|
一、选题依据:(简述研究现状,说明该毕业设计的设计目的及意义)
研究现状
Python是一门很全面的语言,又随着大数据和人工智能的兴起,广受爬虫设计者们的青眯。设计者们运用Python语言的框架-Scrapy开发分布式爬虫,对网络或者特定网站的数据进行挖掘。
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,其架构清晰、模块之间耦合程度低,可拓展性极强,可以灵活完成各种需求。使用Scrapy我们可以轻松实现一个爬虫,对豆瓣网进行采集数据,然后可以用Pandas对数据进行分析,为了更好地了解影片口碑,还可以用Matplotlib将影片评分数据做成柱形图等,也可以用wordcloud将影评词云化展示。
Scrapy用途广泛,可以用于数据挖掘、检测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。其最初是为了页面抓取(更确切来说,网络抓取)所设计的,也可以应用在获取API所返回的数据(例如Amazon Associates Web Services)或者通用的网络爬虫。
设计的目的:
随着经济社会的快速发展,电影作为精神文化产品,得到越来越多人的青睐,人们对电影的评价页也参差不齐,在海量的资源中如何尽快找到符合个人品味的电影,成为观众新的问题。基于Python的数据爬虫技术是目前使用最广泛的方法之一,它能够以最快捷的方式展示用户体验数据,帮助观众进行影片选择。豆瓣电影是著名的电影网站,通过豆瓣电影提供的开放接口大规模地获取电影相关数据。
设计的意义:
本毕业设计用Python的Scrapy框架编写爬虫程序抓取了Top250排行榜的影片榜单信息,爬取电影的短评、评分、评价数量等数据,并结合Python的多个库(Pandas、Numpy、Matplotlib),使用Numpy系统存储和处理大型数据,中文Jieba分词工具进行爬取数据的分词文本处理,wordcloud库处理数据关键词,最终通过词云图、网页动态图展示观众情感倾向和影片评分统计等信息。网络信息资源充盈的今天,网络信息的获取工作十分重要,该毕业设计的意义在于为用户观影提供决策支持。
|
|
二、设计思路(设计提纲、系统结构及主要功能模块设计、成员分工情况)
设计提纲
1.在Windows上安装Python,(配置好环境变量。)和Pycharm。
2.在Pycharm下载导入第三方库。
3.用火狐或谷歌等浏览器对豆瓣网站进行网站分析,确定要爬取的数据。
4.用Scrapy框架对豆瓣网站进行数据采集,并保存在本地。
5.对散乱的影片数据进行清洗、分析。
6.使用词云、图标等进行可视化展示,实现数据自我解释。
系统结构
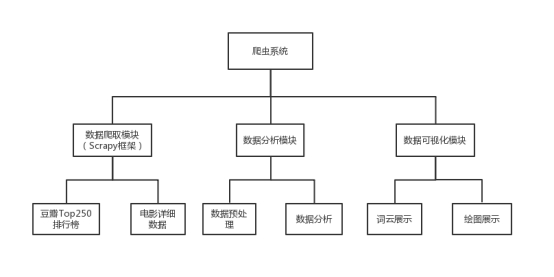
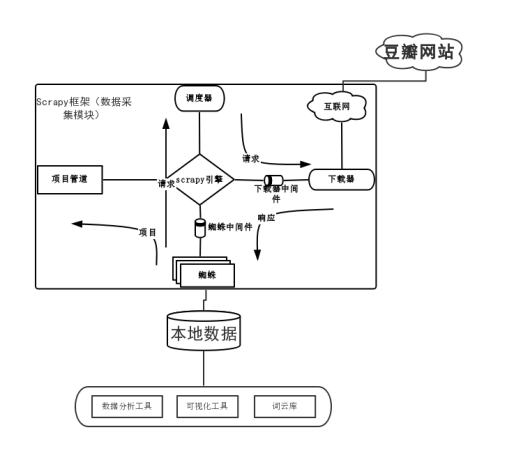
数据流程
主要功能模块设计
1. 数据爬取模块:主要是用来爬取数据,爬取豆瓣Top250排行榜上的电影名字、电影封面、电影评分、电影排名等,接下来对排行榜上每部电影的数据进行爬取。
Scrapy主要包含以下组件:
|
组件
|
描述
|
类型
|
|
Scrapy引擎
|
用来处理整个系统的数据流处理,触发事务(框架核心)。
|
内部组件
|
|
调度器
|
对蜘蛛提交的下载请求进行调度
|
内部组件
|
|
下载器
|
负责下载页面
|
内部组件
|
|
蜘蛛
|
提取数据,也可以让Scrapy继续抓取下一个页面。
|
用户实现
|
|
中间件
|
对请求和响应进行处理
|
可选组件
|
|
项目管道
|
对爬取到的数据进行封装处理
|
可选组件
|
2. 数据分析模块:主要是对爬取下来的数据进行分析处理,例如对爬取下来的电影评论进行筛选,去除重复臃肿的评论,留下‘神评论’,或是按类型、评分、时间选出最佳影片。该模块会运用到以下库:
① Pandas是Python强大、灵活的数据分析和探索工具,包含Series、DataFrame等高级数据结构和工具,可使Python中处理数据非常快速和简单。
② Numpy用于数值分析的标准python库。
3.数据可视化模块:对处理好的数据进行可视化处理,例如对影评进行结巴中文分词,然后用词云展示库,用电影封面为背景展示词云,或对爬取的数据进行各种绘图。该模块会运用以下库:
① Matplotlib是Python的一个可视化模块,他能方便的只做线条图、饼图、柱状图以及其他专业图形。
② wordcloud库,可以说是python非常优秀的词云展示第三方库。词云以词语为基本单位更加直观和艺术的展示文本。
|
|
五、参考文献
[1]安子建. 基于Scrapy框架的网络爬虫实现与数据抓取分析[D].吉林大学,2017.
[2]赵绿草,饶佳冬.基于python的二手房数据爬取及分析[J].电脑知识与技术,2019,15(19):1-3.
[3]孙瑜. 基于Scrapy框架的网络爬虫系统的设计与实现[D].北京交通大学,2019.
[4]丁忠祥,杨彦红,杜彦明.基于Scrapy框架影视信息爬取的设计与实现[J].北京印刷学院学报,2018,26(09):92-97.
[5]韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019,29(02):139-142.
[6]李刚.疯狂Python讲义[M].电子工业出版社,2018,12(01).
|
