音乐个性化推荐系统综述
摘要
最近几年来,脚本语言在所有计算机科学领域都越来越受欢迎。 在探索性数据分析的背景下,它通过将现有组件粘合在一起或使其适应新任务,提供交互性和快速原型设计等优势。 Python是一种脚本语言,语法简洁明了,也使其在教学工作中很受欢迎。 通过使用在低级语
关键词:文献分析;推荐;本体论;语境意识。
1.绪论
随着移动网络和数字多媒体技术的飞速发展,数字音乐已经成为许多年轻人追求的主流消费内容。个性化音乐推荐也成为推荐领域的热门话题。然而,它产生的海量异构音乐数据无疑超出了受众的基本需求和承受能力,进而导致信息疲劳。因此,如何利用音乐个性化推荐,帮助用户快速准确地获取感兴趣的音乐曲目,在庞大的音乐库中显得越来越重要。
近年来,音乐推荐技术引起了国内外学者的密切关注,产生了大量的研究成果。也有很多知名的个性化音乐电台,如Pandora和Last.fm、国外知名网站、国内歌曲品味和豆瓣电台等,推荐结果的准确性和覆盖率低,缺乏个性化往往不能真正满足用户的需求。与电影、读物、书籍等其他类型的推荐内容相比,音乐推荐具有独特的特点。如果推荐的曲目可以无限循环,则只能用作背景音乐;播放歌曲的类型与用户的心情密切相关。这就要求音乐个性化推荐系统能够有效地反映和反映受众的个人喜好和情况。调整以实现针对不同受众需求的个性化推荐。因此,音乐个性化推荐系统是一个比一般推荐系统更复杂的系统。它需要综合考虑用户的需求,结合多媒体领域的音频特征识别和语音处理技术,完成音乐特征的提取。以音乐推荐为研究对象是个性化推荐系统中的一个特殊领域,具有很大的研究价值和现实意义。
2. 音乐个性化推荐系统
音乐个性化推荐系统通常由三部分组成:用户偏好模型、音乐资源描述和推荐算法[1]。其中,音乐资源的描述主要包括音乐资源(歌曲、歌手、专辑等)的组织和管理。通过定义不同层次的复杂度和抽象度,构建音乐特征数据库,为音乐推荐模型提供有效的输入数据。因此,音乐资源是形成音乐推荐的基础和关键。Pachet[2]将音乐资源分为三类:声学元数据、编辑元数据和文化元数据。
目前,在音乐个性化推荐系统的相关研究中,介绍主要集中在推荐策略或算法的改进上,忽略了推荐对象对推荐系统的重要影响。音乐推荐的独特性和复杂性主要体现在音乐资源描述模块中,涉及到音频文件的标注、终端用户的语义理解、分段音频的声学描述符的使用等。这种音乐信息处理的特殊性对推荐系统提出了新的要求。
基于声学元数据:声学元数据是指通过音频信号分析提取的歌曲的一些底层声学特性。提取这些基本特征需要对音频进行一系列预处理,例如量化、抗混叠滤波、预加重、加窗、傅里叶变换等。常用的音乐特征参数有:频率中心、短时平均能量、过零率、MFCC、带宽等。由于音乐特征提取能力有限,且其特征维数大,算法时间复杂度高,难以保证实时在线处理。这些因素都导致了基于声学元数据的音乐推荐不能得到充分的应用和发展。
基于编辑元数据:编辑元数据是由一些领域专家对音乐的主客观描述或采用协作模式,由组用户给出的定性描述数据。它主要包括歌曲制作信息(如词曲作者、歌手、年龄、语言、包括专辑)、歌手背景、音乐类型、专家注释或评论。其核心是在音乐作品及其相关属性之间建立适当的联系,将基本的组织原则应用于音乐资源。目前,利用编辑元数据建立的音乐数据库包括AMG(All music Guide)、CDDB(CD Database)、Musicbrainz等,但缺乏个性化,劳动成本高,可扩展性差,与用户真实的音乐感知还有一定的差距。三。基于文化元数据:Whitman等人。
提出了一种在音乐推荐引擎中显式处理歌手自由文本元信息的方法,使用歌曲标题、评论、艺人姓名等关键字过滤网页数据,比较5个推荐歌手和5个随机选择。歌手的平均相似度,并假设当五个推荐歌手的平均值较高时,系统能够更好地实现歌手的推荐。音乐文化元数据是基于标签的基于音乐的个性化推荐系统的数据基础。他的总体思路是利用用户提供的社交标签来综合评价歌手或歌曲的相关性。标签不仅反映了音乐本身的类别和内容特点,而且反映了用户对音乐的偏好,具有很强的灵活性和开放性。它也有一些问题。一方面,文化元数据的获取需要大量高黏性用户的存在;另一方面,它容易产生偏见,音乐长尾上的歌曲被观众忽视。
音乐个性化推荐的研究热点
在移动环境下,本文从群体音乐推荐、本体建模、上下文感知音乐推荐等方面进行了深入的研究和探讨。
群体音乐推荐系统:虽然近年来音乐个性化推荐系统发展迅速,但目前大多数系统只针对单个用户进行推荐,而音乐作为情感表达和情感交流的重要方式具有显著的社会公共性。因此,考虑建立一个适合公众环境的音乐推荐体系。实现群组用户的实时推荐服务,将为音乐推荐提供新的研究思路。Popescu等人。[4] 构建了一个群组音乐推荐系统GroupFun,该系统使用投票机制来表达智能系统研究的真实进展,卷147853群组用户的音乐偏好,并使用概率加权和方法来评估群组用户对推荐歌曲的最终满意度。
本体建模:本体具有语义多样性和良好的推理能力,在许多上下文智能系统中得到了广泛的应用。国外学者试图用本体论对音乐进行建模,以解决低级音频特征与用户对音乐理解加深之间的语义鸿沟。针对音乐推荐服务[5]专门开发了音乐本体,并在此基础上进行了定义。与音乐相关的本体论。由于不同的文化背景和不同的思维方式,西方音乐和听众的音乐本体论并不适用于中国歌曲和中国音乐。因此,基于中文音乐本体或应用本体技术构建用户模型将成为一个重要的研究热点。
评价指标:目前,大多数音乐个性化推荐系统使用RMSE、MAE或TopN推荐列表,通过精确性和召回率来衡量推荐结果。然而,无论使用上述哪种度量方法,其本质都是将预测精度作为评价音乐个性化推荐系统的指标。因此,如何解决目前系统普遍存在的评价指标单一的问题成为一个重要的研究热点。为了解决这个问题,可以考虑添加一些新的度量指标。Celma[6]建议使用推荐结果的平均受欢迎程度进行评估。最基本的想法是,在流行结束时的音乐更容易让用户感到新鲜。假设S代表一组用户,那么用户u的推荐列表的新颖性定义如下[7]:
Novelty= 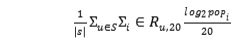 (1)
(1)
其中,R是Top-N函数,R u,20表示向用户u推荐推荐列表中的前20项,popi表示对该项的偏好估计。音乐推荐的惊喜程度是指一首与用户喜爱的歌曲不相似,但用户感到满意的歌曲。例如,向披头士乐队推荐约翰・列侬歌曲的歌迷可能是准确而新颖的推荐,但他的推荐并不能让用户感到惊讶。因此,如果推荐结果与用户过去的兴趣不相似,但对用户满意,则可以说该推荐结果具有高度的惊喜性。惊讶的程度是用不友善来衡量的。公式如下:
Unserendipity=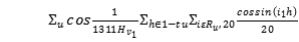 (2)
(2)
其中CosSim(i,h)功能是比较用户历史兴趣Hu与新推荐结果的平均相似度。该值越小,推荐结果与用户历史兴趣的偏离越大,推荐结果的出其不意程度也越大。它越高。
移动环境下基于上下文感知的个性化推荐系统:近年来随着智能移动终端和位置服务的普及,用户通过移动终端请求音乐推荐服务成为一种新趋势,而基于智能移动终端设备的音乐应用也越来越受到关注。目前的音乐推荐系统主要依靠静态用户档案进行音乐推荐,这往往导致不同用户的推荐结果趋同,缺乏个性化。究其原因,主要是目前的音乐个性化推荐系统。所有这些都忽略了在用户音乐选择中起关键作用的影响因素,即用户的上下文[9],其中主要包括用户进入推荐系统的时间、地点、心情、天气、当前活动等。当一个人快乐而筋疲力尽时,他喜欢的音乐类型肯定是不同的。当他身处一个安静的乡村和一个熙熙攘攘的城市时,同一首歌的感觉一定不同。因此,考虑移动环境下用户的语境因素,并基于这些特定的语境因素进行音乐推荐,必将成为音乐推荐领域的热门话题。与传统的音乐推荐服务不同,移动环境下基于上下文推荐的音乐推荐服务是在移动终端上完成的。目前的移动设备智能化程度高,用户依赖性强,因此移动智能终端可以作为传感器实时捕捉用户。听音乐的上下文信息,得到大量的实时现场数据集,为音乐推荐打下良好的数据基础。然而,移动终端在智能系统研究方面也有一些进展,147854卷固有的缺陷,如显示尺寸和处理能力有限。此外,应将移动设备用作与音乐推荐系统的交互媒体,在确保信息合理的同时,应注意保护用户隐私。
3.结论
本文从音乐资源描述的角度回顾了当前的音乐推荐研究成果。指出目前的研究缺乏对用户行为和需求的系统研究,特征提取水平较低,评价指标单一。同时,对群体音乐推荐、本体建模、基于移动环境的上下文感知音乐推荐等方面进行了进一步的研究和探讨。其中,这种情况被认为是音乐个性化推荐系统中的一个重要因素。然而,在目前的音乐个性化推荐系统中,所有上下文因素的权重是相同的。显然,这种权重划分不合理,大大降低了推荐结果的准确性。因此,下一步的思路是利用粗糙集理论对情境属性进行约简,计算出不同情境属性对音乐推荐的权重,提取出对音乐推荐有较大影响的属性(如情绪、当前活动、天气等),然后将其融入到协同过滤推荐算法中。通过重要的情境相似度计算和歌曲相似度计算,生成特定情境下用户的音乐推荐列表,实现了上下文感知的音乐推荐。
附录B 参考文献的题录及摘要
【1】【作者】Yuan Xie,Lei Ding
【篇名】A Survey of Music Personalized Recommendation Syste
【机构】School of Computer,Guangdong University of Technology
【关键词】literature analysis;recommendation;ontology;contextual awareness;
【摘要】The study of music recommendation research was conducted and the corresponding research hotspots were proposed. The literature analysis method was used to briefly introduce the recommendation strategy from the perspective of the recommendation algorithm. It further proposes a method of using rough set theory to extract important context information and combines this user preference in context with collaborative filtering recommendation technology to implement a new idea of context recommendation-based music recommendation. The existing studies have a lack of systematic research on user behaviors and needs, low levels of feature extraction, and single problems in evaluation indicators. In the future, more in-depth discussions can be conducted in terms of group music recommendation, ontology modeling, and contextual awareness-based music recommendation in a mobile environment.
【2】【作者】艾笔
【篇名】个性化音乐推荐系统的设计与实现
【机构】成都电子科技大学
【关键词】餐饮消费行为;网络团购;消费者网络;多视图多粒度;可视分析;
【摘要】音乐之于人类而言,已经成为生活的重要部分。随着互联网服务的发展,人对音乐的消费模式也发生了巨变,以用户为中心的相关技术已成为目前音乐服务的主流技术。社会化标签既反映了资源的特征属性,也体现了用户的兴趣所在。同时,用户在不同时间对标签的感兴趣程度是在不断变化的。本文将结合这两个特性,提出一种基于标签和时间加权的推荐算法模型。利用用户行为日志,建立时间迁移下的用户兴趣模型,并通过社会化标签标识歌曲内容,然后依据用户兴趣模型与备选歌曲的标签特征的匹配程度来生成推荐列表。同时标签可以很好地解释推荐该项目的原因,提高用户的接受度。为了解决数据稀疏性的问题,本文还加强了对隐式数据的利用。
【3】【作者】邓腾飞
【篇名】个性化音乐推荐系统的研究
【机构】华南理工大学
【关键词】个性化音乐推荐系统; 偏好评分; 歌曲相似度; 深度神经网络; 切歌率预测;
【摘要】个性化音乐推荐系统能在用户只有模糊的听歌需求的情况下,根据用户的信息从上千万的海量歌曲库中精准的找到用户可能感兴趣的歌曲并加以推送。音乐推荐相关算法包含三类:基于内容的推荐算法、协同过滤推荐算法、混合推荐算法。单一的推荐算法无法充分利用系统中海量的用户信息和物品信息,不同算法或规则的混合能提升推荐的准确度。由于音乐推荐系统的用户数量远远大于歌曲数量,在计算歌曲相似度时采用基于物品的协同过滤可以明显减少计算量。本文在基于物品协同过滤的基础上进行了如下的研究工作:1、基于物品协同过滤计算物品间相似度需要充分利用用户所偏好的物品进行计算,由于音乐推荐中反映用户对歌曲偏好的行为众多,本文设计了偏好评分并据此计算出更加精准的歌曲相似度。2、由于协同过滤只利用了用户行为数据,并没有考虑歌曲间内容的相关性,故本文融入了兴趣标签进行了算法的混合,通过实验证明了混合推荐算法可以取得更高的推荐精度。3、深度神经网络可以充分学习用户特征、歌曲特征、用户对歌曲的行为特征进而准确地预测用户对歌曲的切歌率,本文引入深度神经网络来预测歌曲的切歌率并利用海量用户听歌数据训练了一个切歌率预测模型,通过对混合算法推荐的歌曲进行切歌率预测并过滤后再进行推荐可以使推荐更加精准。
【4】【作者】谢宛辰
【篇名】基于领域本体的个性化音乐推荐系统的设计与实现
【机构】浙江大学
【关键词】音乐推荐; 本体构建; 标签抽取; 音乐检索; 可视化;
【摘要】随着数字音乐的飞速发展,越来越多的用户选择数字音乐作为消费对象,然而面临网络上过载的音乐信息,用户常常陷入音乐选择困难的问题,所以如何从海量的音乐数据中快速、准确的找到用户感兴趣的音乐是目前音乐领域的一个值得深入探讨的问题。针对此问题,目前已经有许多音乐服务网站提出了不同的解决方案,这些音乐推荐系统包括基于音乐内容的、基于用户对音乐评价的、基于用户与用户之间相似度的推荐系统等等,虽然它在某种程度上解决了用户的上述需求,但是其中的推荐算法都存在不足之处。基于以上背景,本文对音乐领域进行了调研,发现不同的音乐网站具有不同的音乐分类标准,这就使得整个音乐体系变得非常庞大和复杂,站在用户的角度,希望得到一个统一的音乐分类体系,所以本文对音乐领域进行了本体构建,形成了一个音乐知识系统。在音乐领域本体构建的基础上,本文提出了两种混合推荐算法,一种是充分考虑用户的信息和用户的行为,融合基于内容和基于协同过滤的推荐算法形成的,一种是充分考虑用户的需求和用户的偏好,融合基于内容和基于规则的推荐算法形成的。本文最终设计并实现了一个基于领域本体的个性化音乐推荐系统,该系统能够为用户提供个性化音乐推荐、音乐检索、音乐数据可视化等功能。本文对系统的整体架构和各模块的设计与实现进行了详细的说明,并完成了系统测试。
【5】【作者】谭学清,何珊
【篇名】音乐个性化推荐系统研究综述
【机构】武汉商学院烹饪与食品工程学院
【关键词】推荐系统; 音乐推荐; 元数据; 粗糙集; 情境感知;
【摘要】对音乐推荐的研究概况进行调研和总结,探讨其存在的问题,提出相应的研究热点。采用文献分析法,从推荐算法的角度简要介绍各个推荐策略,着重根据音乐资源描述方式的不同对现有音乐推荐的相关文献进行归类总结。进一步提出运用粗糙集理论提取重要情境信息的方法,将该类情境下的用户偏好与协同过滤推荐技术相结合实现基于情境感知的音乐推荐的新思路。现有研究中存在缺乏对用户行为和需求的系统研究、特征提取低层次以及评测指标单一问题。未来可以从群体音乐推荐、本体建模、移动环境下基于情境感知的音乐推荐等方面展开更深入的探讨。
【6】【作者】张燕,唐振民,李燕萍
【篇名】面向推荐系统的音乐特征抽取
【机构】南京理工大学计算机科学与技术学院、金陵科技学院信息技术学院、南京邮电大学通信工程学院
【关键词】音乐推荐系统; 分形维; 特征抽取; 向量相似度;
【摘要】音乐推荐系统是指根据用户的历史浏览数据,从候选库中推荐给用户可能喜欢的音乐的一种新型网络服务。该系统的关键在于需要对整个数据库按照音乐风格进行分类,基于此提出一种新的音乐特征处理方法来完成音乐库分类,以有效实现音乐推荐。该方法首先为候选音乐库构建常规的音乐特征数据集,然后基于分形理论对数据集进行属性约简,获取每一首音乐的推荐特征向量,并且依据特征向量的特点,定义了一种新的距离度量方法。在包含六种风格的音乐数据库的实验中,仿真结果证明了提出的音乐推荐特征和距离度量的有效性,与现有的基于内容的音乐检索研究相比,音乐推荐特征的使用极大地降低了对数据库存储量的需求,对音乐推荐系统的网络开发具有很好的应用价值。
【7】【作者】李瑞敏,闫俊,林鸿飞
【篇名】基于音乐基因组的个性化移动音乐推荐系统
【机构】大连理工大学计算机科学与技术学院
【关键词】个性化服务; 混合推荐; 移动音乐; 推荐系统; 音乐基因;
【摘要】随着移动技术的不断发展,移动应用服务的市场前景广阔。其受限制的硬件条件,对移动应用服务的个性化提出了更高的要求。在此背景下,引入音乐基因组的概念,以用户对音乐的标注行为和社会化标签为基础,分析用户对不同音乐基因特征的偏好情况及用户兴趣,并利用不同用户之间的兴趣相似情况,构建用户之间的相邻关系,结合两方面的因素,提出了一个个性化移动音乐推荐系统。实验表明,该方法能够较好地满足移动音乐服务的个性化需求。
【8】【作者】刘珊珊
【篇名】音频特征与社会标签相结合的音乐推荐系统
【机构】上海立信会计学院
【关键词】音乐信息检索; 音乐推荐; 社会标签; 音频特征; 音乐可视化;
【摘要】音乐服务已成为互联网的主流应用之一,但是互联网中的海量音乐不仅使得用户很难找到个人感兴趣的音乐,而且大量处于长尾区的音乐极少被访问,信息利用率很低。音乐推荐能够进行信息过滤,向用户推送其可能感兴趣的音乐,是目前解决互联网音乐信息过载问题的有效技术手段。本文主要研究音频特征与社会标签相结合的音乐推荐技术,其中音乐特征结合了音乐信号的音频特征和音乐社区中用户提供的社会标签,音乐的相似性计算以降维的方式进行,音乐推荐结果以可视化的方式呈现。本文首先通过数据挖掘和数字信号处理的方式,获取歌曲的大量音频特征和社会标签,构建音乐特征数据库,然后对音乐特征进行预处理,并对这些特征矢量进行降维,最后在二维音乐空间展现歌曲之间的关联性。本文从商业音乐网站获取了大量实际用户的标签,分析了歌曲的80个音频特征,构建了音乐特征数据库,实现了简单的音乐推荐原型系统,并分析了标签筛选方法的有效性,验证了混合推荐算法的性能,结果显示社会标签是一种有效的音乐资源描述方式,而音频特征可以作为社会标签的补充,提高资源描述的全面性和准确度,所设计的可视化界面能够提供灵活的用户交互接口,极大地提高用户体验。本文的研究结果可以进一步应用于互联网音乐推荐系统,为海量音乐资源的高效利用和访问提供有效的技术手段。
【9】【作者】孔云
【篇名】基于混合模式的个性化音乐推荐系统的研究与实现
【机构】华中师范大学
【关键词】推荐系统; 协同过滤; 音乐基因; 混合模式;
【摘要】互联网的发展使信息量呈规模性增长,怎样在大量的信息中找到真正想要的内容成了目前研究的重点。传统的搜索引擎的方式要求用户能够比较准确的描述想要搜索的东西,然而有时候用户不好描述或者个人也不知道想要什么。推荐系统的出现为用户解决了这一难点,它不需要用户输入大量的搜索关键词,而是通过分析用户的历史操作记录,给用户进行个性化推荐。音乐就是一种很适合推荐的内容,每个人都有个人的音乐品味,推荐系统为每一个用户进行个性化的定制。本文介绍了比较具有代表性的音乐推荐系统与相关算法,分析了各个推荐算法的优点与缺点,然后提出了基于协同过滤与音乐基因的混合推荐模式,通过实验比较了基于协同过滤的推荐、基于音乐基因的推荐以及基于这二者的混合模式推荐,最后选取了基于混合模式的推荐作为个本文音乐推荐系统的推荐算法。在基于协同过滤的推荐模式中,首先构建用户-项目矩阵,然后进行用户相似度分析,查找最近邻居用户,得到一个推荐列表。在基于音乐基因的推荐模式中,通过分析音乐基因的结构,选取并计算了几项用户的基因偏好度,以此产生一个推荐列表。在混合推荐模式中,通过对上述两者的加权混合得到一个最终的推荐列表。基于协同过滤的推荐的应用范围相比其他推荐更为广泛,推荐结果的准确率也相对较高,但是也存在一些稀疏性、冷启动等方面的问题;基于内容的推荐无需依靠用户的评价信息,同时也没有协同过滤的稀疏性、冷启动方面的缺点,但是应用的范围相对来说更小。基于混合模式的推荐针对这两个推荐的缺点,可以在不同情况下采取不同权重的策略。当用户的评价信息比较少的时候,增加基于音乐基因推荐的权重;当用户的评价信息比较多的时候,增加基于协同过滤推荐的权重。这样就综合利用了基于协同过滤以及基于音乐基因推荐的优点。本文设计并实现了个性化音乐推荐系统,这是一个B/S架构的Web音乐网站,使用了当前比较热门的CodeIgniter与Bootstrap框架,最后对系统进行了测试。
【10】【作者】李世旭
【篇名】音乐推荐系统的设计和实现
【机构】上电子科技大学
【关键词】推荐系统; 个性化; Slope One; SVD;
【摘要】随着互联网的飞速发展,网上信息大量增加,面对海量信息,用户要从网上查找到感兴趣的内容变得越来越困难。传统搜索引擎能为人过滤一部分无关信息,但网上具有相同关键字的信息太多,从搜索结果中发现感兴趣的内容仍是一件费时费力的事情,在百度搜索“推荐系统”,找到的相关结果有1亿个。而且,传统搜索方式只会找到具有搜索关键字的内容,却不能发现与之关系紧密,又没有类似关键字的信息。音乐是人生活中不可或缺的一项娱乐内容,网络的便捷性让在线音乐快速发展,音乐推荐成了个性化推荐系统中一个重要组成部分,国内外各式各样的在线音乐服务不断涌现,国内近年来兴起的YY语音、网易云音乐、Jing.fm等都是此类代表。网络状况的改善,让用户越来越习惯于随听随播的收听方式,主动发现音乐的动力在减弱。个性化音乐推荐是现今在线音乐服务必备的内容,也是实现音乐长尾推荐的方法。用户收听音乐的行为,如反复收听、收听过程中跳过一首歌曲、收藏一个专辑等行为,都反映了用户对音乐的喜好倾向。因此,本文根据用户收听音乐产生的日志数据,统计每个用户收听了哪些歌手,分别收听的次数,把次数转换成评分,利用个性化推荐指纹给用户推荐可能感兴趣的歌手。协同过滤推荐方法是最早提出的推荐方法,能够对机器难以进行内容过滤的信息进行过滤,在推荐系统中得到了大量应用,在商业应用上取得了不错的成绩。随着研究的深入和实际应用的需要,协同过滤与其它方法相结合,衍生出许多不同的具体算法,Slope One算法和SVD算法便是近些年兴起的著名算法。本文的研究也主要基于协同过滤推荐算法进行。本文对Last.fm数据集作了一个简要分析,得出用户收听音乐的特征,为系统的设计和算法实验提供依据。探讨了隐性反馈数据转换为评分的方法,对个性化音乐推荐系统作了个设计,并实现了部分功能,在数据集上进行了推荐实验。
