块(数据预处理及分析)、数据可视化模块(词云展示以及绘图展示),如图所示。
2、环境搭建
(1)从官网下载python3安装包,官网:
https://www.python.org/。
(2)安装python,并配置环境变量:(安装时勾选加入Path,即可自动配置好环境变量。)此电脑-属性--高级系统设置--环境变量--系统变量--path--新建--(找到自己的python位置,一般是在C盘,复制路径,粘贴进入新建,分隔号是“;”,然后一直点确认就行了。)上面是win10的操作流程,如果是win7的话,直接在点击path,下面一条上加一个;后面加c:\python3就可以了。
(3)从官网下载pycharm安装包,官网:
http://www.jetbrains.com/,安装pycharm。
(4)pycharm关联python,并配置国内镜像源:File--setting--选择Project:xxx--下拉选择Project Interpreter--然后在Proect Interpreter:栏里选择(如果没有选择的话,点show all然后添加自己python安装路径下的python.exe),接着点击右侧加号点击Manage Repositories,最后删除原有路径,添加清华镜像源(改成国内镜像源可以在安装库时避免一些错误):
https://pypi.tuna.tsinghua.edu.cn/simple。
三、 实验内容及步骤
1、设计思路:
用Python的Scrapy框架编写爬虫程序抓取了Top250排行榜的影片榜单信息,爬取电影的短评、评分、评价数量等数据,并结合Python的多个库(Pandas、Numpy、Matplotlib),使用Numpy系统存储和处理大型数据,中文Jieba分词工具进行爬取数据的分词文本处理,wordcloud库处理数据关键词,最终通过词云图、网页动态图展示观众情感倾向和影片评分统计等信息。流程如图所示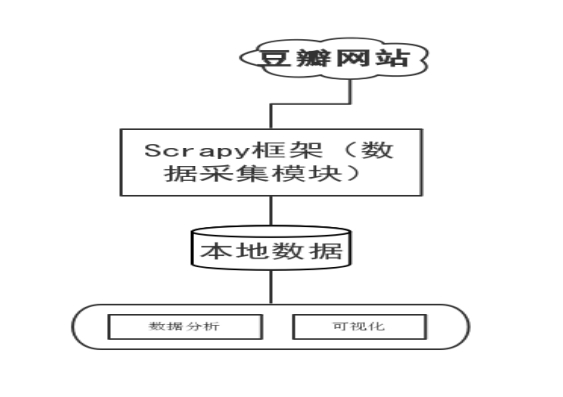
2、影视数据爬取:
(1)新建Python项目
用Pycharm新建“基于Python的影视数据爬取和分析”的python项目。项目中主要运用到的库和在项目中的作用,如表所示:
|
主要库
|
作用
|
|
Scrapy
|
核心,用来爬取豆瓣影视数据
|
|
jieba
|
对影评数据进行分词处理
|
|
wordcloud
|
对影评数据可视化
|
|
matplotlib和pygal
|
将分析后的影视数据可视化
|
(2) 项目里安装Scrapy
直接用Pycharm安装Scrapy,具体步骤是:File--setting--选择Project:xxx--下拉选择Project Interpreter--然后选择右边“+”搜索Scrapy,按Install Package进行安装。
(3) 豆瓣电影top250网站分析
使用谷歌浏览器对目标网站进行分析,本毕设所爬取的网站是豆瓣电影Top250排行榜网站,网址:https://movie.douban.com/top250 。用谷歌浏览器打开如图所示:
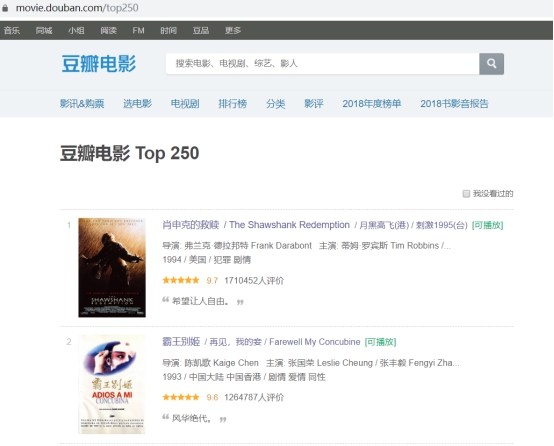
可以看出该网站上有电影名字、电影封面图片,电影导演、电影排名、电影主演(不完整)等基本信息,但这不是我们要爬取的,接着打开每个电影链接可以看到更详细的数据如图
我们确定了要爬取的详细信息(排名、名字、又名、评分等等),并且是每一部电影都要爬取这些详细信息,而这种在索引页中的每个条目的详细信息叫纵向爬取。
接着我们在返回上一级网站(top250排行榜),看到最底部,如图所示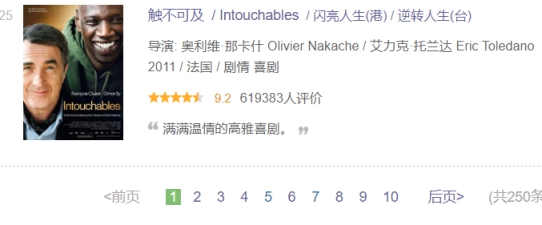
可以发现该网页有25部电影,而本毕设的目标是top250排行榜上所有电影,所以我们还需要爬取下一页,在分页器里跳转到下一页这种叫横向爬取。
通过分析,我们可以初步确定要爬取的网站要使用双向爬取。
(4) 创建一个Scrapy项目
在建好的项目里直接用scrapy命令生成scrapy项目,命令:scrapy startproject DouBanTop250
这个命令可以在任意文件夹运行。如果提示权限问题,可以加sudo运行该命令。这个命令将会创建一个名为“DouBanTop250”的文件夹。
(5) 创建一个Spider
创建Spider有两个方法。
一个是自己定义一个类(要继承Spider类,还要定义各种属性,初始请求,处理方法。);
另外一种方法是用scrapy命令创建Spider,本毕设使用这种方法创建Spider。由于前面网页分析已经初步确定了要使用双向爬取来爬取豆瓣top250。
那么就应该创建一个CrawlSpider(Spider的派生类,用来做双向爬取是比较适合的。),创建一个CrwalSpdier需要制定一个模板,可以用命令scrapy genspider -l来看有哪些可用模板,运行结果:
Available templates:
basic
crawl
csvfeed
xmlfeed
创建普通spider时默认使用第一个模板basic,要创建CrawlSpider需要使用第二个模板。
创建命令scrapy genspider -t crawl top250 movie.douban.com
使用前需要进入到4.5.4步骤创建的文件夹里。top250是创建的CrawlSpider名字,movie.douban.com是Spider爬取链接的域名(在此域名内的链接都有效)。
(6) 定义Rule
Rules是CrawlSpider的属性,是爬取规则属性,是包含一个或多个Rule对象的列表。每个Rule对爬取网站的动作都做了定义,CrawlSpider会提取Rules的每一个Rule并进行解析。
首先将start_urls修改为豆瓣top250排行榜的链接,这是起始链接,代码如下所示:
start_urls=['https://movie.douban.com/top250?start=0&filter=']
Spider会爬取start_urls里的每一个链接,所以第一个爬取页面就是刚才定义的排行榜链接。得到Response(响应)就会根据每一个Rule来提取这个页面内的超链接,去生成进一步的Request(请求),接下来,就是定义Rule来指定提取那些链接。起始链接页面如图4.4所示,
下一步就是获取,每一部电影的超链接,使用谷歌浏览器按F12查看源代码,查看电影链接,如图所示。
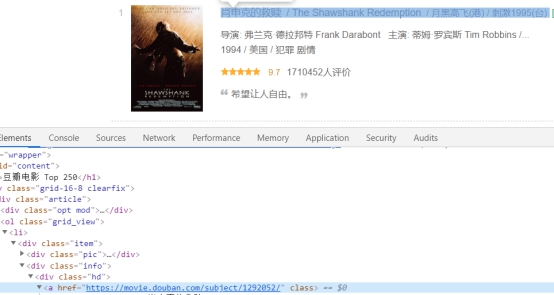
可以看到电影链接是以“subject”开头的,然后链接又在属性为“class=info”的div下。现在可以构造出一个Rule了,用于横向爬取,需要注意的是这个Rule需要指定一个回调函数(用于爬取电影详细信息)。
代码如下所示:
Rule(LinkExtractor(allow='subject\/\d*\/',restrict_xpaths='//div[@class="info"]//div'),callback='top250_parse_item')
LinkExtractor是链接提取器,其属性allow是正则表达式,提取符合要求链接,restrict_xpaths定义当前页面中XPath匹配的区域,是XPath表达式。callback是回调函数,提取链接后该函数会被调用,不能用parse()方法来实现,因为CrawlSpider用parse()来实现逻辑了。
另一个Rule的定义就不详细说明了,定义完的代码如下所示:
rules=(
Rule(LinkExtractor(allow='subject\/\d*\/',restrict_xpaths='//div[@class="info"]//div'),callback='top250_parse_item'), Rule(LinkExtractor(restrict_xpaths='//span[@class="next"]//a[contains(.,"后页>")]')),
)
(7) 解析豆瓣电影top250页面
(1) 定义Item,部分代码:
class Doubantop250Item(scrapy.Item):
# 电影序号(排名)
number = scrapy.Field()
# 电影名字
name = scrapy.Field()
# 电影又名
name_two = scrapy.Field()
# 电影封面(链接)
image_urls = scrapy.Field()
说明:
Doubantop250Item继承scrapy的item类,
scrapy.Field()是scrapy内置字典类,用来指明每个字段的元数据。
(2) 运用Item,Item可以理解为一个字典,在声明的时候需要实例化,然后依次将解析结果赋值给Item的每一个字段,最后将Item返回(yield),这就是实现(2)top250_parse_item(第一个Rule的回调函数)的过程。
部分代码:
def top250_parse_item(self,response):
loader=NewsLoader(item=Doubantop250Item(),response=response)
loader.add_xpath('name','.//*[@id="content"]/h1/span[@property="v:itemreviewed"]/text()',TakeFirst())#电影名字
loader.add_xpath('image_urls','.//*[@id="mainpic"]/a/img/@src',TakeFirst())#电影封面(链接)
loader.add_xpath('number','.//*[@id="content"]/div[1]/span[@class="top250-no"]/text()')#电影排名
loader.add_xpath('score','.//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')#电影评分
yield loader.load_item()
说明:add_xpath()方法是用来填充item。yiel是将Item返回。
(3)需要说明的是在该top250_parse_item方法中使用了Item Loader来提取Item,因为Item Loader对Item的提取方法做规则定义,提取方法更完整,这里定义了一个ItemLoader的子类,名为NewsLoader,实现将提取出来的消息,去除换行符,从列表形式变成字符床形式,代码:
from scrapy.loader import ItemLoader
from scrapy.loader.processors import Join, Compose
class NewsLoader(ItemLoader):
default_output_processor = Compose(Join(','), lambda s: s.strip(' \n'))
说明:default_output_processor是输入处理器,
Compose方法处理列表内每个元素。
(4)不过由于当Item Loader提取到空值时会报错,例如当提取到电影《沉默的羔羊》时会因为没有电影又名(要爬取的信息)而报错,所以需要重写add_xpath方法,重写方法后代码:
def add_xpath(self, field_name, xpath, *processors, **kw):
values = self._get_xpathvalues(xpath, **kw)
if values:
self.add_value(field_name, values, *processors, **kw)
else:
self.add_value(field_name, "Null", *processors, **kw)
说明;当values为空时,写入“Null”。
(8)保存文件
经过上面一系列操作后,我们可以获取到要爬取的数据,可以用Item Pipeline来保存数据。
部分代码实现:
def process_item(self, item, spider):
#'下面这段是写入txt。
move_name = item['name']
if len(move_name.split(' ')) > 1:
move_name = move_name.split(' ')[0]
with open(r'DouBanTop250/Result/' +move_name+'/'+move_name + '.txt', 'a', encoding='utf-8') as f:
r_list = ['电影排名', '电影名字']
s_list = ['number', 'name']
for i in range(len(r_list)):
f.write(r_list[i] + ':' + str(item[s_list[i]]) + '\n')
f.write('\n')
text = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.ranking.write(text.encode('utf-8'))
return item
说明: json.dumps()方法是对json数据的操作
思路:创建一个json文件,把所有数据保存到里面,然后把各个电影的数据保存为txt文件分别放在Result文件夹下的文件夹(电影名字)下。
由于要爬取的还有图片所以我们还得再定义一个ImagePipeline(专门处理下载图片的Pipeline)。部分代码:
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['image_urls'], meta={'item': item})
def file_path(self, request, response=None, info=None):
'''图片保存的路径'''
item = request.meta['item']
img_name = item["name"]
if len(img_name.split(' ')) > 1:
img_name =img_name.split(' ')[0]
path = '/' + img_name + '/' + img_name + '.jpg'
return path
'''图片下载后返回下结果,观察是否成功。'''
def item_completed(self, results, item, info):
return item
说明:get_media_requests()方法,对每个图片的路径进行请求并下载。
file_path()方法,下载路径的方法。
item_completed()方法,下载后使用的方法。
思路:重写get_media_requests()方法,实现了ImagePipeline对爬取的image_urls图片链接进行下载,通过用file_path改变路径的同时用电影名字来命名图片并保存,还实现了item_completed()方法,当下载一张图片完成时返回结果。
(9) settings配置
定义完Item Pipeline后还得到settings上启动Item Pipeline,设置ImagePipeline图片下载路径、变量,并且由于豆瓣网有反爬虫机制,还得设置请求头(模拟浏览器),关闭遵守robotstxt协议文件。部分代码:
#关闭遵守协议
ROBOTSTXT_OBEY = False
#增加并发线程,提高效率
CONCURRENT_REQUESTS = 300
#降低日志级别,减少CPU的使用率
LOG_LEVEL ='INFO'
#禁止重试,提高爬取速度
RETRY_ENABLED = False
#增加下载延迟,为了防止被封IP
DOWNLOAD_DELAY = 1.5
#并发请求,提高效率
CONCURRENT_REQUESTS_PER_IP = 500
#请求头
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
#随机请求头中间器启动
DOWNLOADER_MIDDLEWARES = {
'DouBanTop250.middlewares.RandomUserAgentMiddleware': 543,
}
#管道启动
ITEM_PIPELINES = {
'DouBanTop250.pipelines.Doubantop250Pipeline': 400,
'DouBanTop250.pipelines.ImagePipeline':300
}
#图片下载路径
IMAGES_STORE ='./DouBanTop250/Result'
#图片变量(item对应变量)
IMAGES_URLS_FIELD='image_urls'
思路:这里把ImagePipeline设置比Doubantop250Pipeline快执行,是因为Doubantop250Pipeline里面保存文本文件时没有创建文件,直接使用ImagePipeline下载图片创建的文件夹。这里还启动了Middleware是因为爬取数据量大,同一个请求头容易被封IP,设置随机请求头,并且在settings里设置延迟下载,限制速度,可以防止被封ip。
随机请求头方法部分代码:
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agents = ["Mozilla/5.0,"Mozilla/4.0,]
def process_request(self, request, spider):
item_ug = random.choice(self.user_agents)
try:
request.headers['User-Agent']=item_ug
except Exception as e:
print(e)
pass
说明:request.headers请求头属性,直接对其赋值即可实现随机请求头。如果有异常,则输出错误异常。
(10) 运行蜘蛛
Spider的运行可以用在命令行输入:scrapy crawl xxx ,xxx是Spider的名字。
但这样子的话每次运行一个蜘蛛就要在命令行输入一次显得很麻烦,自定义一个top250_run类来运行top250这个spider。代码实现:
from scrapy import cmdline
import os
import shutil
if __name__ == '__main__':
''' 判断是否有这个文件。'''
if os.path.exists('DouBanTop250/top250.json'):
os.remove('DouBanTop250/top250.json')
'''判断是否有这个文件。 '''
if os.path.exists('DouBanTop250/Result'):
shutil.rmtree('DouBanTop250/Result')
cmdline.execute("scrapy crawl top250".split())
说明:os.path.exists()方法,判断有无这个文件
os.remove()方法,删除这个文件
shutil.rmtree()方法,删除这个文件夹包括子目录文件。
cmdline.execute()方法,相当于在cmd下运行这个命令,(参数为列表)
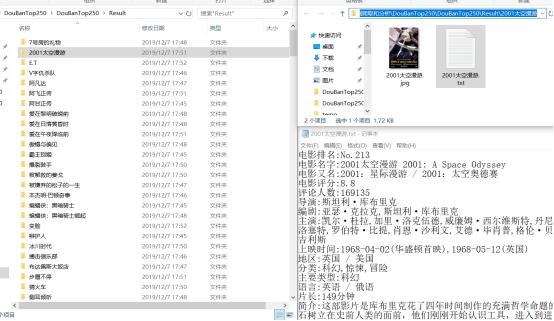
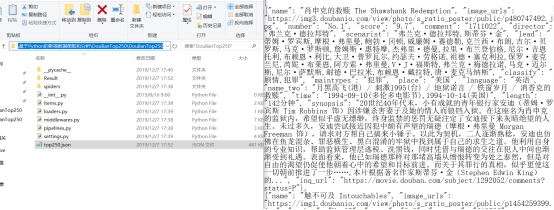
这里对top250.json和Result进行判断,如果存在就删除这两个文件,为了避免重复下载和排行榜数据更新的情况发生。运行top250_run,结果如图4.8
项目文件下,创建了Result和top250.json,进入Result可以看到数据都爬取下来写进去了,如图所示,top250.json文件里也储存了数据。
四、 防范对策
1.动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
2.禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
3.可以通过COOKIES_ENABLED 控制 CookiesMiddleware 开启或关闭设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
4.Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
5.使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的。
6.使用 Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
五、 个人建议
该毕设使用Scrapy框架对一个网站进行系统化地爬取数据,相比较于使用requests来爬取网站,爬取效率直线提升,项目构建所需要的时间也大幅减少。有些问题待改进,如模拟登录后一个ip爬取一定数据后被封号的问题,由于校园网使用代理被封,无法使用代理ip来解决问题。
六、 附件(单独的代码文件相关的资料 )可选








