摘 要
时代在发展,技术在进步,互联网改变了全世界,各行各业都在这个互联网时代寻求自身的增长点,人们的日常生活也越来越离不开互联网。以租房为例,线下租房行业持续遭到冲击,越来越多的年轻人选择在互联网上挑选房源。然而网上信息混杂,数据来源众多,如何提升租房用户体验就成了一个值得探讨的问题。本文以此为研究方向,设计并实现了一个基于python开源爬虫框架scrapy的租房信息爬取系统,爬取互联网上多个含有此数据的网站。以城市为区分,将多个站点的数据存入非结构化数据库,再以数据库为连接,开发出一个以python开源web框架Django的基础的租房数据展示系统。与此同时,对爬取到的租房数据进行可视化处理。
关键词:scrapy;Django;非结构化数据库;数据可视化
ABSTRACT
The era is developing, technology is progressing, the Internet has changed the whole world. All walks of life are seeking their own growth points in this Internet age, and people's daily life is becoming more and more inseparable from the Internet.Taking renting as an example, the rental industry has been under constant impact, and more and more young people have chosen to choose housing on the Internet. However, online information is mixed and data sources are numerous. How to improve the user experience of renting has become a problem worth discussing. As a research direction, this paper designs and implements a renting information crawling system based on Python open source crawler framework scrapy, and crawls several web sites on the Internet. With the city as the distinction, the data of multiple sites are stored in the unstructured database, and then the database is used as the connection to develop a renting data display system based on the python open source web framework Django. At the same time, we can visualize the data of rental housing.
Keywords: scrapy;Django;NoSQL DB;Data visualization
目 录
摘 要 I
ABSTRACT II
1 绪论 1
1.1 研究背景及需求分析 1
1.2 国内外研究现状 2
1.2.1 爬虫技术概述 2
1.2.2 爬虫设计者面临的问题与反爬虫技术现状 4
1.3 研究目标及研究内容 6
1.4 论文的整体结构 7
1.5 本章小结 7
2 相关理论及技术 8
2.1 robot协议对本设计的影响 8
2.2 爬虫 8
2.2.1 工作原理 8
2.2.2 工作流程 8
2.2.3 抓取策略 9
2.3 python发展现状 9
2.5 scrapy架构 10
2.5.1 scrapy:开源爬虫架构 10
2.6 MongoDB数据库 13
2.6.1 NoSQL数据库介绍 13
2.6.2 MongoDB数据库介绍 13
2.7 python web框架Django 14
2.7.1 Django框架介绍 14
2.7.2 MTV模式 14
2.7.3 ORM模式 14
2.7.4 template模板语言 14
2.7.5 Django工作机制 15
2.8 semantic UI开发框架 15
2.8.1 semantic介绍 15
2.8.2 semantic开发 16
2.9 高德地图API 16
2.10 本章小结 16
3 系统分析与设计 17
3.1 系统分析 17
3.1.1 系统功能 17
3.1.2 爬取对象分析 17
3.1.3 模块设计 18
3.2 数据流 19
3.3 系统总体逻辑层次 20
3.4 本章小结 21
4 爬虫与数据存储、展示的具体实现 22
4.1 爬虫模块 22
4.1.1 环境搭建与前期分析 22
4.1.2 爬虫规则预处理模块 23
4.1.3 数据抓取模块 24
4.1.4 数据存储模块 29
4.1.5 反反爬虫模块 30
4.2 数据库设计 34
4.2.1 数据库环境搭建 34
4.2.2 数据库表设计 35
4.3 数据展示模块 35
4.3.1 django环境搭建 35
4.3.2 前端UI模块 37
4.3.3 网页架构搭建模块 39
4.3.4 前端与数据库连接模块 41
4.3.5 地图展示模块 42
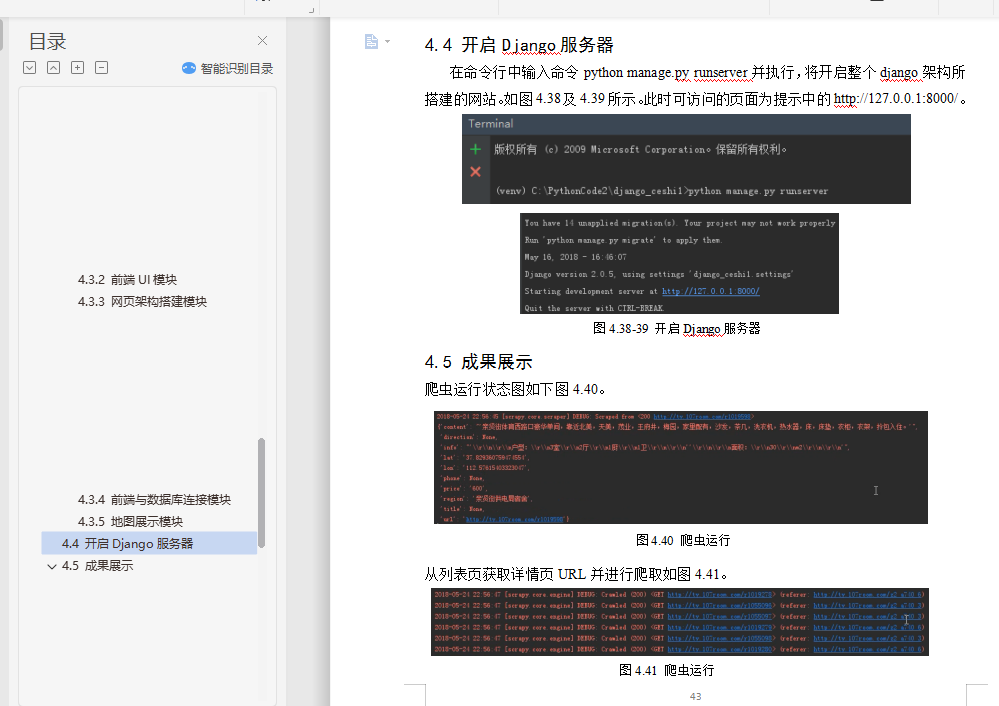
4.4 开启Django服务器 43
4.5 成果展示 43
4.6 本章小结 45
5 系统测试 46
5.1 测试环境及工具 46
5.2 系统功能性测试 46
5.2.1 数据爬取功能测试 46
5.2.2 数据展示测试 49
5.3 系统非功能性测试 49
5.4 本章小结 49
6 总结与展望 50
参考文献 51
致谢 52