��ԭ�ͱ�ʾ�Ļ���������������ⷽ��
ժҪ
���罻������������������ͼ�ͽṹ�dz���Ҫ��һЩ������������㷨ʹ�õ�һԭ��������ÿһ�顣��������Ӧ�ó�����,����ڲ�ͬ���͵����������Dz��ʵ��Ľ�ģ,������������罻�����ϵľ������ܡ�Ϊ�˽���������,���������������һ�����������Զ�ԭ��(SMP)�������ķ����� ��SMP��,��ÿ�������еĶ���Я����ͬ��Ȩ�����������ǵĴ����̶ȡ��������,ʹÿһ�������ɲ�ֹһ���ڵ������֡��ڵ��������������ԭ��Ȩ��,��������������ָ�����ǽ�ͼ�ͷ����������ɼ��������ʵ�����������ʵ��������ر���,�������ʱSMP�������á�����,�÷��������ṩ���ḻ����Ϣ, ����ԭ�����������е��������ģ�ͱȽϵİ����£��������������ڲ��ṹ��
1������
Ϊ������ʵ��������ϵͳ����֯�������и��õ�����,ͼ�е�Ⱥ��ṹ��һ����Ҫ����,��Ӧ�ñ����뿼��[1]�����,�������,���ԴӸ��ӵ���������ȡ����Ľṹ, ������������;���ѧ�����ѧ����Խ���������������൱��Ĺ�ע[2,3],��ϵͳ��ͨ����ʾΪͼ��һ����˵,һ����������������һ����ͼ�����Ľڵ����������ǽ������ӵ�,��������������ϡ�����ӵ�[4-6]��
���,����һ�о����������һЩȡ�õ��ش��չ�����е���������㷨�����ܻ�ӭ�ľ��䷽��֮һ��ͨ���Ż�ijЩ�����������������Ŧ����Girvan[7]�����һ������ģ�黯��������(ͨ����Q)�ͼ����㷨,��ͼ��˷��� [8 -10]������������о�����,����ģ�黯���㷨���ܼ�С��һ����ģ����������������������ķֱ�������[11]����һ���Ż���,Ҳ����˵,ģ�黯,�����ڸ�������ṹ�б�ʾ�IJ���ǡ��,�Ӷ�Amiri ����[12]�����һ���µ���������������һ����Ŀ���Ż������⡣��һ����ķ������Ƿֲ���༼������ʾ�ϲ����ּ�Ⱥ���˲����Ľڵ�֮���������,����ͼ����һ�������ֲ���[13-18]��Ҳ��һЩ����,�������[19]���źŴ�������[6 ,20], �����˹�ϵͼ�еĽڵ�ӳ�䵽nάŷ����ÿռ������ļ��νṹ,�������۷��������ھ����C��ֵ����(CM)[6], ģ��c��ֵ�㷨(FCM)[5,20]��֤������c��ֵ�㷨(ECM)[21]���ܱ��շ���Ȼ��,��ӳ������б�Ȼ��һЩ��Ϣ��ʧ������,��Щ����ԭ�͵ķ��������ı����Գ�ʼ���������С������罻����������õ������ṹ�ǻ���,һ��Ⱥ������Ŀ�����һ����,�����������а����쵼�ߵĽ�ɫ��Ҳ����˵,������һ��С��ij�Ա֮һ�Ǹ��õ�ѡ��,���������ж�������ġ�
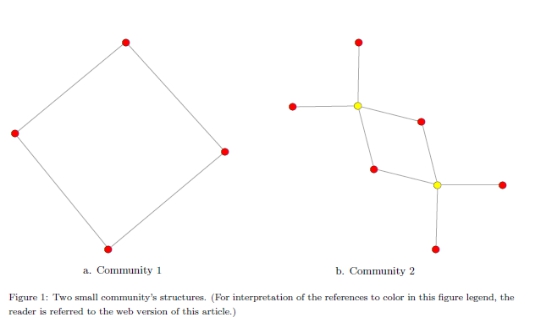
Ϊ��Ҫ�����Щ����, Jiang ����[6]�����һ������ k��λ�ĸ�Ч�㷨�������㷨ѡ����ߵĽڵ�����ֵ��Ϊԭ�͡���������ǰ�Ĺ�����,һ��֤�������Բ����������һ��������ܵġ�������������Ϊԭ��[22]����������ÿ��������ԭ�͵������Ƿdz���Ҫ��������⡣Ȼ��,��ijЩ�����ֻʹ��һ���ڵ�ķ�ʽ����������������ԶԶ�����ġ�Ϊ��˵��һ��ԭ�͵�����������ʾ,����ʹ�������������ṹ��ͼ1��ʾ����һ���������ĸ���Ա��ɶ��ڶ��������а˸���Ա�����Կ���,����ߵ�����,��С���е��ĸ��ڵ����κ�һ����������Ⱥ�ṹ���Dz�������,��Ϊ���ĸ��ڵ���û���κ�һ�����Ա��������������������д����ԡ���ͼ1����ȷ������,������Ա(��ɫ���)�ڰ˸��ڵ����Ǿ��жԵ��Եģ������ı�ѡ����Ϊ�����Ĵ���������ζ��ѡ�������е��κ�һ�������������ļ����к�ѡ�����ڵ㡣����Щ������,���ǿ��Կ���,����һЩ����,Ϊ�˲������ĸ�������Ľṹ,���ǿ�����Ҫ����ij�Ա,������һ���ڸ������б���Ϊԭ�͵����
��������뷨,�ڱ����������һ�����������ԵĶ�ԭ��(SMP)������ⷽ��������ֵ��Ϊ��ѡ����ԭ��������ÿ������,����ԭ���������Ƶ�Ϊ�Լ���������������ض���Ĵ����Գ̶ȡ�Ȼ��ÿ���ڵ������֮��������Ա�������,������Щ����֮�����ڵ㱻����Ϊ���ɸ�С��������������,����ǿ��һЩ���ڴ˹������������о����ײ�ͬ�Ĺؼ��㡣����,����������һЩ���ھ������ݼ��еĶ�ԭ�ͼ�Ⱥ����[23,24],���Ǽ���û�ж�������������̽���������������һ���µ�ʹ�ö�ԭ�͵�������ʾ���ơ�ʵ�������˹���ʵ����������ʾ�����ԭ�ͱ�һ�������������ĸ�ǿ��,�ر��Ƕ���û�������������ṹ��ͼ����ԡ����,�����ԭ��Ȩ�صĸ���,������һ����Ա���Լ�С��Ĵ����Գ̶ȡ�����ԭ��Ȩ��,SMPΪÿ�������ṩ����ֵ���������ʹ�����ܹ�����˽�һ���������ڲ��ṹ,���������������������Ƿdz���Ҫ���Һ����õġ�����, �ڸ�������ⷽ����,Ҳ���ܲ��ò�ͬ�����ƶȺ����ĵĴ�ʩ,�����ʹ������ʵ�ʵ�Ӧ�ó����и�ʵ�ò��Ҹ���
���ĵ����ಿ����֯���¡��ڵڶ���,��Ҫ�Ľ�����һЩ��������ͷ����Ļ���ԭ�����ڵ�����,��ϸ�Ľ����˶�ԭ�������ļ�ⷽ����Ϊ����ʾ���ǵķ�������Ч��,���Ľ������ڲ�ͬ���˹�����ʵ�����в������ǵ��㷨,���������еķ������бȽϡ����,�����ڵ���ڵó����۲����һЩ�۵㡣
2������֪ʶ
�ڱ��������������������罻������ص�һЩ����֪ʶ,�������ĺ������Զ���,ģ�黯��һЩ���ڵؾ����㷨,���������
2.1 �ڵ����ĺ�����
һ����˵,һ���������������ĵ���,��һ���罻������������ص�:������������ͳ�Ա����ϵ�����ҹ�ϵ��ƽʱ��ǿ,������ֱ������������ϵ����Щ�����Լ�������Ҳ��������Ҫ���á����,���������ĵ�����Ӧ�ò�����������Ⱥ�����,ҲӦ��ͬʱ�������������ڵIJ��ֵ���Ⱥ��������ڵ��������������ڵ�����ӵ�����,����������������Щ���ӵij̶ȡ�Gao ����[25]�����һ������֤�����ĵķ���,��ΪSemi-local֤������(ESC),�ǻ�������ܵ����ۡ���ESC��Ӧ����,ÿ���ڵ�����ͨ��������������(BBA)���������ij���Ⱥ�����,Ȼ��ʹ���������������Ϲ����������ں���Ҫ�ԡ�ESCֵԽ��,�ڵ�Խ��Ҫ��Gao ����[25]ָ��,���DZ����е����Ĵ�ʩ����Ч�ķ��������� ѧλ����(DC)����������(BC)����������(CC)��ESC��ϸ�ڼ�����̿�����[25]���ҳ���
��ͼƬ�������Դ�ʩ�е��κ�һ�Խڵ�֮�䶼�������е���ϵ��[26]���⼸���ڵ������˻��ڱ�����Ϣ�������Զ������Լ� �������˲�ͬ��ʩӦ���ڼ��ϼ���ϵı��֡��������Ǹ���һ�����������һЩ��ʩ����G(V,E)Ϊһ����������,V��N���ڵ�ļ��ϣ�E��m���ı�Ե����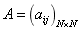 ��ʾ�ڽӾ���,����
��ʾ�ڽӾ���,����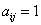 ��ʾ�ڵ�i��j֮����һ����Ե��
��ʾ�ڵ�i��j֮����һ����Ե��
(1) ��ͬ���ھӡ����ַ����ǻ�������뷨,��������һ�Թ����ھ�,���Ǹ����ơ����,�����Կ��Լ������ǹ�ͬ���ھӵ�����������:
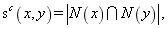 (1)
(1)
����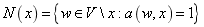 ��ʾ���ڵĶ��㼯x��
��ʾ���ڵĶ��㼯x��
(2)Jaccardָ����Jaccard��������ָ����һ�ٶ���ǰ,������Ϊ��
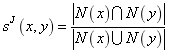 ��2��
��2��
zhou-lv-zhangָ����Zhou ����[26]�������һ���µij�����Դ������̵������Զ���������d(z)�ǽڵ�z�Ķȡ�
 �� (3)
�� (3)
Pan ����[27]ָ����Zhou��������������Զ���[26]����������������п��ܵ��²�ȷ�Ľ������Ϊ��������������һ�Խڵ�֮��Ľ��Ź�ϵ��ֱ���������Ǽ��������Ϊ�˿˷���һȱ��,����������µIJ��������У��ضԵ����ƶȽ�����Ϊ0:
 (4)
(4)
���ƶȶ���������Hu����[20]���������ͼ�ṹ�����������ǻ����źŴ����ġ�������һ����������N���ڵ�,ÿ���ڵ㶼��������һ�����˷ܵ�ϵͳ,�����Է��͡����պͼ�¼�źš����,ѡ��һ���ڵ���ΪԴ���źš�Ȼ��Դ�ڵ������������ھӺ�����������һ���źš�����,�ڵ���ź�Ҳ�ܶ��Լ������ǵ��ھӷ����źš���һ���ض���Tʱ�䲽����,���ǽڵ�ķֲ��ź��������Ա���Ϊ������������Ӱ��Դ�ڵ�����ء���Ȼ,�����������Ľڵ����,������������ͬһ�����Ľڵ��и������Ƶ�Ӱ�졣���,�ڵ�֮������֮��������ͨ�����������յ����ź�����֮��IJ�������ȡ��
2.2 ģ�黯
���,�������۱�����˶�����ķ�������������һ�ֹ㷺ʹ�õIJ�����Ϊģ�黯������Ŧ����Girvan[7]�����Q��������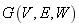 ��ʾһ����������,V��N���ڵ�ļ���,E�DZߵļ���,W��һ��N * N�ߵ�Ȩ�ؾ����Ԫ��
��ʾһ����������,V��N���ڵ�ļ���,E�DZߵļ���,W��һ��N * N�ߵ�Ȩ�ؾ����Ԫ��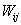 ��
��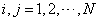 ����һ��Ӳ�̷�����K��
����һ��Ӳ�̷�����K��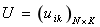 ,�������
,�������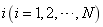 ����
����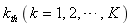 ������
������ ��1,��
��1,��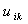 ��0����
��0����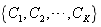 ��ʾK�Ķ����Ӽ�,Ȼ������ģ�黯���Ա�����Ϊ[1]:
��ʾK�Ķ����Ӽ�,Ȼ������ģ�黯���Ա�����Ϊ[1]:
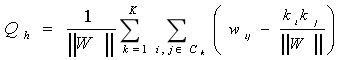 (5)
(5)
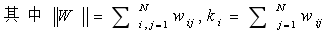 ��
��
��ȻFortunato��Barthelemy [11]���ƻ���ģ�黯���ַ������о����ԣ�����Q��ʩ����ʵ���б�֤���Ƿdz���Ч���������ۡ�����,����Newman��ģ�黯�з���һЩ��������[28]��Ϊ�˽����Щ����,���ǻ������һЩ�µ�ģ�黯��ʩ[28.29]���������г���Chen����[28]��������-��С(MM)ģ�黯���ܣ�������������ȷ������������������MMģ�黯��ͼ��������ڱ�������ͬʱ����������С�������û�����ķǹ����趨�ķǹ����Ե���Ŀ:
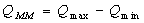 ��6��
��6��
����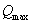 ��Qģ�黯��ԭʼͼ,��Ȼ
��Qģ�黯��ԭʼͼ,��Ȼ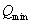 ��ͼ
��ͼ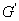 �IJ��䲿��,ͼ
�IJ��䲿��,ͼ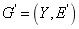 ���������û�����ı�M���������������Ͽ����ӵĽڵ�i��j�Ƿ���أ���
���������û�����ı�M���������������Ͽ����ӵĽڵ�i��j�Ƿ���أ���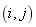 ����M����صģ���
����M����صģ���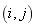 ������Mʱ�Dz���صġ�Ҳ����˵���
������Mʱ�Dz���صġ�Ҳ����˵���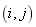 ������E��Mʱ������
������E��Mʱ������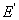 �ġ���������M,������ר�Ҹ��������߸���ԭʼ�ṹ�����塣
�ġ���������M,������ר�Ҹ��������߸���ԭʼ�ṹ�����塣
2.3 һЩ���Ϸ��ֵľ��䷽��
�ڵ��Ľ����ǽ�������ĸ��㷨����������������бȽϣ����е������㷨������k��λ�㷨[6],����ģ�黯�Ż��㷨(MMO)[8],��Ҫ��������(LE)�㷨[30], ��ǩ����(LP)�㷨[31],����Ϣ��ͼ(InfoMap)�㷨[32]��������������Ƕ������ַ�������һ����̵ij�����
����ģ�黯�Ż��㷨MMO�ǻ���ģ�黯�Ż�������ʽ����,���Ҹ��㷨��Ϊ������,���Ҳ�ͣ���ظ����ڵ�һ�εĿ�ʼ,���类��Ϊ��N�飬ÿ��ֻ��һ���ڵ㡣Ȼ��ÿ���ڵ�i, ���ܱ����õ�һ���µ�����(��������������һ�������ھ�)���Ի������ģ�黯�����ʵ��ģ�黯û�н�һ������������ô��һ����û����ɵ�,���ڶ��ΰ�������һ���µ����磬�����еĽڵ��������ε���������,Ȼ���һ�ο��Ա�����´�����ͼ�������á�Blondel����[8]ָ��,MMO�ͼ���ʱ����Գ�������������֪��������ⷽ����
Ŧ��[30]����,ģ�黯���Լ��ر�ʾΪ��һ������������ֵ�������������Լ�ʹ�þ����Ե�LE�㷨ʶ�ϡ���ͼ���ȷ�Ϊ���飬����Ԫ�صļ���ģ�黯���������������ֵ����Ӧ��������,Ȼ����Ը������Ƶ�������ָ�ɸ���ļ��ϡ���������Գ�����������Ҫ�ҵ��κ��ض���С[30]��С��ʱ����Ҫ���������㷨LE�ȱ��������������á�
Raghavan����[31]�о��˱�ǩ�����㷨LP,��ֻ��������ṹ���Ȳ���Ҫһ���Ż���Ԥ�����Ŀ�꺯����Ҳ����Ҫ���ϵ�Ԥ����Ϣ�������ģ����ÿ���ڵ�����һ�����صı�ǩ���г�ʼ����Ȼ��ÿ���ڵ�������Ĵ�����ھӵ�Ŀǰ��ÿһ����Ϊ��ǩ�����������������С���еĽڵ�������������γɼ��϶��صı�ǩʱ�γ�һ����ʶ��
��Ϣ��ͼ�㷨InfoMap����ʵ��ϵͳ�� ��������ʹ����������Ŀ���������Ϊ��Ϣ����,ͼ����Ȼ��ת���Ѱ����С����ʾ����������[1]�����⡣������ͨ��ѹ���������Ϣ��������ɢ������ͼ�е���Ϣ�Ӷ��ֽ������ģ���[32]��Ⱥ��ṹ�Ĺ��ɺ����ǵĹ�ϵ��ͨ����ͼ����ӳ�ġ�
k��λ�㷨����Jiang���������[6],����K-means�㷨���ƣ�ʹ��һ������ĵ������ԡ�����, K�ڵ�Ķ���Ҳ������ߵȼ����ı�ѡΪ��ʼ���ӡ����ֳ�ʼ�����ƿ��Կ˷������ʼ���Ĵ��������⣬��Ӧ�ó����л���ԭ�͵ľ������k-means�㷨���ơ�Ȼ�����Ӻͼ�Ⱥ��ǩͨ��ʹ�õ����������и��½��档��֮ǰ��ʾ�ķ�����ѡ��K������Ա�����DZ˴˿�����ȫ����һ�����˵ļ��ϣ������ܲ�������ȫ����һ�����ϡ��ⷴ��������,��ڵ㱻���������������飬���ȷ��
3����ԭ�ͼ��ϼ�ⷽ��
�����ィ��ʹ�����ǵķ�����֮����3.1���������Ȩ�صĸ���(Ҳ��Ϊԭ��Ȩ��),�����㷨����3.2������ϸ���ܡ�ȷ�����ż��ϵ������������㷨�����⽫�ֱ���3.3��3.4�������ۡ�
3.1 ԭ��Ȩ��
����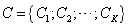 ��ͼ
��ͼ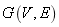 ��һ������,
��һ������, 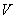 ��һ��ڵ㣬
��һ��ڵ㣬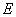 ��һ��ߵļ��ϡ�ͼ�е�
��һ��ߵļ��ϡ�ͼ�е�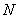 ���ڵ������
���ڵ������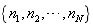 ����ʾ������
����ʾ������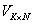 ��ʾ
��ʾ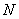 ���ڵ��Ӧ����
���ڵ��Ӧ����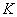 �����ϵ�ԭ��Ȩ�ء��ڷ���֮ǰ,һ���ڵ�����ļ�ֵ������������ڵ������ļ����а������Ľ�ɫ�����������,�ڵ�j�ڴ����Լ�Ⱥ
�����ϵ�ԭ��Ȩ�ء��ڷ���֮ǰ,һ���ڵ�����ļ�ֵ������������ڵ������ļ����а������Ľ�ɫ�����������,�ڵ�j�ڴ����Լ�Ⱥ �ĸ��������̶ȿ����Ƶ�����:
�ĸ��������̶ȿ����Ƶ�����:
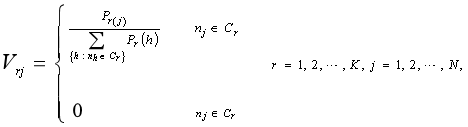 (7)
(7)
���� ������ͼ����Ӧ������
������ͼ����Ӧ������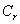 �еĽڵ�
�еĽڵ�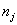 �����ġ�Ȼ��,����һ���ڵ�
�����ġ�Ȼ��,����һ���ڵ�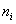 ��
��  ������
������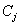 ֮��������Կ�����
֮��������Կ�����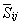 ����ʾ,���µõ�
����ʾ,���µõ�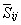
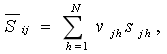 (8)
(8)
����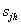 �ǽڵ�
�ǽڵ�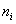 ��
��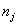 ֮������Ƶ㣬����Eqs���ӷ���ʽ���ڹ�ʽ(7)��(8)���ǿ��Կ���
֮������Ƶ㣬����Eqs���ӷ���ʽ���ڹ�ʽ(7)��(8)���ǿ��Կ���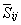 �ǽڵ�
�ǽڵ�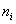 ������
������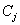 �����нڵ�֮�������Ե�Ȩ��֮��,����ʹ�õ�Ȩ���ܺͣ������ڽڵ�������Լ��������Ĺ��ס�
�����нڵ�֮�������Ե�Ȩ��֮��,����ʹ�õ�Ȩ���ܺͣ������ڽڵ�������Լ��������Ĺ��ס�
3.2����㷨
����SMP�㷨������罻���缯�Ͻ����㷨1�н����ܽᡣ��ʵ��SMP��һ���䶯��k - means, K-medoids��k��λ�����㷨��SMP���������������㷨���������ڸ���ԭ�͵ķ�ʽ��ͬ��k �C means�㷨ʹ��ƽ��ֵ����ʾÿ���࣬��K-medoids��k��λ�����㷨ʹ��һ��������ܵġ���������ʾ�ࡣ�෴,SMP����һ����Ч��ԭ�ʹ���������С���е�ÿ����Ա��ԭ��Ȩ�ء����ڼ��Ͻṹ�����ͷ���,��ʾ��Ⱥ�ķ�ʽ�����˶�ԭ�ͣ���ʹ��ʵ�ʵ�Ӧ�ó����и�Ϊ����������,SMP������k - means��Ҫ���ٵĵ�����ʹ�㷨����һ�¡�
��ע:����������,SMP�ṩ������һ����(Ӳ)��������ķ������ڵ� ������
������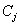 ֮��������Կ���ͨ��Eq�����(8),�ڵ�ij�Ա
֮��������Կ���ͨ��Eq�����(8),�ڵ�ij�Ա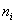 ������
������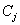 �������¶���:
�������¶���:
 (9)
(9)
ͨ��FCM�㷨��õ�������ʽ�ij�Ա�����dz����Ե�,���г�Աֵ�����һ�������뼯Ⱥ����Ծ����dzɷ��ȵġ�ͬ���ģ����������ȡ��������Eq(9)�ij�Ա���Ѿ�������ģ����Ա����֮һ��,���������֡�ƽ�ȵ�֤�ݡ�(��Աֵ��ƽ�ȵ����Ʒ)�͡���֪��(���г�Ա��ֵ����ȵ�,���dz��ӽ�����)[33,34]������ڵ� ��������֮���ǵȾ��
��������֮���ǵȾ��
�㷨1:���������Զ�ԭ��(SMP)���ϼ���㷨
����: 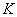 ,���ϵ�����;
,���ϵ�����; 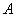 �ڽӾ���;
�ڽӾ���; 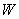 ,Ȩ�ؾ���(����еĻ�);
,Ȩ�ؾ���(����еĻ�); 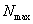 ,���������������
,���������������
��ʼ��:
(1)ѡ��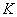 �ڵ�����������Ϊ��ʼԭ�͡�
�ڵ�����������Ϊ��ʼԭ�͡�
(2)����ͼ�����������ڵ�֮��������Ծ���
(3)��ȡ�ڵ��ԭ��֮��������Ծ������Ľڵ���������ԭ�������ļ���,���õ��ij�ʼ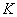 ��ͼ:
��ͼ: 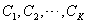 ��
��
�ظ�
(4)���¾���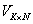 ����¼
����¼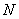 �ڵ��ԭ��Ȩ�أ�ʹ֮��Ϊʹ��Eq�Ļ��ڵ�ǰ�����
�ڵ��ԭ��Ȩ�أ�ʹ֮��Ϊʹ��Eq�Ļ��ڵ�ǰ�����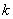 ����
����
(5)��Eq.(8)����ڵ�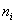 �ͼ���
�ͼ��� ֮��������ԣ�Ȼ��Ⱥ�����ÿ�����ڼ��ϵĽڵ������Ƶĵ����
֮��������ԣ�Ȼ��Ⱥ�����ÿ�����ڼ��ϵĽڵ������Ƶĵ����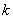 ���ϡ�
���ϡ�
ֱ������̽��ļ���ֵ���ٸı������Ĵ�����Ϊ���ֵ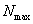 ��
��
���:ÿ���ڵ�ij�Ա����ÿ���������г�Ա��ԭ��������
��һ���������, ���ۼ��������Եľ���ֵ������ÿ����Ⱥ��Ա��������ͬ�ġ����,ģ����Ա����Ӧ���ڼ����������(�쳣ֵ),��Щ�쳣ֵ��ȻԶ��������һЩ���ϵȾ�[34]����SMP��,ԭ��Ȩ�ؿ��������ǽ���������,���ǽ���4.2����ϸչʾ��
3.3 ȷ������������
��SMP�㷨�ĵ�һ��,���ڼ���(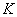 )�����Ķ�����ϢӦ��ϸ˵������Ҳ�ǹŵ�CM��FCM�����е�һ���������⡣��ʵ��, Ϊ����ԭ�͵ľ����ȷ�����������ļ�Ⱥ��һ�����ŵ����⡣�ֵķ������������������ڼ�����Ч��ָ���������ǴӼ������Ͻṹ���ֲ�ͬ��
)�����Ķ�����ϢӦ��ϸ˵������Ҳ�ǹŵ�CM��FCM�����е�һ���������⡣��ʵ��, Ϊ����ԭ�͵ľ����ȷ�����������ļ�Ⱥ��һ�����ŵ����⡣�ֵķ������������������ڼ�����Ч��ָ���������ǴӼ������Ͻṹ���ֲ�ͬ��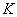 ֵ��Ѱ��һ������������Сֵ�����ֵ[5��20��35]��������MMģ�黯 (Eq.(6))����������һ���ʵ���
ֵ��Ѱ��һ������������Сֵ�����ֵ[5��20��35]��������MMģ�黯 (Eq.(6))����������һ���ʵ���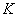 ֵ��ģ�黯ֵ��ʾ�����ϵ���������ģ�黯�ﵽ���ʱ,���ǿ��Եõ���õ�
ֵ��ģ�黯ֵ��ʾ�����ϵ���������ģ�黯�ﵽ���ʱ,���ǿ��Եõ���õ� ��
��
3.4 SMP�㷨�ĸ�����
SMP�ĸ������ɼ��������Ժ����Ľڵ�ĵ����Ĺ�����ɡ��������ʹ���ź������Ժ�֤��semi-local���Ĵ�ʩ,���������ڵ��Ľڽ�������,��Ӧ��ʱ�临�Ӷ�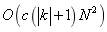 [20]��
[20]�� [25],����c�Ǵ���������,
[25],����c�Ǵ���������,  �������ж����ƽ���̶�,N�ǽڵ����������������������k �C means�з�����Ψһ�������Ǹ���ԭ�͵IJ��ԡ�k - means���㼯Ⱥ�е����г�Ա��ƽ��ֵ,��SMP��ͼ�ҵ����г�Ա��ԭ�����������ż�����ͼԶС��ԭʼ����,SMP��ԭ��Ȩ�صĸ��¹��̲�����ķѺܶࡣ�������K�е�Ԫ�������ǹ̶���,K - means�����㷨��ʱ�临�Ӷ���
�������ж����ƽ���̶�,N�ǽڵ����������������������k �C means�з�����Ψһ�������Ǹ���ԭ�͵IJ��ԡ�k - means���㼯Ⱥ�е����г�Ա��ƽ��ֵ,��SMP��ͼ�ҵ����г�Ա��ԭ�����������ż�����ͼԶС��ԭʼ����,SMP��ԭ��Ȩ�صĸ��¹��̲�����ķѺܶࡣ�������K�е�Ԫ�������ǹ̶���,K - means�����㷨��ʱ�临�Ӷ���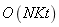 ,����t�ǵ�������������ˣ�SMP���ܸ�������
,����t�ǵ�������������ˣ�SMP���ܸ�������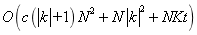 ��ֵ��ע�����,SMPͨ����Ҫ���ٵĵ�����
��ֵ��ע�����,SMPͨ����Ҫ���ٵĵ�����
4.ʵ����
�ڱ����е�һЩʵ�����ڼ�������ɵ�ͼ�κ���ʵ������������ִ�еģ������Ľṹ��Ԥ����֪�ġ�����k��λ[6],����Ҳ�Ƚ�SMP�������ĸ����䷽��:�༶ģ�黯�Ż��㷨(MMO)[8]����Ҫ��������(LE)�㷨[30]����ǩ������LP���㷨[31]����Ϣӳ���㷨(InfoMap)[32]����2.3�����Ѹ������Ѿ���õ������ṹͨ����֪�ļ�Ч��ʩ������,Ҳ����˵��ȷ�Ժ�NMI(��淶����Ϣ)�����������еõ��˻������������е���ʵ�����趨,ȷ�Ժ�NMI�����ˣ��ƻ�����(����ʵ��)���㷨�Ľ��֮��������ԡ�ͼ��A��B����������NMI,I(A,B),����ͨ�����¹�ʽ����
 (10)
(10)
���� ��
��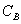 �ֱ��ʾ��������A��B������������
�ֱ��ʾ��������A��B������������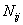 ��ʾ�����Ԫ��
��ʾ�����Ԫ��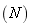
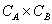 ,����i������A����������j�����Ľڵ�����������N�ĵ���i�ܺͱ�ʾΪ
,����i������A����������j�����Ľڵ�����������N�ĵ���i�ܺͱ�ʾΪ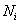 ,��j���ܺͱ�ʾΪ
,��j���ܺͱ�ʾΪ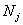 ��ȷ�Ժ�NMI�����ڵ���ȷ����ı���,���������������ṹ�ͼ���֮���һ����,[20,36]���Բ�ͬ�������Ժ������Բ����SMPӦ���е�Ӱ�죬���ڵ�һ��ʵ�������ۡ�֮��,���ǽ�����ʵ������ʹ��֤��semi-local�����Ժ��ź��������ڽ��������в��ԡ�
��ȷ�Ժ�NMI�����ڵ���ȷ����ı���,���������������ṹ�ͼ���֮���һ����,[20,36]���Բ�ͬ�������Ժ������Բ����SMPӦ���е�Ӱ�죬���ڵ�һ��ʵ�������ۡ�֮��,���ǽ�����ʵ������ʹ��֤��semi-local�����Ժ��ź��������ڽ��������в��ԡ�
4.1 ��������ɵ�ͼ��
�㷨����ͨ���������ɵ��˹�������Ա�,Ҳ����Girvan��Newman[3](GN)��Lancichinetti��[37]��(LFR)���硣����ǰ��,ÿ�������ܹ���N = 128���ڵ㣬 �ĸ����ֵļ�����ÿ����32���ڵ㡣ÿ�������ƽ��������Ϊ16������һ�������Ľڵ�, �ڼ����ڲ����ӵ�����ͬ���ƽ����������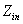 ����ʾ����8 �C 16֮��仯������֮��ߵ�ƽ������,��
����ʾ����8 �C 16֮��仯������֮��ߵ�ƽ������,��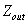 ����ʾ����8 �C 0֮��仯��
����ʾ����8 �C 0֮��仯�� ��ֵ����,��ʾ����ļ��Ͻṹ�������ԡ�
��ֵ����,��ʾ����ļ��Ͻṹ�������ԡ�
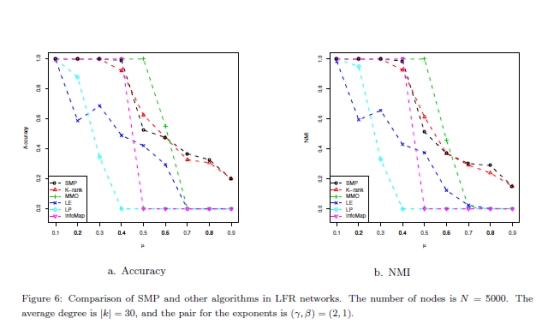
��ֵ��һ����ǣ���Ӧ�ó�����SMP�㷨�����Ľ��飬��ͬ�������Ժ������Բ�ȿ��Ա������������ź������Ժ�֤��semi-local�����ġ���ʹ��ESC����������ֵ,�����ֲ�ͬ�����Զ����Ľ�������ź�������,��Jaccardָ���Լ�Pan����[27](ͼ����Pan����ʾ)��Zhou����[26](ͼ����Zhou����ʾ)����IJ����������ͼ2-a��ʾ����ͼ���ǿ��Կ���,�ź������ԵĽ����������NMIֵ���Ե�ָ��������á����������ǿ��Եó������Ľ���:ȫ�������Դ�ʩ�����źŵ������ԣ��Ⱦֲ��������Ը�������SMP��ͼ2-b�����˵������Բ�Ȳ�ͬ����������ָ��(�ź�)��ͬʱSMP����Ϊ�����Կ���,ESC��PR���ĸ���ʩ֮���Ǹ��õģ�����ESC, PageRank(PR)[38],ѧλ����(DC),��������(CC)����Ȼ��ESC��PR֮��û�������IJ��죬����ESC�����ܱ�PR���ȶ������IJ�û�м��бȽ������Ժ������Բ�ȵIJ�ͬ������ڽ�������ʵ��������ֻ�����ź������Ժ�֤��semi-local���ġ�
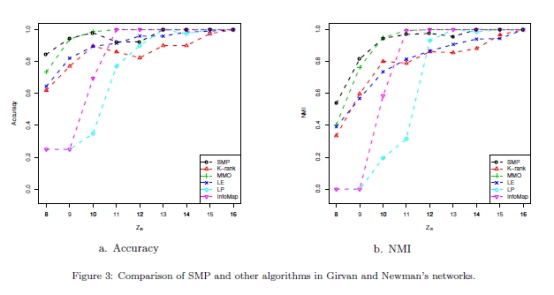
����ÿ�� ��ʵ���ظ�20�Σ�������ȵ�ƽ��ֵ����¼��ͨ����ȷ�Ժ�����SMP��NMI�������������㷨�ļ������ָ����ƽ��ֵ��
��ʵ���ظ�20�Σ�������ȵ�ƽ��ֵ����¼��ͨ����ȷ�Ժ�����SMP��NMI�������������㷨�ļ������ָ����ƽ��ֵ�� ��ʾ����ͬ��ֵ���ֱ���ͼ3-a��ͼ3- b���г��������������
��ʾ����ͬ��ֵ���ֱ���ͼ3-a��ͼ3- b���г�������������� ��ֵ��ʱ����ȷ�Ժ�NMI�������з������ֵĶ��ܺá�Ȼ��,��
��ֵ��ʱ����ȷ�Ժ�NMI�������з������ֵĶ��ܺá�Ȼ��,�� С��10�������в�ͬ�ı��֡�LP��InfoMap�Ľ�������,��Ϊ������
С��10�������в�ͬ�ı��֡�LP��InfoMap�Ľ�������,��Ϊ������ < 10ʱ���ܹ�����SMP��MMO�����з���������õġ����ܵ�
< 10ʱ���ܹ�����SMP��MMO�����з���������õġ����ܵ�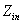 = 11 ��
= 11 ��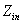 = 12ʱMMO����SMP,�����Ʋ������ԡ���
= 12ʱMMO����SMP,�����Ʋ������ԡ���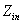 С��ʱ��(�ر���
С��ʱ��(�ر��� = 8ʱ)��SMP��MMO�����Ե����ơ�����,����
= 8ʱ)��SMP��MMO�����Ե����ơ�����,����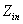 �ļ�С��SMP�����ܲ����������������������������½�������ʾ�ˣ����������Ƿ��������ļ��Ͻṹ��ʹ�ö��Ա����ԭ��Ȩ���ܹ�����ȷ������Ⱥ�Ľṹ�����������ڲ���һ����������ͼ������
�ļ�С��SMP�����ܲ����������������������������½�������ʾ�ˣ����������Ƿ��������ļ��Ͻṹ��ʹ�ö��Ա����ԭ��Ȩ���ܹ�����ȷ������Ⱥ�Ľṹ�����������ڲ���һ����������ͼ������
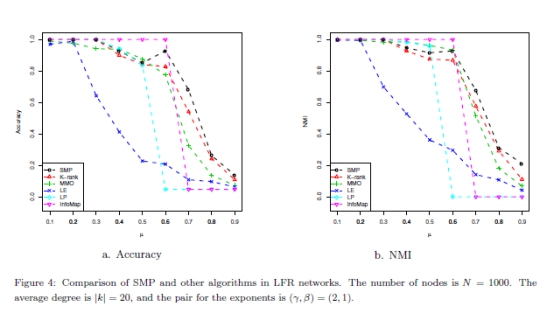
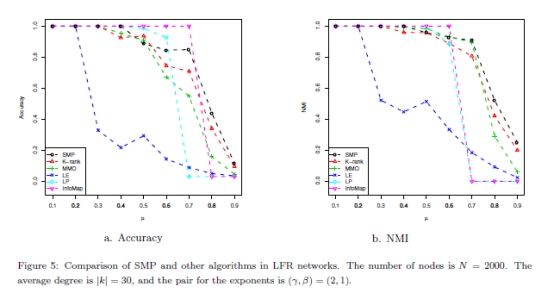
LFR������[37]��һ��Ϊ��������ṩ����������,����������ʵ�������д���һЩ������ͳ�����������칹�̶Ⱥ�������С�ķֲ��������ֲ�ͬ��LFR���磨1000��2000��5000�ڵ㣩�����Ľ�����ֱ���ͼ4�C6��չʾ��ͼ����x����˵���IJ������� ͼ��ʶ���������Ƿ�����ȷ���������� ��С,ͼ���кܺõ������ṹ�������������,�������еķ��������ֺܺá������ǿ��Կ�������
��С,ͼ���кܺõ������ṹ�������������,�������еķ��������ֺܺá������ǿ��Կ�������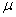 �ܴ�,SMP�Ľ����NMI��ֵ��Խϴ�SMP�����ܺ�k��λ��������������������������½���SMP����������k��λ���ر��ǵ� �ܴ�ʱ,����ܹ����������Ķ�ԭ�ʹ������ܵ���˵�����������͵Ļ�����,���������Ƿ��������������ṹ��SMP���ʺ������硣
�ܴ�,SMP�Ľ����NMI��ֵ��Խϴ�SMP�����ܺ�k��λ��������������������������½���SMP����������k��λ���ر��ǵ� �ܴ�ʱ,����ܹ����������Ķ�ԭ�ʹ������ܵ���˵�����������͵Ļ�����,���������Ƿ��������������ṹ��SMP���ʺ������硣
4.2 ��ʵ���������
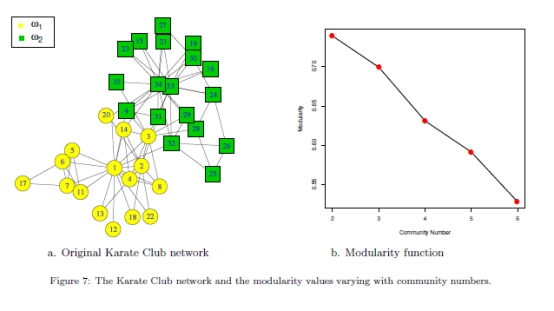
A. Zachary�Ŀ��ֵ����ֲ�����Ӧ������ʵ�������类����ķ�������Ч�Խ������������ǵ�һ�β�����һ���㷺ʹ�ü��ϼ��Ϊ���Ľṹ�������ֵ����ֲ���[39],����Τ�����������о��ġ����������34���ڵ��78������ɣ������˾��ֲ��ij�Ա֮������ꡣ�ڿ����ڼ䣬���ֲ��Ĺ���Ա��ָ��Ա֮�������ִ���������վ��ֲ����ѳ�������С�ľ��ֲ����ֱ���Χ�ƹ���Ա��ָ��Ա(�μ�ͼ7-a)��
ģ�黯��ֵ�Ͳ�ͬ�����ļ��ϣ���ͼ7-b����ʾ����K = 2ʱ��ģ�黯�����ķ�ֵ�����������������������ʵһ�µġ��Ѿ����ֵļ����ڱ�1��˵������1Ҳ��ʾ����ÿ���������е�ԭ��Ȩ�ء��������ǿ�����,�ڵ�1�Լ���1�����˴ֹ���,������2������Ҫ���ǽڵ�34����֤ʵ�����������Լ��ļ����е����Ľ�ɫ���෴,�ڵ�17 �ͽڵ�25�����ǵ����ڿ����������Ǻ���Ҫ�������ǵ�ԭ��Ȩ�ض��ԡ����ǿ��Կ���,��ͼ7-a��,�������ڵ㶨λ�ڱ�Ե���֡����,�������SMP��ⷽ����ԭ��Ȩ�صİ����£�����ʹ���Ǹ��õ�����ͼ�Ľṹ��
B.���ֵ����ֲ�����������һЩ�е㡣�ڸò�����,�����е㱻���ӵ����ֵ����ֲ�ԭʼ��������(��ͼ8-a)����һ���ǽڵ�35,��ڵ�18,�ڵ�27ֱ����������һ���ǽڵ�36,��ڵ�1�ͽڵ�33���������Կ������ڵ�36���������ϵ����ӹ�ϵ�Ƚڵ�35��ǿ����������һ����ʵ������Щ�ڵ����ӵ��ڵ�36ʱ���������Լ���Ⱥ���а������쵼��ɫ�����ڵ�35�������ʽڵ����ӣ��������ʽڵ������ǵ�����ֻ�����ߡ�С�����ؽ�Ҫ�Ľ�ɫ��ģ�黯����ֵ���Ų�ͬ�ļ������仯����һ������ͼ8-b��������������ڱ�2����ʾ��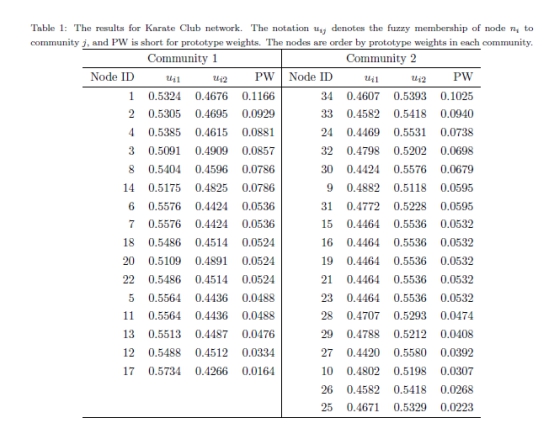
�ӱ�2���Կ���,�ڵ�35��36��ģ����Աֵ�����������ϼ�������ͬ�� (���Ƶ���0.5)����Щ������ܷ�ӳδ֪�ԺͲ�ȷ���Ե�������Ϊ�ڵ�35��ÿ��������ֻ��һ������Ľڵ�������������ǶԼ��ϵ���Ĺ�����δ֪�ģ��������ǿ���˵�ڵ�35�Ǹ����⡣�෴,�ڵ�36�����������еĹؼ���Ա(�����а�������Ҫ��ɫ)��������˴��ڲ�ȷ����,�����ǽڵ�36�����ĸ����ϵ�δ֪�ԡ������������,�ڵ�36�����������ϵ� ���á���Ա,���ڵ�35�ǡ����Ա������֮ǰ���ᵽ�ģ����������Բ�ȷ���ڵ����Ⱥֵ������ȳ�Ա����������ģ����Ա�е���������ԡ���SMP��,ԭ��Ȩ�ؿ�����������������ͼ����Ⱥֵ�����2��ʾ,�ڵ�35��ԭ��Ȩ�����ڼ�������С�ģ����ڵ�36�Ĺ���ԶԶ�����ڵ�35�����,�ڵ�35������������û�й���(�ڵ�35�Լ���1��ԭ��Ȩ����0.0052,�Լ���2��ԭ��Ȩ����0),�����Ա���Ϊ��һ�����ࡣ������ӽ�һ��˵������һ��ʵ��ԭ��Ȩ��ȷʵ�ܹ�ʹ���Ǹ��õ�����ͼ�ͽṹ,�ر����������м���쳣ֵ��

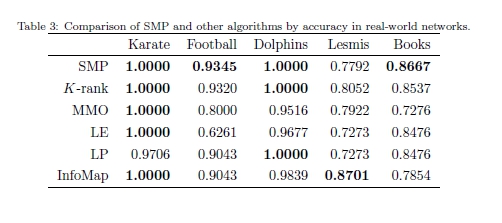
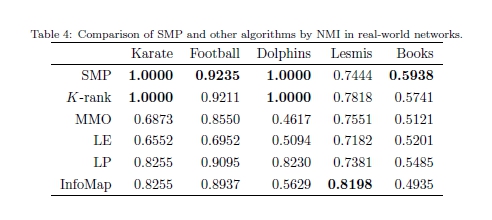
�������ĸ�ʵ��ͼ���У�Ҳ�����ǵķ��������˲���:��ʽ��������,��������,Lesmis����������鼮����[1]������ָ��ֵ,ȷ�Ժ�NMI,�������۲�ͬ���������ܣ��ֱ��ڱ�3�ͱ�4���г�[2]���ӱ��п��Կ���,�ڴ��������£�SMPӦ�ý���ڼ��Ͻṹ�о�����ߡ���NMI���ܲ�������,SMPҲ���������㷨��Ӧ��ע�����,һЩ����Ϊ�����ṩ���Ǹ߾�ȷ�ȣ���NMI���������������������ʵ:���Ǿۼ��ڵ㵽̫��С�ļ��ϡ�k��λ��SMP�ķ��������ǻ��ڽڵ������ԡ�һ����˵�������ַ������������ã���Ч�Կ��Թ����ڶ��������Եĸ����ܡ���ԭ���ǣ�SMP��k��λ����ʵ�����й����ĸ��ã���Ҫ����Ϊ��ԭ�ͱ�ʾ���ϵ�Ӧ�á�������Ĵ���ʵ����,���ǿ����ܽ�SMP����עĿ����������:
1)�ڷ���������,SMPʹ�ö��ԭ�ʹ������ϡ�����һ�����õ���չ���еļ��ϼ�ⷽ��������ֻ������һ��ԭ��,�����Ƿ�����ͼ����һЩ���ӵ�Ⱥ�ṹ��
2)ԭ��Ȩ��,��Ϊ����Ʒ�ļ����,����һ���Ƕȣ�Ϊ�����ṩһЩ����Ⱥ��ṹ���м�ֵ����Ϣ�������ܹ�ʹ�����ܹ����õ�����ͼ�ͷ�����
3)SMP������û����ȷ�ļ��Ͻṹ������£����ԺܺõĹ����������Ա������������⣬����Ϊģ����Ա�Ӳ�ȷ��������������Ⱥֵ��
4)���,ʵ���ںϳɺ���ʵͼ�����ݽ�����֤��Ϊ���ⶨ�ķ����ǣ�Ϊ���ϼ���������ĺ�ѡ�������е����ַ������Ƚϡ�
[1]��Щ���ݼ���������ַhttp://networkdata.ics.uci.edu/index.php���ҵ�
[2]��Щ��ʵ��ͼ�ζ�����֪�ļ��Ͻṹ,���,ȷ�Ժ�NMI���ڵ����������㣬�������ݲ�ͬ���㷨�õ���

5. ����
�ڱ�����,�����һ�����͵Ļ��������Լ��ϼ����㷨��ΪSMP��SMP���ҵ�����ÿ���ڵ������,���Ҽ�Ȩ����ÿ��С��ij�Ա������ʵ����ļ��ϼ��������,���ϱ�ǩ����Ϣ��ÿ������ ���ϵ��ڲ��ṹ��Ϣ������Ҫ�ġ��÷�����һ�����ص�������,ÿ������ͨ����ԭ�����,��������һ����һ�Ķ���������ϳ������ʵ����ʾ�ˣ��÷�������Ч�ԺͶ�ʵ�ʵ�������ԣ���һ��ָ�����ǵķ��������еķ�����ɵĸ��á�ʹ��ԭ��Ȩ�صĽ������,��Ⱥ����֧��SMP��ȷ����ȫ�IJ��������͵ļ��Ͻṹ���������˼��ϼ�������������,���ּ�Ⱥ����ϸ����Ϣ������ԭ��Ȩ�صİ����»�á�
��ʵ��Ӧ����,�ź������Բ�����ESC�������ڹ����е����ã����Ի���������ָ��������,��������뽫�˷���Ӧ����ָ������,�����Ժ����Ĵ�ʩ��ָ�������п��Բ��á����,���Ǵ����о����Բ�ͬ��ʩ��ָ������������δ���о��Ĺ����е�Ӧ�ý��бȽϡ����ͬʱ,���������Ի��и�������������Ӧ�ÿ��ǣ�������ԭ��Ȩ�ء�����Ż�ԭ��Ȩ�صķ�ʽ�����ܵ����ÿ��õ���Ϣ��Ҳ�����������ǵĽ�һ���о��С�
��л
���߸�л��������ˣ������ǵ�����,�������dz����������µ�������������õ��˹�����Ȼ��ѧ����(Nos.61135001,61403310)��֧�֡������о��ĵ�һ�����ڷ����õ����й���ѧ��ίԱ���֧�֡�
