目录
1 绪论 1
1.1选题背景 1
1.1.1课题的国内外的研究现状 1
1.1.2课题研究的必要性 2
1.2课题研究的内容 2
2 开发软件平台介绍 4
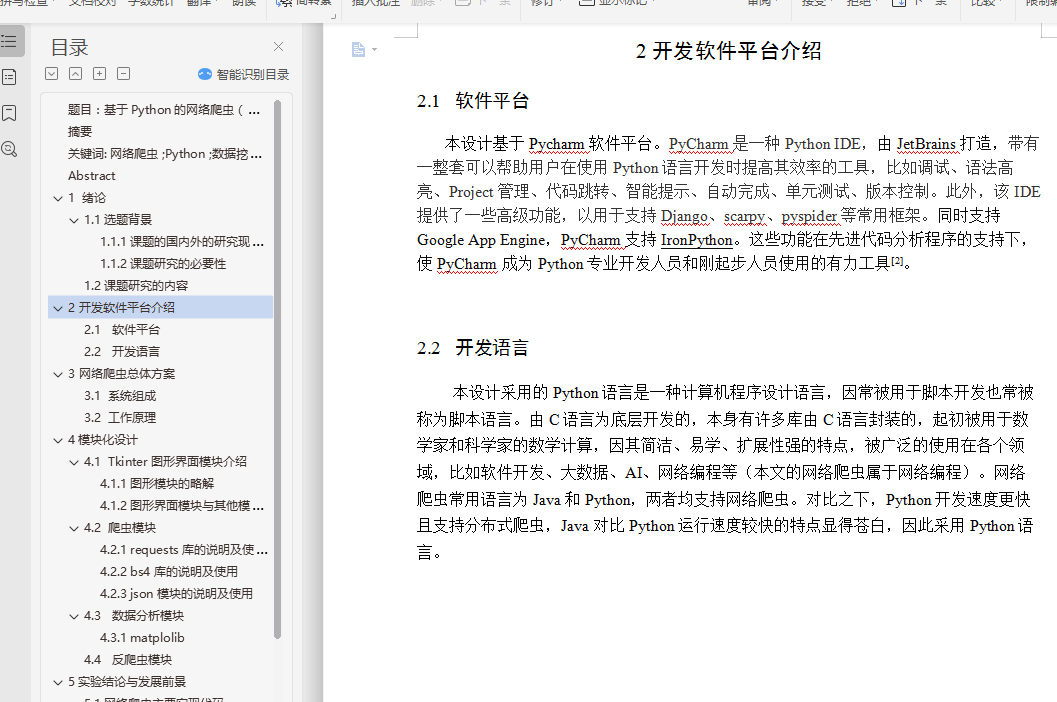
2.1 软件开发平台 4
2.2 开发语言 6
3 网络爬虫总体方案 8
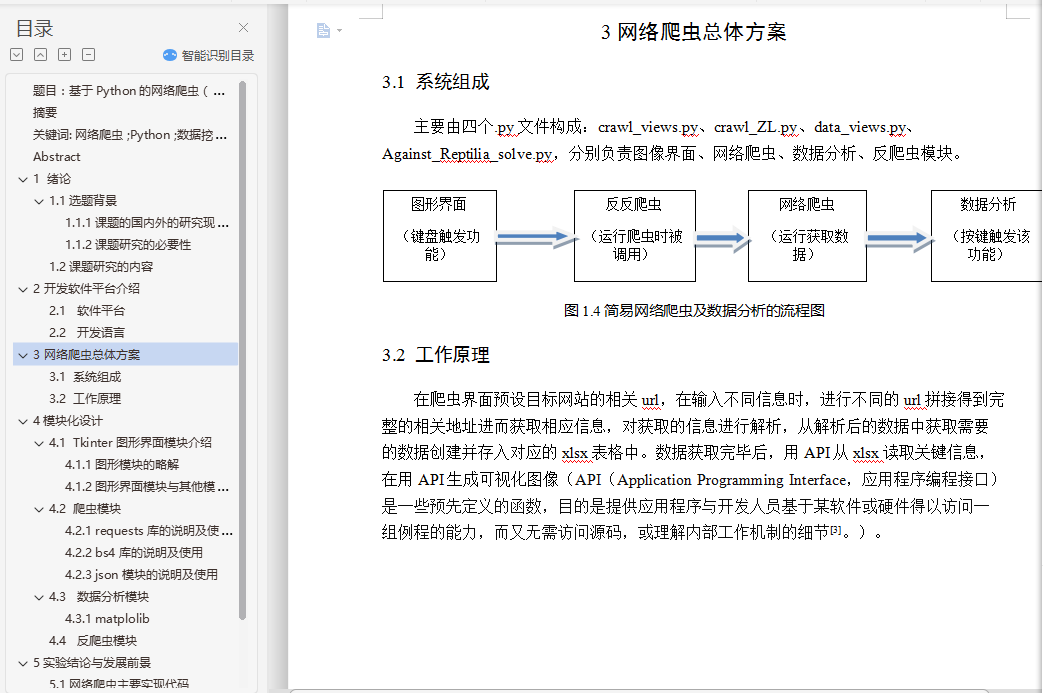
3.1 系统组成 8
3.2 工作原理 8
4模块化设计 9
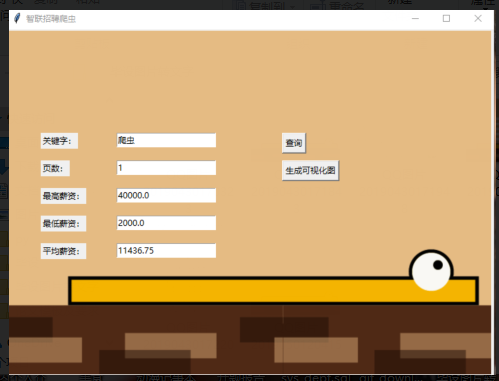
4.1 Tkinter图形界面模块 9
4.1.1图形模块的略解 9
4.1.2图形模块与其他模块的交互 9
4.2 爬虫模块 13
4.2.1 requests库的说明及选择 13
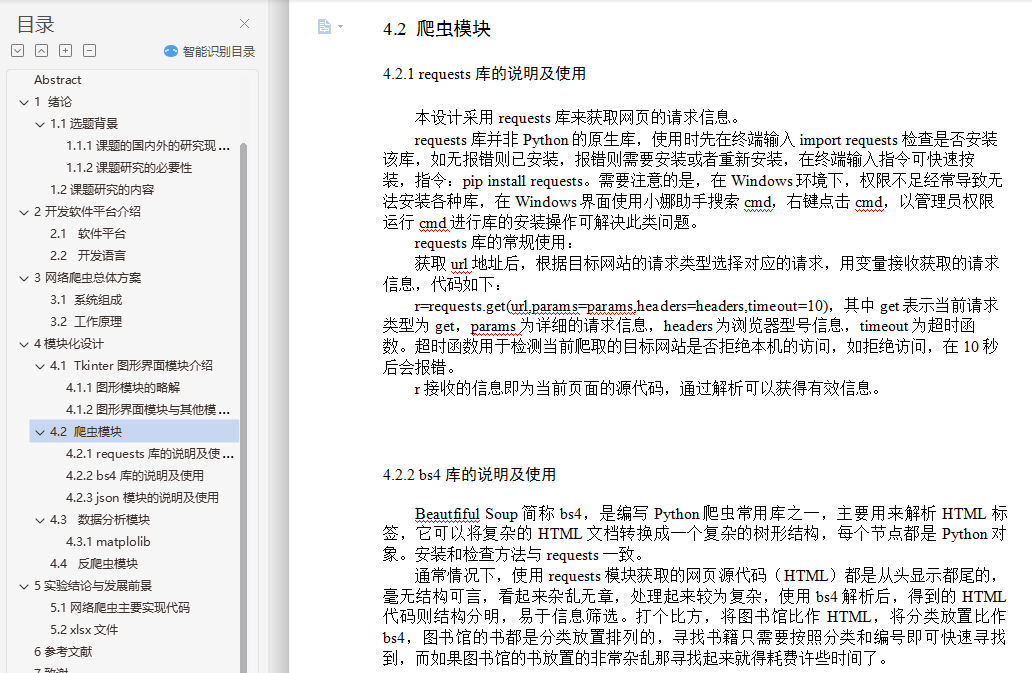
4.2.2 bs4的说明及使用 15
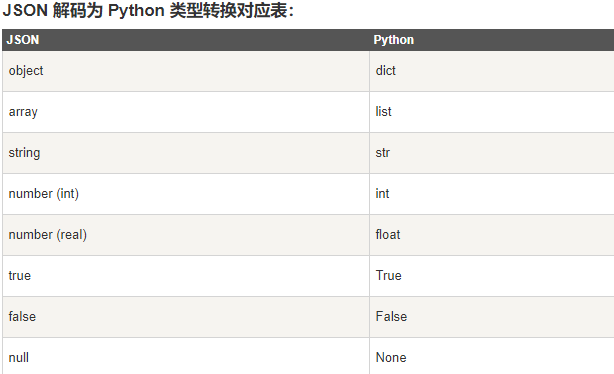
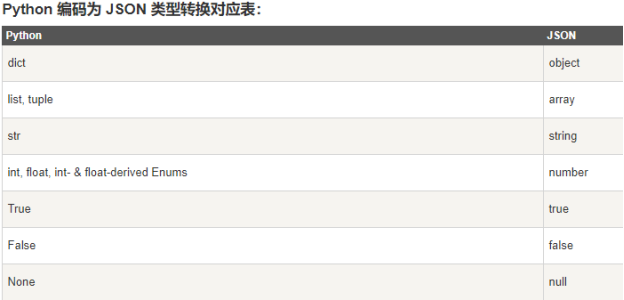
4.2.3 json的说明及使用 17
4.2.4 爬虫整体的流程解析 19
4.3 数据分析模块 21
4.4 请求头及代理池模块 24
4.4.1 24
5实验结论与发展前景 25
5.1低层实现代码 25
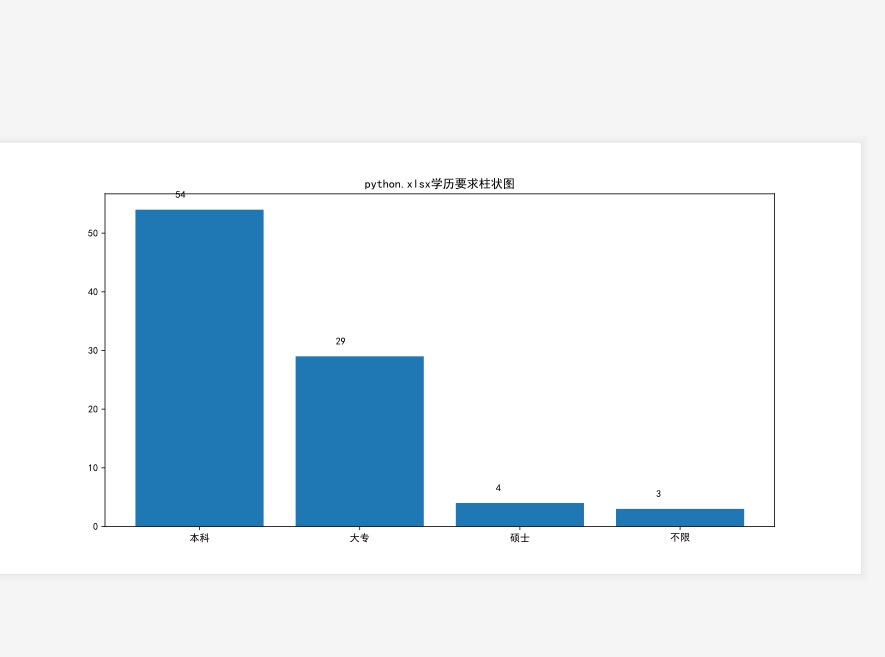
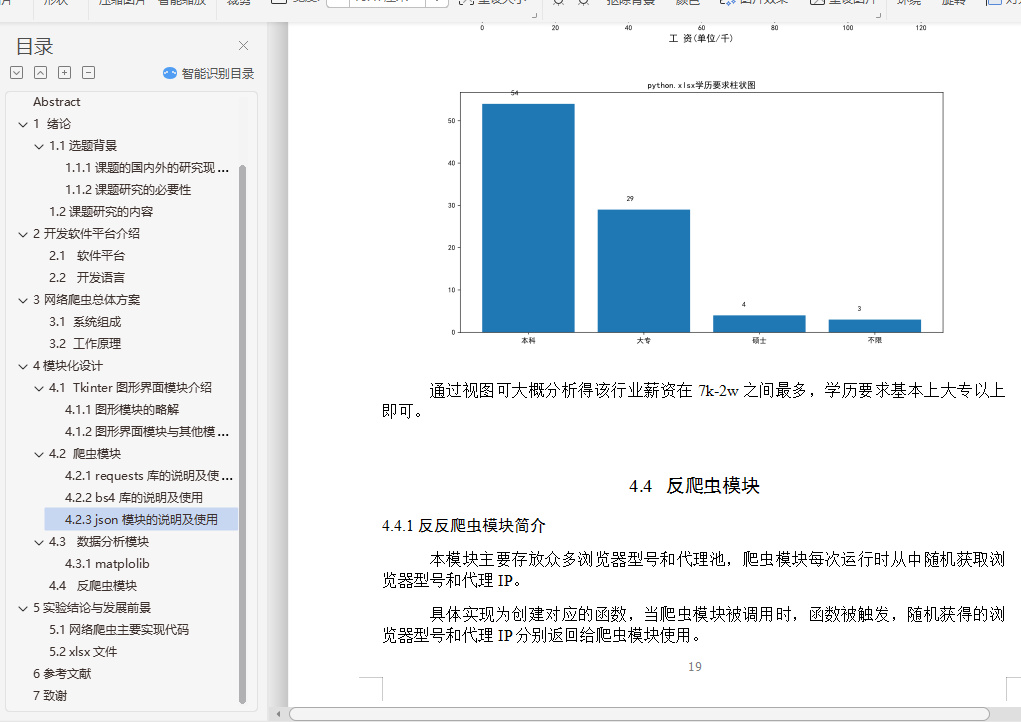
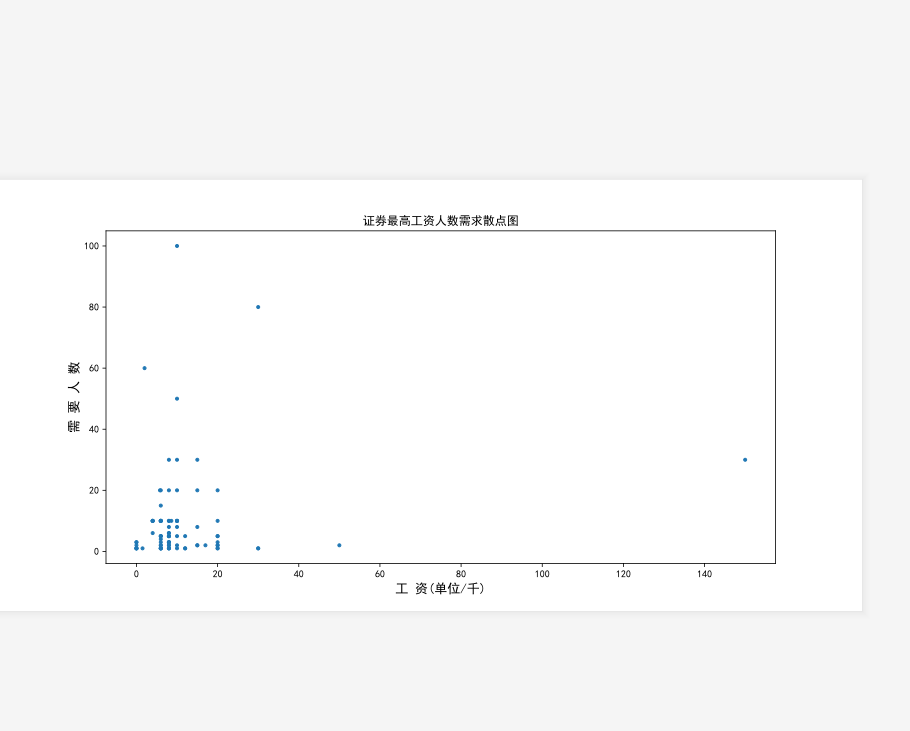
5.2 数据分析结果图 26
5.3 xlsx文件 26
6参考文献 29
7致谢 30
摘要
信息在无论何时何地都是至关重要的。随着万维网的高速发展,信息呈现指数形式的爆炸增长。传统的信息处理延申至互联网领域时,常常需要将分布在各网站的信息下载到本地在进一步处理。然而在大量数据采集时,明显传统的方法并不适用,传统方法在网络查询信息时无法避免的一个问题就是眼花缭乱的信息让人难以辨别和舍取,为了更为高效和准确的获取想要的大量时信息,网络爬虫不失为一个绝佳的手段。通过自定的规则,可以从指定的网站挖掘相关的信息,并进行筛选后获得更为精准的信息。
本为的网络爬虫程序主要采用Python脚本语言。使用Tkinter库构造图形界面便于操作,即通过点击对应按钮触发相应功能。数据存储并没有使用SQL和NoSQL,网络爬虫爬取的结果直接以xlsx文件保存,以便于数据的读取并将数据可视化。数据分析采用matplolib库,以pandas库读取xlsx文件,读取获得的数据生成散点图或柱状图以便于观察。
关键词: 网络爬虫 ;Python ;数据挖掘 ;数据分析
Abstract
Information is vital wherever and whenever it is. With the rapid development of the World Wide Web, the explosion of information in the form of an index has grown. When traditional information processing is extended to the Internet domain, it is often necessary to download information distributed on various websites to the local area for further processing. However, in the case of a large amount of data collection, the obvious traditional method is not applicable. One problem that the traditional method cannot avoid when searching for information on the network is that the dazzling information is difficult to distinguish and retract, in order to obtain the desired one more efficiently and accurately. A lot of information, web crawlers are a great way. Through custom rules, relevant information can be mined from designated websites and filtered to obtain more accurate information.
This web crawler mainly uses the Python scripting language. The graphical interface is constructed with the Tkinter module for easy operation, that is, the corresponding function is triggered by clicking the corresponding button. The data store does not use SQL and NoSQL, and the results of the web crawler crawl are saved directly in the xlsx file to facilitate data reading and visualization of the data. The data analysis uses the matplolib module to read the xlsx file with the pandas module, and the obtained data is read to generate a scatter plot or a histogram for observation.
Key words : Internet worm ;Python ;data mining ; data analysis