Ŀ ¼
1 ���ⱳ�����о����� 2
2 �����ⷢչ����ؼ������� 3
2.1 ����λ�÷����о���״ 3
2.2 ��������о���״ 3
2.1.1 ���־����㷨 3
2.1.2 ��ξ����㷨 4
2.1.3 �ܶȾ����㷨 4
2.1.3 ��������㷨 4
2.2 �Ŵ��㷨��չ��״ 5
2.3 Hadoop ƽ̨�����ⷢչ��״ 6
3 �о��������ֶ� 9
3.1 �Ŵ��㷨�Ż�DBSCAN 9
3.1.1 DBSCAN �㷨�Ļ���˼�� 9
3.1.2 �Ŵ��㷨˼�� 10
3.1.3 �Ż����� 11
3.2 �Ľ����DBSCAN �㷨 MapReduce �� 12
3.3 HDFS �ܹ� 13
3.3.1 Hadoop �� HDFS �� MapReduce �ܹ� 13
3.3.2���Ŀ�� 15
4 �����ѵ�������õĽ������ 16
4.1 �����ѵ� 16
4.2 ����õĽ������ 16
5 ʵ������ 17
6 �ƻ����Ȱ��� 17
����� 17
1 ���ⱳ�����о�����
�����Ի�����Ϊ���ĵĿƼ������ķ�չ���ռ�����Ϣ�����Ѿ�������������еĸ������档����ʹ������Ϊ�����ṩ����������Ҳ�Ӹ����Ƕȸı������ǵ��������������˼ά�����ƶ�����ʱ���IJ������뷢չ�����������ֻ������ڵ��ƶ��ն��豸��������Ѿ�����Ҫ�����ƣ���ֹ2018��6�£��ҹ������ֻ�������ģ�Ѵ�7.88�ڣ�����ͨ���ֻ����뻥�����ı����ߴ�98.3%[1]��ͬʱ���ֻ��û��ķֲ��dz��㷺������ÿ��ʱ�̵�λ����Ϣ�ܿ�ȷ����ˣ��ֻ���λ����Ϣ���źܴ�����ü�ֵ�������������ڵ���λ�õĻ�ȡ������ͨ�ż����ķ�չ���Ѿ�ʹ����λ�õ���������Ϊ����[2]���������ķ����У��û��������ع�����������ʵ���������λ�ã��Լ������λ������Ҫ��������顣
�����Щ�������ֻ���λ��Ϣ����������˹��ֶ����������������Ĵ��������������ҹ���Ч�ʵͣ���ʱЧ��Ҫ��ߵ����ݴ�����֮����Ѿ�ʧȥ���壬���ں������ݵ�������������[3]�����ñ��ļ����Ի����ٱ��߶�λ����Ϣ���з������õ���ȷ�ķ��������Ҳ���о��ȵ㡣
����λ����Ϣ�о������������¼��㣺���ڹ��������������ţ�һ���棬�����ƶ������������ȣ�������������������Ӫ�����õĹ���������������һ���棬�������Щ�ٱ���Ϣ������������Ϊ����������������Ӱ�죬����������֮����������ì�ܣ�������ά��������������ҵ��ͨ����������ٱ���λ����Ϣ���Ե�֪�Լ���ҵ���ڵ����Ļ����仯�����Լ�����ҵ��������Ų鲢Э������������ز����ƶ�Ԥ���Թ����¼����������ڹ�����ٱ�����λ�÷�������ʹ����û���������˽��Լ����ߵĻ������⣬���Լ���ע�ĵ����Ļ������⡣
������Ҫ���о������ǻ���12369�����ٱ��оٱ�������λ����Ϣͨ���ɼ���������ͨ���Դ����ݵľ�ȷ�ԺͿ����Ե��������˳�ֵ��о��������е��㷨���߷�����ȱ������˸Ľ��������� Hadoop ƽ̨����Ӧ�ó����ӳ٣���Ч��������ݴ����ٶȣ�ȡ���˴�ͳ�ľ�������������Ч�ʺ;��ȡ�
2 �����ⷢչ����ؼ�������
2.1 ����λ�÷����о���״
�����ƶ�ͨ�ż����ķ�չ���ֻ���Ϊ��������ز����ٵĹ��ߡ�λ�������ճ�������Ϊ��Ҫ����Ϣ֮һ���ֻ���λ��Ϣ�۷�ӳ���û�����ʵ��Ϊ�����λ����Ϣ��֧�ֶ���Ӧ�ó��������Ż������ķ�չ�����ڵ���λ�õ��罻���磨Location-Based Social Network��LBSN���ĸ��Ƿ�ΧԽ��Խ�㣬���Ŷ�λ�����ָ������ѷ����[4]��LBSN ������һ�ֻ����û�����λ�õ����Ͻ�����ʽ����ͨ������λ����Ϣ�������������ʵ��������������
������ѧ�߶Ե���λ�õ�����о�������ͨ����ѧģ�ͼ���û���Ϊ�켣�е���Ҫ����λ�ã��Ӷ��ܽ��û�����Ϊ���ɣ��ӵ���λ�ýǶȷ����û�֮������ƶȣ��������ε����ƶ�ģ�ͣ�ͨ������λ�����ݵķ������о��û�����Ϊ��ƫ�ã�����δ������Ϊ����Ԥ�⣻���� LBSN �����ݣ������û����ƶȼ���ģ�ͣ������û����ܵĺ��ѺͿ���ƫ�õĵ���λ�ã��Ӷ����к����Ƽ���λ���Ƽ���ʹ�� Louvain �㷨�����������֣���ߺ���Ԥ�������Ԥ���ȷ�ʣ������û�ͨ���ֻ���������ǩ�������ݣ����������ھ�ģ�ͣ���ǩ����������Ϣ���г���ھӴ�ֱ���롢ƽ�о��롢�ǶȾ���������������û��˶��켣�����ƶȡ��ڸ��������ڵ���������ݵ��Ƽ������Ľ�ϣ����������罻����ƽ̨�Ľ�ϣ��ٵ�������ϸ��ӵ��龰��Ϣ������Ϣ�Ƽ����㷺��Ӧ���ڸ��������ҽ����ӵ��龰��Ϣ�����ۺϿ����ǵ�ǰ���ȵ��δ���ķ�չ����[5]��
2.2 ��������о���״
�����㷨���ջ����Ļ��ֿɷ�Ϊ�������ࣺ���־��࣬��ξ��࣬�ܶȾ��࣬������࣬ģ�;��࣬ͼ�����[6]����ʵ�ʾ������Ӧ���У���ͬ�ij������ʵľ����㷨���������ͬ����Ҫ�������ݵ����ͼ��ṹ���������ݵ�Ŀ��Ҫ�����ѡȡ����Ӧ���㷨��
2.1.1 ���־����㷨
���ַ����ǽ���������ݶ��Ϸֳ����ɸ���������ÿ�����������Ӧ��һ�־۴ء����㻮�ַ����ľ۴ر����������ļ���������ÿ����ز���Ϊ��ֵ��Ҳ����˵����ҲҪ����һ�����ݶ�����ÿ�����ݶ��������������Ƕ�ռʽ�ģ���ֻ������һ������[7]�����ȣ���Ҫ�����ݼ�����Ϊ���ѣ�Ȼ����ѡÿ����������ĵ���Ϊ��ʼ�㣬�����������ʽ���Զ����㷨�������յ����ݵ�����������㡣ֱ���������յ��㷨��ֹ����������������ݻ��֡�˵���������㣬�����ȸ��ݳ�ʼ���ĵ�������ʼ�Ļ����࣬���ڲ�������ֹ�������������¼������ĵ�Ȼ���ظ�ǰһ�μ��㣬������ͨ�����ݼ����ھ������ƶ����յõ����ֽ��[8]�������㷨һ�㶼����һ�����������ǣ�ͬһ���۴ط�����Ǻ����Ƶ����ݼ��ĵ㣬���ϴ������Ҫ���ڲ�ͬ�ľ۴��С��жϻ��������ķ���Ҳ��һ���������������ƽ�����Լ���Ȩƽ��ƽ������͵ȡ��� K-means �㷨��K-Medoid �㷨�����ڻ��־����㷨[9]��
2.1.2 ��ξ����㷨
��ξ����㷨��Ҫһ�����͵Ľṹ���洢���ݼ��Ķ����������͵ķ�ʽ��֯���ݵ������Լ��ع������ڲ�ξ���IJ�����ƽ�����IJ��������ƣ�ƽ�����IJ�����Ҫ�Dz����ƽ���������ξ�����Ҫ���۲����������Ƶ����ݼ������۵�һ�𣬵ڶ������ǵ�����ijһ������ʱ��ͻὫ���ݾ۴��ѱ䣬�൱�����Ľڵ����[10]��Ҳ��Ҫ������ε������ս����ݼ��ֱ�ֵ�����Ҫ��Ĵ��ڡ�������̻���ִ��ֱ���������ݶ��϶���ͬһ�����������ָ����������
2.1.3 �ܶȾ����㷨
�ܶȾ����㷨����һ�����ĵ����ܶȿɴﷶΧ�ڵ����ݶ�����һ�����࣬�ܶȿɴ���һ�����ھ�����ȫ����������ڡ������ڷ�Χ�ڵ����ݵ��ܶ�ֵ���ڸ�����ֵʱ���˵�ŵ���һ���۴��У����ұ��뱣֤ÿ�����������ٺ���һ����Ŀ�����ݵ㡣���־����Ҳ���Թ��������㼰����������״�ľ۴أ���Ҳ���ܶȾ����㷨��һ����ɫ[11]�������ܶȵľ����Ǹ����������ܶȷֲ������о��ࡣͨ������£��ܶȾ���������ܶȵĽǶȳ���������������֮��Ŀ������ԣ������ڿ���������������չ����أ��Ի�����յľ����������͵��㷨���� DBSCAN �㷨�� DESCAN �㷨[12]��
2.1.3 ��������㷨
�����㷨�����ݹ�ģ�����ӵ�����´��������ܵ��˺ܴ�����ƣ����ڷֲ�ʽ�����ܵij��֣����ҲΪ�������������ݵļ�������˷dz��õĽ������������������㷨������ Map Reduce �ϵķ����о�Ҳ�����ӣ���Щ�����ڴ˻����Ͼ�����������ھ�����ʽ���ģ���ݵĴ�����������ʵ����һ���������㷨����������֪������[13]��
2.2 �Ŵ��㷨��չ��״
�Ŵ��㷨�ı���������Michigan��ѧ��Holland���ڼ���ѧ���������ܵ�����ģ�⼼����������������һ�ֻ��������Ŵ��ͽ������Ƶ��ʺ��ڸ���ϵͳ�Ż�������Ӧ�����Ż����������Ŵ��㷨[14]��1967�꣬Holland��ѧ��Bagley���䲩ʿ�������״�����ˡ��Ŵ��㷨��һ�ʣ�����չ�˸��ơ����桢���졢���ԡ���λ���Ŵ����ӣ��ڸ��������ʹ��˫����ı��뷽����20����80�����Holland����ʵ���˵�һ�������Ŵ��㷨�Ļ���ѧϰϵͳ���������Ŵ��㷨�Ļ���ѧϰ���¸���[15]��1975�꣬De Jong�����Ŵ��㷨��˼���ڼ�����Ͻ����˴����Ĵ���ֵ�����Ż�����ʵ�飬�������Ŵ��㷨�Ĺ�����ܣ��õ���һЩ��Ҫ�Ҿ���ָ������Ľ��ۡ�1989�꣬Goldberg�����ˡ�Genetic Algorithm in Search��Optimization and Machine Learning��һ�飬ϵͳ���ܽ����Ŵ��㷨����Ҫ�о��ɹ���ȫ���������������Ŵ��㷨�Ļ���ԭ������Ӧ��[16]��1991�꣬David�����ˡ�Handbook of Genetic Algorithms��һ�飬�������Ŵ��㷨�ڿ�ѧ���㡢���̼�������ᾭ���еĴ���ʵ����1992�꣬Koza���Ŵ��㷨Ӧ���ڼ����������Ż���Ƽ��Զ����ɣ�������Ŵ����(Genetic Programming�����GP)�ĸ���ڿ���ϵͳ��������Ʒ����Ŵ��㷨���ڶ��ʹ����֤������Ч�IJ��ԡ����磬Krishnakumar��Goldberg�Լ�Bramlette��Gusin��֤��ʹ���Ŵ��Ż�������̫��Ӧ���е�������Ŀ������ṹ��ʹ�ô�ͳ������LQR��Powell(������)��������������õ�ʱ��Ҫ��(��������)��Porter��Mohamedչʾ��ʹ�ñ��ʽṹ��������Ķ�������п���ϵͳ���Ŵ���Ʒ���[17]�����ͬʱ����һЩ��֤�����Ŵ��㷨����ڿ������ṹ��ѡ����ʹ�á�
���Ŵ��㷨��������չ����������20����70���������Σ�20����80����Ƿ�չ�Σ�20����90����Ǹ߳��Ρ��Ŵ��㷨��Ϊһ��ʵ�á���Ч��³����ǿ���Ż���������չ��ΪѸ�٣������������ѧ�ߵĸ߶����ӡ�
��Щ������������ܶ�ѧ�����Ŵ��㷨�ı����ʾ����Ӧ�Ⱥ������Ŵ����ӡ�����ѡ�������Է�������ƭ����Ͳ����Ŵ��㷨�������˴������о��Ľ������кܶ�ѧ�߽��Ŵ��㷨������ֻ���㷨��ϣ���һ����߾ֲ��������������Ŵ��㷨��Ӧ����Ҳ�кܶ�Ľ�[18]�������Ŵ��㷨����ȫ�ֲ�����������ͨ�á�³����ǿ���ŵ㣬ʹ���Ŵ��㷨�㷺��Ӧ���ڼ������ѧ���Զ����ơ��˹����ܡ�������ơ�����ҵ�����﹤�̺�����ѧ������[19]������Ŵ��㷨��һЩ���⣬����һЩ������Ҫ��һ����̽���������ٽ��Ŵ��㷨���ۺ�Ӧ�õķ�չ���Ŵ��㷨�ؽ������ܼ���������չ�ֳ����ӹ�����ǰ����
2.3 Hadoop ƽ̨�����ⷢչ��״
Hadoop �� Apache ������������µ�һ����Դ�ֲ�ʽ����ƽ̨���� Hadoop �ֲ�ʽ�ļ�ϵͳ(HDFS��Hadoop Distributed File system)�� Map Reduce(Google Map Reduce �Ŀ�Դʵ��)Ϊ���ĵ� Hadoop Ϊ�û��ṩ��ϵͳ�ײ�ϸ�����ķֲ�ʽ�����ܹ���HDFS �ĸ��ݴ��ԡ��������Ե��ŵ������û��� Hadoop �����ڵ�����Ӳ���ϣ��γɷֲ�ʽϵͳ��Map Reduce �ֲ�ʽ���ģ�������û��ڲ��˽�ֲ�ʽϵͳ�ײ�ϸ�ڵ�����¿�������Ӧ�ó���[20]�������û��������� Hadoop ���ɵ���֯�������Դ���Ӷ���Լ��ķֲ�ʽ����ƽ̨�����ҿ��Գ�����ü�Ⱥ�ļ���ʹ洢��������ɺ������ݵĴ�����
Google ��˾����ʱ��Ϊ�˿��ٲ������û�ʹ�����������������Ĵ�����ҳ���ݲ����м�ʱ�������Ż����������ٶȣ���Ʒ����� GFS �ļ�ϵͳ�� MapReduce ���м����ܡ���� Google ����ؼ�������Դ��Ŀ Nutch �Ĵ�ʼ�� Cutting Doug ����˻��� Java���Ե� Hadoop ƽ̨ϵͳ�ij����汾�����а�������ģ��[21]��һ���� HDFS �ֲ�ʽ�ļ�ϵͳ��ר�������洢�������ݼ�¼����һ���� MapReduce ���м����ܣ���Ҫ�����Ƕ������������������ͳ�Ƽ��㡣���������� Hadoop �汾���ϵ��Ż����������Ѿ���չ��Ϊһ���� HDFS �� Map Reduce Ϊ���ĵġ����� Zookeeper �ֲ�ʽЭ�������ܡ�Hive �ֲ�ʽ���ݲֿ⡢ HBase �ֲ�ʽ���ݿ�ȶ��������ɵĴ����ݴ�����ϵ����ͼ3-1 չʾ�� Hadoop ������̬ϵͳ��

ͼ2-1 Hadoop ������̬ϵͳ
Hadoop �м�Ⱥ��ȫ�ֲ�ʽ������α�ֲ�ʽ�͵�����ʽ���ֲ�ͬ�IJ���ʽ��������ʽ����һ̨ PC ���ϰ�װ���� Hadoop ƽ̨���� PC ���� Linux ϵͳ�� Windows ���ɣ�������ʽ�౻����Ա�������г���ı�д���ԡ�����α�ֲ�ʽ��������һ̨��װ����Linux ϵͳ�� PC ���ϣ��� PC ���� Linux ϵͳ�� Windows ���ɣ��ֱ��ɲ�ͬ�� Java ����ģ��α�ֲ����л����еĸ����ڵ�[22]����Ⱥ��ȫ�ֲ�ʽ���ڼ�Ⱥ�����°�װ����Hadoop����Ⱥ�е�ÿ���ڵ���� Linux ϵͳ�� Windows �������ʵ�ֲ�����
�ִ�������Ϣ�������ٶȼ��죬��Щ��Ϣ���ֻ����Ŵ��������ݣ����а����������ݺ�ҵ���ݡ�Ԥ�Ƶ�2020�꣬ÿ�������������Ϣ�����г��� 1/3 ������פ������ƽ̨�л������ƽ̨����[23]��ͬʱ��Ҫ����Щ���ݽ��з����ʹ������Ի�ȡ�����м�ֵ����Ϣ��Ϊ�˸�Ч�ش洢������Щ���ݣ���ʱ����ѡ�� Hadoop ϵͳ�������ݷ��������ڴ�����������ʱ�������˷ֲ�ʽ�洢��ʽ������˶�д�ٶȣ��������˴洢����������Map Reduce�����Ϸֲ�ʽ�ļ�ϵͳ�ϵ����ݣ��ɱ�֤�����ʹ������ݵĸ�Ч[24]�����ͬʱ��Hadoop �����ô洢�������ݵķ�ʽ��֤�����ݵİ�ȫ�ԡ�
Hadoop��HDFS�ĸ��ݴ����ԣ��Լ����ǻ���Java���Կ����ģ���ʹ��Hadoop���Բ����ڵ����ļ������Ⱥ�У�ͬʱ������ij������ϵͳ��Hadoop �� HDFS �����ݹ���������Map Reduce ��������ʱ�ĸ�Ч�ʣ��Լ����Ŀ�Դ���ԣ�ʹ����ͬ��ķֲ�ʽϵͳ�д����ʣ������ڶ���ҵ�Ϳ��������б��㷺����[25]��
3 �о��������ֶ�
��Щ�꣬��Ȼ�Ƽ�����ص����Ϻܶ࣬�����Ƽ����������о�Ҳ��Ϊ��������ȵ㡣���������Ӧ���ֻ���λ�ĵ�����Ϣ���з����������ֻ���λδ����ʱ��ȡ����Ϣ�����ƫ����ص��������ᶨλ���������ɽ�к���ȴ���λ�ã���ʱʹ�ô�ͳ�ľ����㷨�������ݣ�������Ӱ����������ȷ�ԡ�
��������о��ص���ǽ������DBSCAN�����㷨ͨ���Ŵ��㷨���иĽ���Ϊʵ�ֵ���λ����Ϣ�ķ��������һ���µij��Ժͷ������������Ƚ���ȡ�ĵ���λ������ͨ���Ŵ��㷨�Ľ�DBSCAN�㷨�е��������� Eps ��MinPts �����Ż�����������Ƽ���ƽ̨ Hadoop ��ܶԸĽ�����㷨 Map Reduce �������㷨�ֲ�����Ⱥ�ڵ��У�ͨ���������������ͳ�ĵ��ڵ���������ɵ������ӳ����⡣
3.1 �Ŵ��㷨�Ż�DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise) ��һ�ֽ����ݶ����ܶ���Ϊ������ָ����пռ����ķ������ֳ�Ϊ���������Ļ����ܶȵľ����[26]����Ϊһ�ֵ��͵Ŀռ��������㷨���Կռ���״�������ݺͷ���״�������Ͷ������õ�֧�֣�ͬʱ���ܹ����˹��������㡣
3.1.1 DBSCAN �㷨�Ļ���˼��
DBSCAN �㷨��һ�ּ���Ч�Ļ����ܶȵľ����㷨�����㷨���Թ����ܶȽϵ͵������㣬�����ܶȽϸ������������Կ��ٷ���������״���ࡣ����˼����:����һ�����е�ÿ����������������뾶�������а�������������������ij��������ֵ��
DBSCAN �㷨�漰��������Ҫ���
Eps ����������� p���� p Ϊ���ģ�Eps Ϊ�뾶������ p ��� Eps ����
���ĵ㣺��������㣬����õ�� Eps �����ڵĵ����������������ֵ MinPts����õ�Ϊ���ĵ㡣
�߽�㣺�ռ�������㣬�������Ǻ��ĵ㣬��������ij�����ĵ�� Eps �����ڣ��õ㱻��Ϊ�߽�㡣�߽��������ڶ�����ĵ�������ڡ�
ֱ���ܶȿɴ������������ D����������� q�� p �� Eps �����ڣ��� p Ϊ���ĵ㣬��ô������ q ��p ֱ���ܶȿɴ
�ܶȿɴ������������ D������һ��������p1��p2����pn��p = p1��q = pn����� pi �� pi - 1 ֱ���ܶȿɴ�� q �� p �ܶȿɴ�ܶȿɴ���ֱ���ܶȿɴ��һ����չ���ܶȿɴ��ǿ��Դ��ݵģ����ܶȿɴﲻ�Գơ�
�ܶ������������������� D �е�����һ�� O�������ڵ� P �� O �ܶȿɴ���ҵ� q �� O �ܶȿɴ��ô q �� p �ܶ��������ܶ�������һ���Գƹ�ϵ��
�����㣺�Ȳ��Ǻ��ĵ�Ҳ���DZ߽����κε㡣
DBSCAN ������Ĺ������£� step1��ȷ���㷨�������������������Eps �� MinPts��step2���������� D ��ѡȡ����һ�������� p���ж��� Eps �����ڵ����Ŀ������������ڻ���ڲ��� MinPts���� p Ϊ���ĵ㣻step3����� p Ϊ���ĵ㣬������ p Ϊ���ĵĴأ����ν� p �� Eps �����ڵĸ�����Ϊ�� p ��ͬ�����ʶ������������ڵĵ� q ҲΪ���ĵ㣬��ôq �� p ���ܶȿɴ�㣬���� q ���� Eps �����ڵĵ�Ҳ���Ϊ p ���� p �� E ��ʶ����� q ��Ϊ���ĵ㣬��ֱ�ӽ�����Ϊ p �����ʶ����� p Ϊ�߽�㣬��p �� Eps �����������С�ڲ��� MinPts��û�е�� p�ܶȿɴ�� p ���Ϊ�����㡣step4���������� D��ѡ����һ�������㣬�ظ����� step2��step3��ֱ�������� D ��û��δ�����ĵ㣬������̽����������ݿռ��У�����һ���߽��������ڿ��ܰ���������ĵ㣬��Щ���ĵ�������ڲ�ͬ�Ĵء�DBSCAN �㷨û�ж������ı߽�����������н�һ����𣬶���ȡ�ġ�˭���ֹ�˭���еIJ��ԡ���Ϊ����߾��ྫ�ȣ�����ʹ�û��ھ���ķ��������߽�㣬���߽�㻮��������������ĺ��ĵ��������С�
DBSCAN �㷨��˼·��ͨ���������� D ��ÿ���� Eps �������ж����Ƿ�Ϊ���ĵ㣬����������ν��д���չ�����㷨�ж�ÿ����������м��㣬����ÿ�����ʱ�临�Ӷ�Ϊ O(n)����ˣ��㷨��ʱ�临�Ӷ�Ϊ O(n2)������ n ��������������DBSCAN �㷨������ʱ��Ҳ������˶��ڴ���DBSCAN �㷨���ʺϴ��������Ļ����������ò��л�������ʽ��������㷨ִЧ�ʡ����Զ������� D����Ϊ q ��������������ÿ�� q ���ж����ֲ� DBSCAN ���࣬Ȼ��ͨ��ͨ�����ȫ�־�������
3.1.2 �Ŵ��㷨˼��
�Ŵ��㷨(Genetic Algorithm)��ģ��������������۵���Ȼѡ����Ŵ�ѧ����������������̵ļ���ģ�ͣ���һ��ͨ��ģ����Ȼ���������������Ž�ķ������Ŵ��㷨�ǴӴ����������DZ�ڵĽ⼯��һ����Ⱥ(population)��ʼ�ģ���һ����Ⱥ���ɾ�������(gene)�����һ����Ŀ�ĸ���(individual)���[27]��ÿ������ʵ������Ⱦɫ��(chromosome)����������ʵ�塣Ⱦɫ����Ϊ�Ŵ����ʵ���Ҫ���壬���������ļ��ϣ����ڲ�����(��������)��ij�ֻ�����ϣ��������˸������״���ⲿ���֣����ͷ������������Ⱦɫ���п�����һ������ij�ֻ�����Ͼ����ġ���ˣ���һ��ʼ��Ҫʵ�ִӱ����͵������͵�ӳ�伴���빤�������ڷ��ջ������Ĺ����ܸ��ӣ��������м�������Ʊ��룬������Ⱥ����֮���������������ʤ��̭��ԭ�������(generation)�ݻ�������Խ��Խ�õĽ��ƽ⣬��ÿһ���������������и������Ӧ��(fitness)��Сѡ��(selection)���壬����������Ȼ�Ŵ�ѧ���Ŵ�����(genetic operators)������Ͻ���(crossover)�ͱ���(mutation)�������������µĽ⼯����Ⱥ��������̽�������Ⱥ����Ȼ����һ���ĺ�������Ⱥ��ǰ��������Ӧ�ڻ�����ĩ����Ⱥ�е����Ÿ��徭������(decoding)��������Ϊ����������Ž⡣
�Ŵ��㷨�н�������������Ҫ�����ӣ��������Ŵ��㷨��ȫ�������ԡ����������������Ҫ�ı����Ӵ��̳и��������������Ӵ��Ŀ����ԡ����������job-shop��������Ļ����ϣ������һ�ֻ��ڹ�������POX�������������������ڹ������Ľ�����бȽϣ�֤���˸ý��淽�����job-shop�����������Ч�ԡ�ͬʱ��Ϊ�����ͳ�Ŵ��㷨�����job-shop�������������������ͬʱ�������һ�ָĽ����Ӵ�����ģʽ�Ŵ��㷨�����Լӿ����Ŵ��㷨�������ٶȣ���ԭ��ͬ����������������Ż����⡣
3.1.3 �Ż�����
���ȣ����㷨��ԭ���ݼ����в����õ����������ڴ������������ݼ�ʱ�����ݲ�����һ�ֳ����ļ��ټ������ķ�����������ʹ�õ��㷨���нϵ�ʱ�临����ʱ������Ч�����ţ����ǵķ������ڲ������������Ŵ��㷨���� DBSCAN �㷨���������� Eps ��MinPts �����Ż����Ŵ��㷨��һ����Ч�������������������������õ��˹㷺��Ӧ�á�������û���κζ���֪ʶ������½�������ά�ȷ������Ż����⡣���ǵķ����� Eps ��MinPts �����п���ֵ��Ϊ�Ŵ��㷨�Ľ�ռ䣬�� DBSCAN �㷨���������ɿƷ�˹��������Ϊ�Ŵ��㷨����Ӧ�Ⱥ�����
�ɿɷ�˹������ͨ����������� U �� V ��ͬ�������CU ��CV �����۷���Ч����һ�� U �� V �У���һ���������ݼ����ǩ�����ı���������ͬ���������һ����Ԫ����������ݵ� i �� j ��ͬһ�����У���CU(i��j) = 1 ����֮CU(i��j) = 0 ���ɿɷ�˹�����۵Ķ���Ϊ��
 (1)
(1)
��ֵ�� [ 0��+��) ��Χ�ڱ仯��ȡֵԽС˵��ʵ�ʾ���������������ԽС��
���ǵ� Eps ��ʵ���� MinPts ����Ȼ�������Ƕ� Eps ����ʵ�����룬���� MinPts ʹ�ö����Ʊ��롣��ˣ����ߵĽ������Ӻͱ������Ӷ����в�ͬ������������У����ʵ� Eps ��MinPts ���ܹ����Ŵ��㷨�ҵ���
����ڲ������ϵõ��� Eps �� MinPts ����ݲ����ʽ���һ���Ĵ�����ʹ֮�ܹ�������ԭ���ݼ���֮��DBSCAN �㷨�������µõ��IJ�����ԭ���ݼ����о��࣬���ڵõ����õľ���Ч����
3.2 �Ľ����DBSCAN �㷨 MapReduce ��
Map Reduce ��һ�ָ�Ч�ķֲ�ʽ���ģ�ͣ�Ҳ��һ�����ڴ��������ɴ��ģ���ݼ���ʵ�ַ�ʽ���������ݴ�����Ϊ Map �� Reduce �����Ρ�
(1) Map����
Map���̴�������� < key��value> �ԣ�����һЩ��ʱ�м������� <key��value> �Է�ʽ�����Reduce ���̺ϲ���ʱ< key��value> �ԣ����о�����ͬ key ֵ�� value ���֣����������������Ҫʵ�� DBSCAN �㷨�IJ��л�����Ҫ�� Map �� Reduce ���̽�����ơ����ڵ㽫�յ������������鲢Ϊ <key��value> �ԣ���Ϊ Map ���������롣���ʶ pid ��Ϊ key ֵ������(coretag��usedtag��cid��xi) ��Ϊ value ֵ������ coretag ��ʾ�������Ƿ��Ǻ��ĵ㣬usedtag ��ʾ�������Ƿ��й����ʶ��cid ��ʾ���ʶ��xi ��ʾ�������ά������ɵ��ַ�����������Ϊ <key1��value1 > ��key1 ��ŵ��ʶ pid��value1 ������ʶcid��
(2) Combine ����
Combine ������ Map �����������Ϊ���룬�� pid ֵ��ͬ�ĵ��Ϊһ�飬�洢Ϊ�м��ֵ�� <pid��list(cid)>�����÷������� hash mod R ���м��ֵ�Էֳ� R ����ͬ�ķ����������� < key2��value2> �ԣ����� key2 ֵΪ���ʶ pid�� value2 ֵΪ������ͬ pid ���������С�
(3) Reduce ����
ִ�� Reduce ����Ĵ������յ� Combine ���̷�����Լ����Dz������� < pid��list(cid)> �����ȵ��ò�κϲ����� Hierarchical Merge ( )������һ�������������ĵ����Щ��ϲ�Ϊһ�࣬������ͳһ�����ʶ������乫�����Ϊ�����߽�㣬�Աȸù��������� Eps �����ں��ĵ�ľ��룬���仮���������ĺ��ĵ��������С�ֱ�����е㶼����Ψһ�����ʶ��
3.3 HDFS �ܹ�
HDFS �ֲ�ʽ�ļ�ϵͳ���и��ݴ��ԡ��߲����ԡ��߿����ԺͿ���չ�Ե��ص㡣��ʵ�����ݵĴ洢����ͬ�����ڱ��ط������Ͻ��еģ��뵥��ģʽ�µ����ݴ洢��ͬ�� HDFS ���ñ��ص�����̨���������������������ʹ�����������ͨ��ͨ�Ž������ӣ���֯��һ����Ϊ�߲�����ݴ���Ӧ�ó����ṩ����������ֲ�ʽ�ļ�����ϵͳ�����ģ GB ���� TB ��������ݣ������ǴӴ洢�������Ǵ����ٶȽ��п��ǣ�������������ʽ�������������洢�Dz���ʵ��[28]�������ݵĴ洢��ʹ�ö���������ڵ㣬��ʮ̨������̨�������࣬����ʹ�÷ֲ�ʽ�ļ�ϵͳ������Щ�ڵ�����ݴ洢����ͳһ������
3.3.1 Hadoop �� HDFS �� MapReduce �ܹ�
HDFS ��Ϊ Hadoop ƽ̨����õķֲ�ʽ�ļ�ϵͳ�����ܴ洢 TB ����ĵ����ļ�����֧����һ���ļ�ϵͳ�д洢��ǧ���������ļ���Hadoop �� HDFS �� MapReduce �ܹ���ͼ 3-1 ��ʾ��

ͼ 3-1 Hadoop �� HDFS �� MapReduce �ܹ�
Ŀǰ���ձ�Ӧ�õ� Hadoop �������汾��Hadoop1 �� Hadoop2���� Hadoop1�У�һ�� HDFS �ļ�ϵͳ�а���һ�����ؽڵ� NameNode��һ��ӽڵ� DataNode ��Hadoop2 �п�����һ�����߶���µ� NameNode�ڵ㡣 NameNode��Ҫ����ִ���ļ��������������ݿ����� DataNode ������ DataNode �����ݿ�Ķ�Ӧ��ϵ��NameNode���������ռ䡢���ݿ����ļ�����ӳ��������ݿ鸱��λ����Ϣ�ȡ�DataNode ���ڴ洢�ļ������ݿ飬���������ݶ�ȡ����� NameNode�����Ķ��ָ�
HDFS ��Ϊһ���ֲ�ʽ�ļ�ϵͳ����Ȼ���ǽ�����һ��ֲ�ʽ���ط������ڵ�֮�ϵ��ļ�ϵͳ�����Dz�ͬ�ڵ���״̬�µı����ļ�ϵͳ�����ǵ������ļ��洢���ơ���д���̶��кܴ�ͬ�� HDFS ���ļ����ʹ��̷�Ϊ���¼��㣺
(1) �û���Ӧ�ó������Ҫ���� HDFS �ļ�ϵͳ�����ȣ�Ӧ�ó���Ҫ���ļ�ϵͳ��client ���н�������������ļ���client ���յ���Ϣ֮�Ὣ�ļ����ύ�� NameNode����Ȼ�ͻ��� client ���� HDFSϵͳ����ɲ��֣������沿���HDFS�����ṩ client��
(2) �����ؽڵ� NameNode���յ��ļ���֮���ݱ����洢��Ԫ������Ϣ�������ļ�Ŀ¼���ҵ��ļ���Ӧ�����ݿ飬Ȼ���������ݿ��� DataNode �ϵ�λ�ã��õ��ļ��ĵ�ַ��Ϣ�������� client�����������û���
(3) �� HDFS�ͻ��˽��յ���Щ DataNode ��ַ֮�ͻ����� DataNode ���еؽ������Ӻ�������ݴ�����������ύ���������־��
Ȼ�������ݿ�Ĵ洢λ����Ϣͨ���Ǵ� NameNode�ϴ洢��Ԫ����Ŀ¼����ã���ͨ�����ʶ�Ӧλ����Ϣ�����ݽڵ��Ի�ȡ���ݣ�������ͨ�� NameNode�������ļ�����������������һ���治������� NameNode�ڵ�ij���ѹ����������ֽڵ����ƿ������һ����ͨ���ڲ�ͬ�� DataNode �ڵ�ͬʱ����һ���ļ�������������ݶ�д�ٶȡ�
3.3.2���Ŀ��
���� HDFS �� Hadoop ƽ̨�ϵ�ʹ�ã�����������Ŀ�꣺
(1) Ӳ����������һ������¶������Ӳ���쳣��HDFS ��������ǧ�Ƶĵ��ڵ���ɣ�����ÿһ���ڵ㶼�п��ܳ������⣬���Դ���ļ�غ�Ѹ���Զ��ָ��� HDFS ��ؼ���Ŀ��㡣
(2) ��ʽ���ʣ�HDFS ������Ӧ�ò�֮ͬ������������ʽ�ķ����ļ�ϵͳ����Ϊ���迼�����û�����������һ���Ǵ����������ݡ�����ʵ�����ݵĸ������������ݵĵ��ӳٸ��ؼ���
(3) ���ģ���ݼ����� HDFS �����еij���һ�㶼Ҫ������С�� G �ֽ����� T �ֽڣ����ݹ�ģ�ܴ����� HDFS Ҫ�ܹ��洢���ļ���Ӧ�þ��иߵĴ���������ڼ�Ⱥ�п��������ٸ��ڵ㡣
(4) ��һ���ԣ���һ��д��ζ����� HDFS �����ļ�ʱҪ���������֮һ�����ļ��ڴ���������رպ�Ͳ����ٸı������ˡ�������ʹ������һ���Ա�ü�ͬʱʹ�����ݷ���ʱ�ĸ�������Ҳ��Ϊ���ܡ�
(5) �ƶ������Ч�ԣ�һ������ĵļ��㣬����Ҫ�������������㷨Խ����ʱ�����Խ��Ч�������ǵ�����Ϊ���������ʱ������ij����ƶ�ÿ���ڵ�����ݵĸ��������ƶ����ݵ��㷨Ҫ����Ч��HDFS ��������������ģʽ��
4 �����ѵ�������õĽ������
4.1 �����ѵ�
һ����Ч�IJ�����ָ�����������ܹ�����ԭ���ݼ���������Ϣ�����ھ����㷨���ԣ���Ҫ�����ԭ���ݼ��Ͳ������ľ�����������ͬ�������Ҫ���ڲ����ʺͲ����������ʵ�ѡ��ʵ��ѡȡ12369�����ٱ��еľ�γ����Ϊ�������ݣ�����ʵ������п��ܳ��ֲ��ֵ����ܼ����ֵ�����ɢ�������������ѡȡ���ϴ���ɷ��������ȷ��
4.2 ����õĽ������
Ϊ��ȷ��������Ч�ԣ�������Ӧ���ܹ���Ч�ر���ԭ���ݼ��е�������Ϣ�������������С�����ڲ�����֮�ϲ����ľ�������������Ч�ġ�����������С���������ж�ŵ��߽�ȷ����
 (2)
(2)
���� N ��ԭ���ݼ���������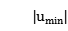 �����ݼ�����С�Ĵص��������÷�����ָ������������������
�����ݼ�����С�Ĵص��������÷�����ָ������������������ 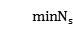 ʱ��ԭ���ݼ�����С�Ĵ���������
ʱ��ԭ���ݼ�����С�Ĵ��������� 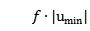 �����ݵ㱻ѡ��������ĸ��ʲ�С��
�����ݵ㱻ѡ��������ĸ��ʲ�С��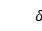 ��
��
�����������һ����ij�����ʽ����ʹ��ÿ�����ݾ�����ͬ�ĸ��ʱ�ѡ������������������ݼ�û��Ԥ��֪ʶ������������κ�Ԥ�ȴ�����ʱ�����������һ���ܳ��õķ����������ݼ����ɼ��ֲ�ͬ���͵�������ɣ��Ҹ������ݵ��������ܴ��ʱ�ֲ������һ����Ч��ѡ�����������ǵ�ʵ���У������ݼ���Ԥ��֪ʶ��Ԥ�ȴ������Ǻ��ѵõ��ģ���ѡ������������
5 ʵ������
����ƻ���Linuxϵͳƽ̨�£�������̨������ Hadoop ƽ̨��ϵͳӲ��ƽ̨Ϊ�����ͼ�����������ⶨ������������Ϊcore i5 CPU��MX250 2G���ԡ�20G �ڴ桢512G ��̬Ӳ�̡�
6 �ƻ����Ȱ���
|
ʱ�䷶Χ
|
�������
|
|
2019.9-2019.11
|
���Ĺ������������ϣ�����ؼ��������о�ѧϰ��
|
|
2019.11-2019.12
|
��ɿ��ⱨ�������������д��
|
|
2020.1-2020.6
|
���ʵ�ָ���ģ�鼰����ʵ����ԡ�
|
|
2020.7-2020.11
|
���ʡ��ij���ͬʱ����ʵ�����ݡ�
|
|
2020.12-2021.4
|
��ҵ���ĵ�д���ġ�
|
|
2021.5-2021.6
|
���������Ĵ�硣
|
�����
[1] ��ݼ. ������ʱ����˼ά�ص��о�[J]. �������ѧ, 2016(z2).
[2] �� 41 ���й��������緢չ״��ͳ�Ʊ���[R], �й�����������Ϣ����(CNNIC), 2018-1.
[3] Wigan M R , Clarke R . Big Data[J]. 2013.
[4] ����ΰ. ���ڵ���λ�õ��罻�����е������Ƽ�[D]. ���Ŵ�ѧ, 2017.
[5] ������. ���ڵ���λ�������ھ���û���Ϊ����[J]. ͨ�ż���, 2019(6).
[6] �� ΰ. MapReduce ��������о���Ӧ��[D]. �й���ѧ, 2018.
[7] Liu X , Yang Q , He L . A novel DBSCAN with entropy and probability for mixed data[J]. Cluster Computing, 2017, 20(3):1-11.
[8] �� ��. ���� Spark ƽ̨�� DBSCAN �ı������о�[D]. ������ҵ��ѧ, 2018.
[9] Gan J , Tao Y . DBSCAN Revisited: Mis-Claim, Un-Fixability, and Approximation.[J]. 2015.
[10] ������, �䴺��. һ�ָĽ��Ļ����ܶȵ�DBSCAN�����㷨[J]. ����ʦ����ѧѧ��(��Ȼ��ѧ��), 2007(04):112-115.
[11] ����, ����. �ƻ����²��� DBSCAN �����㷨�о�[J]. ɽ�����Ӽ���, 2017:90.
[12] Shi C , Cai Y , Fu D , et al. A link clustering based overlapping community detection algorithm[J]. Data & Knowledge Engineering, 2013, 87(Complete):394-404.ju
[13] ������. �����㷨����[J]. �������ѧ, 2015(S1):500-508+533.
[14] HANDL J, KNOWLES J, KELL D B. Computation cluster validation in post-genomic data analysis [J]. Bioinformatics, 2105, 21(15): 3201-3212.
[15] ������, ����, ����ɽ. ���л��Ŵ��㷨�о�����[J]. �����Ӧ��������, 2018, 35(11):7-13+86.
[16] ��־��, ����ΰ, �����, ������. ��������Ӧ���Ƶ��Ŵ��㷨�о�[J]. �����Ӧ���о�, 2015(11):3222-3225.
[17] ����, Ԭ����, �ڼ���. �Ŵ��㷨���Ż������е�Ӧ������[J]. ɽ����ҵ����, 2019(12):242-243.
[18] CELIK M, DADASER-CELIK F, DOKUZ A S. Anomaly Detection in Temperature Data Using DBSCAN Algorithm, 2011 International Symposium on Innovations in Intelligent Systems and Applications [C], Istanbul: Dogus
[19] ����. ����Ŵ��㷨����[J]. ��������, 2015, No.475(13):75-76+80.
[20] �� ��. ���� Hadoop ƽ̨�IJ��о������㷨�о�[D]. �����Ƽ���ѧ, 2018.
[21] ���Ź�. ���� Hadoop ƽ̨�� DBSCAN �㷨Ӧ���о�[D]. �㶫��ҵ��ѧ, 2013.
[22] ÷��. ����Hadoop�ķֲ�ʽ�ļ�ϵͳ�о�[J]. ���ֻ��û�, 2017, 23(44).
[23] O��Driscoll A, Daugelaite J, Sleator R D. ��Big data��, Hadoop and cloud computing in genomics[J]. 2013, 46(5):774-781.
[24] ��Ԫ��, ��ѧ��. Hadoop����[J]. ����֪ʶ�뼼��, 2018(9).
[25] Ashish Thusoo, Joydeep Sen Sarma, Namit Jain,��. Hive �C A Petabyte Scale Data Warehouse Using Hadoop[J].
[26] HUANG P, CHOU W, LIN W. Using SOM and DBSCAN-based models for landslide hazard and spatial correlations analysis: A case study in central Taiwan, 20th International Conference on Geoinformatics [C], Hong Kong
[27] ���ϼ, ��, ��ͮ��. ��������Ӧ�Ŵ��㷨�Ż���Լ�������Թ滮����[J]. ��ѧ��ʵ������ʶ, 2019(4).
[28] M. Maghsoudloo, N. Khoshavi. Elastic HDFS: interconnected distributed architecture for availability�Cscalability enhancement of large-scale cloud storages[J]. The Journal of Supercomputing, 2019(1).
