使用HMM来研究一幅图像中人脸与非人脸之间的转换的。这种方法是以从图像中产生的观察序列和相应序列中的HMM参数为基础。该观察序列首先通过计算子图像的距离产生,并以此在第一种方法中估算12个人脸和非人脸类的中心。该研究完成后,最佳状态序列得到进一步的二进制分类处理。实验结果表明:HOS和HMM方法都具有比〔128〕,〔154〕更高的检验率,但是错误的较高也更多。
2.4.8理论信息法
人脸图案的空间性质通过不同的方面也可以被模拟。由于前后关系的约束,在它们(识别方法)之中,有一种有力的方法已经被用来实现肌理(皮肤)分割。通过少量邻近像素可以指定一幅人脸图案前后关系的约束。Markov的随机域理论提供了一条便利和相容的途径来模拟依赖于前后关系的实体,例如图像像素和相关的特征。通过使用条件MRF分类来刻画这些实体间的相互影响,从而得到(这些实体)。根据Hammers-ley-Clifford定理,一个MRF通过Gibbs分类能被同样地刻画,且这些参数经常是(MAP)估计〔119〕。做为选择(二者选一),使用直方图来估算人脸和非人脸的分类。使用Kullback的相关信息,Markov方法是最佳化基于信息的辨别,且该辨别位于两个类之间,该方法被实现和应用在检测〔89〕,〔24〕。
通过把一个表示人脸模板的概率函数p(x)和表示非人脸模板的概率函数q(x)〔89〕,Lew应用Kullback相关信息〔26〕来检验人脸,。一个人脸训练(测试)数据库是由包含100个个体的9个视图组成的,并用来估算人脸的分类。非人脸概率密度函数是通过使用直方图,从一个包含143000个非人脸模板的集合得到估算值的。许多提供信息的像素(MIP)是从这个训练(测试)集中选择出来的,因此最大化位于p(x)和q(x)之间的Kullback相关信息(也就是给出最大分类)。当它产生时,MIP分类集中在眼睛和嘴巴区域而避免鼻子区域。然后,用MIP来得到使用Fukunaga和Koontz〔47〕方法的分类和表示法的线性特征。为了检验人脸,输入图像从一个窗口上通过,计算被定义为〔114〕的来自人脸空间的距离(DFFS)。如果人脸子空间中的DFFS比非人脸子空间总的距离短,那么假设该人脸存在于该窗口中。
Kullback相关信息也被Colmenarez和Huang用来最佳化位于阳性和阴性人脸实例〔24〕间的基于信息的辨别。来自每个类(也就是人脸类和非人脸类)组成的训练(测试)集的图像被分析(理解)为一个随机方法的观察(向量),且用两个概率函数来刻画其特征。他们使用一组离散的Markov方法来模拟人脸和背景图案,同时估算模型的可能性。这种研究方法被转变为一个最佳化问题,即在两个类里,选择Markov的方法来最佳化基于信息的辨别。使用训练(测试)概率的模型来计算相似度,且该相似度被用来检验人脸。
Qian和Huang〔119〕提出了这样一种方法,该方法采用基于视角和模型的策略。首先,一种使用高级领域的知识的视觉注意算法,被用来减少寻找空间。通过选定图像的范围来实现,其目的是通过一种区域检验算法(分水岭方法, water-shed)产生基于区域的图。在选定的区域内,使用分等级的Markov随机域和最佳化(posteriori)估算的模板匹配和特征匹配方法的结合来检验人脸。
2.4.9诱导学
诱导算法也被用来定位和检验人脸。Huang et al.应用Quinlan的C4.5算法〔121〕来研究一棵来自于阳性和阴性的人脸图案实例〔64〕的判别树。每一个训练(测试)实例是一个8×8像素的窗口,且用一个具有30个属性的向量来表示,其中这些属性是由熵(平均信息量),平均数和标准背离的像素亮度值。从这些实例中,C4.5构造了一个分类器相当于一个判别树,该树的叶子表示类本身,而它的节点则详述了在某一单一属性中执行的测试。然后,使用这个被研究的判别树
来决定输入实例的人脸是否存在。这个实验显示:在FERET数据集里的一个由2340幅正面人脸图像的集合中,精确定位率是96%。
Duta和Jain〔38〕提出了一种使用Mitchell's Find-S算法〔101〕的方法来研究人脸的概念。类似于〔154〕,他们推测:人脸图案的分类p(x/face)能通过一个高斯类的集合被近似,来自于人脸实例到该类的一个质心的距离应该比来自于该类的点到其质心的一个最大距离的分数短。然后,应用Find-S算法来研究(thresholding)距离,象人脸和非人脸能被区分。这种方法有若干独特的特征。首先,它不能使用在阴性(非人脸)的实例中,而〔154〕,〔128〕能使用阳性和阴性实例。其次,仅一张人脸的中心部分被用来训练(测试)。再次,特征向量由包含32个亮度级和肌理(皮肤)的图像组成,而〔154〕使用全范围(级别)的亮度值做为输入。这种方法在一个CMU数据集中可以达到90%的检验率。
2.5讨论
以上这些人脸检测的方法分为四个主要类别,但有些方法能被分在多个分类中。例如,模板匹配方法经常用一张人脸模型和子模板来萃取脸部特征〔132〕,〔27〕,〔180〕,〔143〕,〔51〕,然后使用这些特征来定位和检验人脸。此外,基于知识的方法和一些模板匹配方法的分界线是模糊的,因为后者经常含蓄地应用人脸知识来定义人脸模板〔132〕,〔28〕,〔143〕。另一方面,人脸检测方法也能以不同的方式分类。例如,这些方法可以被分在是否依赖局部特征的方面〔87〕,〔140〕,〔124〕,或者被分在整个人脸图案(也就是全盘的)〔154〕,〔128〕。
3、讨论和总结
一个健壮的人脸识别系统在如下四种变化中都是有效的。这四种变化是:(1)光照条件;(2)方向、姿势和部分遮挡;(3)面部表情;(4)眼镜、面部毛发和多种发型的存在。
人脸识别是一个具有挑战性的有趣问题。尽管如此,它也能被看做是在解决计算机视频的重大挑战和对象类型识别方面的一些尝试。人脸的类别能容纳由于个体、(不坚硬)容软度、面部毛发、眼镜和化妆的差异而造成的大量的形状、颜色和反照率的多样性。图像的成像条件有不同的光照,三维姿势和混乱的背景。因此,人脸识别的研究在寻找一般目的和对象类型识别方面面临着大范围的挑战。然而,人脸的类型仍有其外观的规律性,这些规律性是通过许多探索和基于模型的识别方法而发现的,且这些规律性很容易在数据驱动法中学到。有一种期望是在的通常定义的分类中有规律性,但是这样的规律性是不显然的。最后,索然人脸内在类型的变化极大,但是人脸识别仍旧是一个两类性的识别问题(人脸和非人脸的对比)。
, 人脸检测方法综述
摘要:人脸识别技术具有广泛的应用前景,其目标是识别出所有包含了人脸中不注意的三维位置、方向和光照条件的图像区域。这个问题正受到挑战,因为人脸不是僵硬的,而且人脸的大小、形状、颜色和结构的变化程度很大。而无论从何种角度对人脸识别技术进行分类,要实现一个健壮的人脸识别系统,都需要解决检验人脸的这一步,因此,本文从四个大类从发,分别简单阐述了单一图像中的人脸检测方法。
关键字:人脸识别、人脸检测、特征
1、引言
人脸识别就是对于输入的人脸图像或者视频,首先判断其中是否存在人脸,如果存在人脸,则进一步的给出每个人脸的位置、大小和各个主要面部器官的位置信息,并依据这些信息,进一步提取每个人脸中所蕴含的身份特征,并将其与已知人脸库中的人脸进行对比,从而识别每个人脸的身份。人脸识别的过程可以分为以下三个部分:(1)人脸检测:判断输入图像中是否存在人脸,如果有,给出每个人脸的位置,大小;(2)面部特征定位:对找到的每个人脸,检测其主要器官的位置和形状等信息;(3)人脸比对:根据面部特征定位的结果,与库中人脸对比,判断该人脸的身份信息;显然地,在任何一个自动化的系统中,人脸检测都是解决上述问题的第一步。在本文中,我们把人脸识别和人脸定位区分开了,因为,后者是前者的一个简化了的问题。因此,本文的重点是放在放在人脸的检验方法上的。
在此,给出一个人脸检测的定义:给出一幅随意的图像,人脸检测的目的是明确图像中是否有人脸,如果有,返回每张人脸的范围和位置。与人脸检验有关的挑战可以归纳为如下这些因素:
1.姿势。图像中人脸的变化取决于相关的(摄取的)人脸姿势(正面、45度、侧面、向上、向下)以及一些面部的特征,例如眼睛或鼻子有可能是部分或全部闭塞(遮挡住了)。
2.结构部件的有无。象络腮胡子、(嘴唇上面的)胡子和眼镜这些面部特征可能有也可能没有,有些(人脸上的)部件包括形状、颜色和大小有大量的变化。
3.面部表情。一个人的面部表情直接影响着人脸的外观。
4.闭塞(遮挡)。人脸可能因为其他的对象而部分地被闭塞(遮挡)。在一幅有一群人的图像中,一些人的脸的一部分可能被其他人的脸挡住了。
5.图像定位。人脸的图像因为照相机的光学轴线的不同旋转而呈现出变化。
6.成像的条件。一幅图像的成像因素包括光照(光谱,来源的分布和强度)和照相机的特性(传感器的响应,镜头)对人脸外观的影响。
2、单一图像中的人脸检测
我们可以把单一图像中人脸的检测方法分为四类,而这些方法的分类界限而是可以重叠的。
1.基于知识(Knowledge-based)的方法。基于知识(Knowledge-based)的这些方法是把组成同一类人脸的信息进行编码。一般来说,这类标准捕捉的对象是脸部特征的相关之处。这些方法主要是为了人脸的定位设计的。
2.不变特征(Feature invariant)的方法。这类算法的目的是找出在姿势、角度或光照条件变化的情况下人脸上存在的那些结构特征,并以此来定位人脸。这类方法主要也是为了人脸的定位设计的。
3.模板匹配(Template matching)的方法。把一些标准的人脸模型存储起来,并以此用于描述人脸的全面或个别的脸部特征。通过输入图像和已经存储的模型之间相关性的计算来检测人脸。这类方法已经被用于人类的定位和检测了。
4.基于外观的(Appearance-based)方法。与模板匹配不同,这里的模板样式(或模板)是从一个训练(测试)图像集中获取的,而这个图像集捕捉到的是具有典型性且变化着的脸部外观。这些模板样式是为检测人脸服务的,所以这类方法主要也是为了人脸检测而设计的。
|
方法
|
代表文章
|
|
1. 基于知识
|
Multiresolution rule-based method
|
|
2. 不变特征
|
|
面部特征
|
Grouping of edges
|
|
肌理(皮肤)
|
Space Gray-Level Dependence matrix(SGLD) of face pattern
|
|
肤色
|
Mixture of Gaussian
|
|
多重特征
|
Integration of skin color,size and shape
|
|
3. 模板匹配
|
|
预先确定的人脸模板
|
Shape template
|
|
可变的(人脸)模型
|
Active Shape Model(ASM)
|
|
4. 基于外观的(识别)方式
|
|
特征人脸
|
Eigenvector decomposition and clustering
|
|
分布式
|
Gaussian distribution and multiplayer perceptron
|
|
神经系统网络
|
Ensemble of neural nerworks and arbitration schemes
|
|
支持矢量机技术
|
SVM with polynomial kernel
|
|
简单贝叶斯分类
|
Joint statistics of local appearance and position
|
|
隐马尔可夫模型
|
Higher order staticstics with HMM
|
|
信息理论法
|
Kullback relative information
|
表格1 单一图像的人脸识别方法分类
下面,展开讨论一下每一类方法的出发点和基本的实现方式。
2.1基于知识的,组织管理严密的人脸检测法
这类方法的发展标准是基于研究人员对人脸信息的研究,由此提出了描述人脸特征及其相关性的简单标准。例如,一幅图像中一张人脸上有一双位置对称的眼睛,一个鼻子和一张嘴巴。这些特征的关系可以通过它们的相对距离和位置来描述。这副输入图像中的脸部特征首先被萃取出来,而脸部其他候选区域的识别是基于这些特征的编码标准的。
这种检测方法的一个问题是:把人脸信息翻译成定义好的标准是一个难题。因为,如果这个标准已经被细化或是很精确的,那么被检测的人脸会因为不符合所有标准而无法被检测出来。但是,如果这个标准太粗略,被检测的人脸又会出现很多检测错误。此外,要进一步发展在不同姿势下检测人脸的方法也是困难的,因为要把所有可能的例子全部列举出来是很困难的。
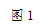

(图1.(a)n=1,原始图像;(b)n=4;(c)n=8;(d)n=16。原始的和相对低分辨率的图像。每平方单元由n×n个像素组成,这些像素的亮度被那个单元中的像素的平均亮度所代替)
(图2.一个典型的人脸在基于知识的组织管理严密的方法中的应用:标准的编码是由人脸信息中脸部区域的特征决定的(例如:(脸部)亮度的分布和区别)〔107〕。)

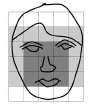 杨和黄使用一种分等级的信息(识别)方法来检测识别人脸〔170〕。他们的这个系统由三个级别的标准组成。最高级别中,所有可能出现的人脸信息是通过扫描位于输入图像上的窗口和应用一组标准,在其各自的位置上得到的。该标准的较高级别是对人脸的外表特征进行一般性的描述,而该标准的较低级别是对面部特征的细节的描述。通过平均(计算)和二次抽样可以生成一幅多层次的图像,在图1中给出一个实例。实例中的编码标准常用于在最低分辨率下对候选人脸(信息)的查找:“在人脸的中央部分(见图2阴影最深的部分)有四个单元的亮度是基本一致的”,“在人脸外围一圈的部分(间图2阴影较浅的部分)有一些亮度基本一致的单元”,“(显然)中央部分的平均灰度值和其上面一圈的平均灰度值的区别是很有意义的。” 这个分辨率最低(级别一)的图像的搜索是为那些候选人脸及其在更高分辨率的后续处理中服务的。在级别二中,局部直方图的同等化是在这些候选人脸从级别二中得到后进行的,且遵循边缘检测。(检测后)剩余的候选区域接着在级别三中被检测,其中级别三是另一个对诸如眼睛、嘴巴等脸部特征做出响应的标准集。求值是在一个包含60幅图像的测试集中进行的,这个系统定位的人脸在50幅测试图像中,而还有28幅图像则出现在发生错误警告时。这个方法吸引人的特点就是从粗糙到精确、从集中的引起注意的这个策略过去被常用于减少必要的角色。虽然这个方法不能达到一个高的识别率,但是这个用在多分辨率层次和用于导向研究的标准的思想在随后的人脸检测著作中已经被利用起来了〔81〕。
杨和黄使用一种分等级的信息(识别)方法来检测识别人脸〔170〕。他们的这个系统由三个级别的标准组成。最高级别中,所有可能出现的人脸信息是通过扫描位于输入图像上的窗口和应用一组标准,在其各自的位置上得到的。该标准的较高级别是对人脸的外表特征进行一般性的描述,而该标准的较低级别是对面部特征的细节的描述。通过平均(计算)和二次抽样可以生成一幅多层次的图像,在图1中给出一个实例。实例中的编码标准常用于在最低分辨率下对候选人脸(信息)的查找:“在人脸的中央部分(见图2阴影最深的部分)有四个单元的亮度是基本一致的”,“在人脸外围一圈的部分(间图2阴影较浅的部分)有一些亮度基本一致的单元”,“(显然)中央部分的平均灰度值和其上面一圈的平均灰度值的区别是很有意义的。” 这个分辨率最低(级别一)的图像的搜索是为那些候选人脸及其在更高分辨率的后续处理中服务的。在级别二中,局部直方图的同等化是在这些候选人脸从级别二中得到后进行的,且遵循边缘检测。(检测后)剩余的候选区域接着在级别三中被检测,其中级别三是另一个对诸如眼睛、嘴巴等脸部特征做出响应的标准集。求值是在一个包含60幅图像的测试集中进行的,这个系统定位的人脸在50幅测试图像中,而还有28幅图像则出现在发生错误警告时。这个方法吸引人的特点就是从粗糙到精确、从集中的引起注意的这个策略过去被常用于减少必要的角色。虽然这个方法不能达到一个高的识别率,但是这个用在多分辨率层次和用于导向研究的标准的思想在随后的人脸检测著作中已经被利用起来了〔81〕。
Kotropoulos和Pitas〔81〕提出了一种基于定位标准的方法,这种和〔71〕和〔170〕很相似。首先,使用投影来定位脸部特征的方法,被Kanade 成功地使用在定位一张人脸的分界线上〔71〕。设I(x,y)是一个m×n大小的图像中某一位置(x,y)上的一个亮度值,图像的水平和垂直预测被定义为HI(x)=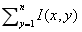 和VI(y)=
和VI(y)=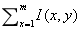 。首先得到这幅输入图像的水平轮廓,然后由在HI处检测到的突然变化来决定这个两个位置的最小值,也就是相当于头的左右两边。类似的,垂直预测的得到和定位的最小值是由嘴唇、鼻尖和眼睛的位置来决定的。这些被探测到的特征组成了一个面部的候选。图片3a给出这样一个例子:人脸的分界线相当于亮度突然发生改变的位置上的最小值。随后,眉毛/眼睛,鼻孔/鼻子和嘴巴的识别标准被用在那些有效的候选项中。这个被提议的方法已经被用在一组正面人脸集合的测试中,其中,这些人脸取自欧洲声控制与遥感系统的电视服务和安全应用的多模型数据库,这个数据库中包含了37个不同的人的视频序列。每幅图像依次包含了相同背景下的一个人脸。他们的识别方法提供了所有测试中正确的候选人脸。如果成功识别的定义象正确识别所有面部特征的定义那有,那么这个识别率有86.5%。图片3b给出了一个例子:在一个复杂的背景下用水平和垂直预测来定位一个人脸会变得困难。此外,这个方法在图解的图片3c这种多人脸的图像中不能容易地被识别出。本质上,如果窗口在预测方法操作之上被适宜地定位以避免易于误解的干扰,那么,这个方法是有效的。
。首先得到这幅输入图像的水平轮廓,然后由在HI处检测到的突然变化来决定这个两个位置的最小值,也就是相当于头的左右两边。类似的,垂直预测的得到和定位的最小值是由嘴唇、鼻尖和眼睛的位置来决定的。这些被探测到的特征组成了一个面部的候选。图片3a给出这样一个例子:人脸的分界线相当于亮度突然发生改变的位置上的最小值。随后,眉毛/眼睛,鼻孔/鼻子和嘴巴的识别标准被用在那些有效的候选项中。这个被提议的方法已经被用在一组正面人脸集合的测试中,其中,这些人脸取自欧洲声控制与遥感系统的电视服务和安全应用的多模型数据库,这个数据库中包含了37个不同的人的视频序列。每幅图像依次包含了相同背景下的一个人脸。他们的识别方法提供了所有测试中正确的候选人脸。如果成功识别的定义象正确识别所有面部特征的定义那有,那么这个识别率有86.5%。图片3b给出了一个例子:在一个复杂的背景下用水平和垂直预测来定位一个人脸会变得困难。此外,这个方法在图解的图片3c这种多人脸的图像中不能容易地被识别出。本质上,如果窗口在预测方法操作之上被适宜地定位以避免易于误解的干扰,那么,这个方法是有效的。


(图3.(a)和(b)n=8;(c)n=4。水平和垂直预测。通过查找水平和垂直预测的最高点的方法识别一幅单一图像是可行的。然后,同样的方法用在复杂背景的人脸识别和多人脸的识别中就有困难了,如图(b)、(c)。)
2.2自上而下的基于特征的人脸检测法
相对于基于知识的组织管理严密的方法,在这类检测方法中,研究者一直在设法找寻一些人脸检测中不变特征。许多已经被提出来的方法首先检测脸部特征,然后推断人脸的存在。脸部的特征例如眉毛、眼睛、鼻子、嘴巴和毛发大多使用边缘识别器来萃取。在萃取到这些特征的基础上,构建一个用于描述特征相关性和检验人脸存在性的统计模型。这些基于特征的算法存在的一个问题是:图像的特征可能会因为照明、噪音和被遮挡而变得相当模糊。当阴影引起大量强化且聚集在一起的边界从而导致有知觉(perceptional)的分组算法无效时,人脸的特征边界线也可能变弱。
2.2.1面部特征
Sironhey提出(develop)了一个定位方法用来在人脸检测中,从一个混乱的背景中分离出一张人脸〔145〕。它用一个精确的识别器〔15〕探索、移动和聚合边缘,从而把人脸轮廓线上的边缘线保留下来。然后在主要区域和背景的分界线上画一个椭圆。这种算法在一个包含48幅背景混乱的图像的数据库(的应用中)达到80%的准确率。不同于使用边缘线,Chetverikov和Lerch提出了使用点(blob)和条纹(即同一方向的直线性顺序边缘线)的一种简单人脸检测方法〔20〕。它们的人脸模型是分别表示眼睛和颊骨、鼻子的两个黑色的点(blob)和三个浅色的点(blob)所构成的。这里,人脸模型用条纹来表现人脸、眉毛和嘴唇这些要点。两个三角形被用来表示这些点(blob)间的空间关系。一幅低分辨率的拉普拉斯算子( 调和量算子)图像的产生是可以使得点(blob)检测变得容易些。其次,仔细察看这幅图像,找出明确存在的三角形作为候选项。如果条纹与一个候选项大致一样,那么一张人脸就被识别了。
Graf et al.提出(develop)了一种检测方法是用来定位灰度级图像中的脸部特征和人脸的〔54〕。经过波段过滤,用形态学上的操作(morphological operation)来增强包含一定外形(例如眼睛)的高亮度区域。被处理的图像的直方图具有代表性地展示了一个显著的最高峰。为了产生两幅二进制的图像,以这个最高峰的峰值和它的宽度,适当的极限值为基础进行选择。在两幅二进制图像中检测连接成分是为了确定候选脸部特征的范围。然后,这些范围的结合处用分类器来计算,从而确定是否有人脸,且人脸位于何处。他们的方法是用40个包含肩部以上部分的个体图像和各由100到200个连续帧组成的五个视频流文件来测试的。尽管如此,如何用形态学上的操作(morphological operation)来实行和如何用候选面部特征的结合来定位一张人脸都不是很清楚的。
Leung et al.提出(develop)了一个概率检测方法来定位基于局部特征识别器和随机曲线图匹配的混乱场景中的人脸定位。他们的出发点是阐明人脸定位问题是一个搜索问题,这个问题的目的是找出很可能是一个人脸模型的特定脸部特征的排列。五个特征(一双眼睛、两个鼻孔和鼻子/嘴唇的汇合点)被用来描述一个典型的人脸。因为任何一对类型相同的脸部特征(例如一对左眼和右眼),它们的相对距离是可以计算的,所以图像中的全体的距离都可以用高斯分布算法来模拟。一个脸部模板是通过响应一个基于大量人脸的数据集的多方位、多等级的高斯派生过滤器(面部特征内部的像素)的集合的平均计算来实现的。给出一个测试的图像,候选的脸部特征是通过过滤器对每个像素的响应和一个模板向量的响应(精神相关性类似)这两者的匹配来检测的。两个具有最强响应的最佳特征候选项被选出来用于其他脸部特征的研究。因为脸部特征不可能出现在任意的排列中,所以预料中其他特征的定位是用一个共用距离的统计模型来估算的。此外,协方差的估计也是可以计算的。因而,预料中的特征定位的估算具有较高的可能性(概率)。然后,Constellation(星座)只能从位于适当位置内部的候选项中形成,且最相似的一张人脸被识别。寻找最佳Constellation(星座)的过程阐明了象随机曲线图匹配这样的问题,其中,这个随机曲线图问题就是在相当于描述人脸特征的曲线图的节点和弧的不同特征间的距离。Constellation(星座)的排列是基于一个概率密度函数,这个函数是一个相当于人脸的Constellation(星座)与它通过二选一的机制(例如:非人脸)产生的结果的可能性相比。他们使用一个有150幅图像的集合来进行实验,实验条件是:如果任何一个Constellation(星座)正确定位三个或三个以上的这个人脸的特征,那么这个人脸就被认为是被正确地检测出来了。这个系统能达到的正确定位率是86%。
不同于使用共有的距离来表示脸部特征间的相互关系,Leung et al.〔13〕、〔88〕也提出了一种二选一的方法来建模人脸。这些Constellation(星座)的表示和排列是通过使用Kendall〔75〕、Mardia和Dryden〔95〕发展的形状统计论来实现的。这个形状统计学是一个基于N个特征点的概率密度共有函数,用(xi,yi)来表示,且第i个特征是在这样的假设下的:根据一个普通2N空间的高斯分布来定位平面上的这些原始特征点。他们应用最大相似度的方法来确定一张人脸的位置。这些方法的一个优点是被部分遮挡的人脸也能被定位。尽管如此,这些方法是否适合多人脸有效识别的情况是不清楚的。
在〔177〕、〔178〕中,Yow和Cipolla提出了一种基于特征的检测方法,这种方法使用的大量根据来自于可见图像和它们之间前后关系。第一步是应用一个二次派生高斯过滤器,把一幅未处理过的图像拉长(到原来的三到一倍)。重要的(特征)点在最大定位值的检测是用这个过滤器的,它的响应反映了脸部特征可能的位置。第二步是检查这些重要(特征)点的边缘线并把它们分到各自的区域里面。这些有知觉的(perceptional)边缘线分组是基于它们在方向和色差(浓度)上的相似度和接近性。一个区域里特征的衡量,例如边缘线的长度,边缘线的浓度和亮度的变化,在计算并存储在一个特征向量里的。一个平均协方差矩阵中每一个脸部特征向量是根据脸部特征的训练数据来计算的。一幅图像中的区域变成一个有效的脸部特征候选项的条件是Mahalanob的距离在(候选项)相应的特征向量的极限值以下。被标识的这些特征是根据模型对它们(特征)各自间应有的关系的了解来被进一步分组。然后,用贝叶斯定理的网络来估算每一个脸部特征及其分组。这种方法吸引人的一个优点是能够识别不同方位和姿态上的人脸。用110幅不同比例、方位和视角的人脸图像所组成的一个测试集来测试,得到85%的全面识别率。尽管如此,被报告的误识率达到28%,而且执行效率仅对像素大于60×60的人脸(图像)有效。随后,这种方法(的效果)通过有效的轮廓模型〔22〕,〔179〕得到增强。图片4概述了基于人脸识别的这个方法的特点。


(图像4(a)Yow和Cipolla模拟的人脸是一个包含了六方面脸部特征(眉毛、眼睛、鼻子和嘴巴)的一个平面〔179〕。(b)每个脸部特征是用一对导向性的边缘线来模拟的。(c)特征选择的处理开始于那些重要的(特征)点,并遵循边缘线的识别和连接,且通过一个统计模型来测试(根据K.C. Yow和R.Cipolla)。)
Takacs和Wechsler描述了一种生物学上的(有根据的)人脸定位方法,该方法是基于一个视网膜特征萃取和眼睛微摆模型〔157〕。他们的算法是在一幅显著的图像或重要的区域上进行的,并使用马格诺合金颗粒来制作能模拟人类视觉系统的活动细胞的一个视网膜格子。第一个阶段计算一幅粗糙扫描的图像从而估计这个人脸的位置,这个操作是基于过滤器对能接受区域的响应。每个能接受的区域由大量的神经细胞组成,这些细胞被高斯过滤器明确定位了。第二步在较高分辨率的情况下仔细扫描图像来制作显著的地图以定位人脸。(这种方法)在一个由426幅图像(有200个对象来自FERET数据库)组成的测试集中的错误率是4.69%。
Han et al.提出了一种基于生态学的技术来萃取人脸检测中被他们认为是类似眼睛(eye-analogue)的部分〔58〕。他们认为眼睛和眉毛是人脸中最显而易见且最稳定的特征,所以,有利于识别。他们把类似眼睛的部分的边缘线定义在和眼睛一样的等高线上。首先,象(clipped difference)停止和开始这样的形态学上的操作被用来萃取亮度值变化显著的那些像素。在他们的方法中,这些像素变成了类似眼睛(部分)的像素。然后,对产生类似眼睛的部分进行标识的处理。这些部分常用来指导包含眼睛、鼻子、眉毛和嘴巴这些几何连接的可能是人脸的这些区域的研究。这些候选的人脸区域用类似于〔127〕这样的一个神经系统网络来做进一步的检验。他们用由包含130张人脸的122图像组成的测验集来进行实验,实验证明这种方法有94%的正确率。
最近,Amit et al.提出了一种用于形状检测的方法,并且用这种方法识别了静态亮度图像中的前景人脸〔3〕。这种识别分为两个阶段:调焦和透彻分类。调焦的基础是空间排列的边缘片段,这些片段是从一个利用亮度差异的简单边缘识别器来萃取出来的。定义这样一个丰富的结构(族谱):包含空间排列,基于光度测定和几何的转换范围的不变式(不变量)。使用〔4〕提出(develop)的归纳法从包含300幅训练人脸图像的集合中选择图像,尤其是那些人脸的空间排列边缘比背景的空间排列边缘多的图像。同时,使用CART算法〔11〕来发展一棵分类树,且这棵树来自于训练图像和一堆从一般背景图像中识别出来的假阳性图像。给出一个测试图像,从空间排列的边缘片段中识别出有意义的区域。然后,使用CART树把每个有意义的区域分成人脸或背景。他们的实验是在一个包含来自Olivetti(现在是AT&T)的100幅图像所组成的集合中进行的,结果报告每100个像素中有0.2%的假阳性率和10%的假阴性。
2.2.2(皮肤)肌理
人脸所具有的独特的(皮肤)肌理可以用来把不同的人脸区分开来。Augusteijn和Skufca提出(develop)了一种通过类似人脸(皮肤)肌理的识别来推断一张人脸的存在性〔6〕。为了从(皮肤)肌理标志中推断一张人脸的存在性,他们提出以毛发和皮肤的肌理出现率为(推断)依据。但是,据了解:最适合(皮肤)肌理分类的不是人脸的定位和检测。
Dai和Nakano应用二次统计特征(SGLD)模型来进行人脸识别〔32〕。脸色信息也是混合于人脸(皮肤)肌理模型中的。使用这个人脸(皮肤)肌理模型,他们设计的一个扫描方案,这个方案是用来在包含放大人脸区域的类似橙色部分的彩色背景下检测人脸的。这种方法的一个优点是这样可以识别出非垂直的人脸或者识别出具有诸如胡须和眼镜这类特征的人脸。这种被报道的方法在一个包含60张人脸的30幅图像组成的测试集中的检测率是相对理想的。
2.2.3肤色
人的肤色作为一种有效的特征已经在人脸识别和人手跟踪等许多应用中得到使用和证明。虽然不同的人有不同的肤色,但有研究表明肤色的亮度和它们的色度(参考色)〔54〕,〔55〕,〔172〕之间的差异是主要原因。
许多被提出来的方法是构建一个肤色模型用的。最简单的模型是定义一个皮肤色调的像素区域,用Cr,Cb标识值〔17〕,例如R(Cr,Cb)是从肤色模型像素的实例中取值的。使用仔细选定的(作用)域〔Cr1,Cr2〕和〔Cb1,Cb2〕,如果一个像素(Cr,Cb)的值降低到这个范围域内,例如,Cr1<=Cr<=Cr2且Cb1<=Cb<=Cb2,那么这个像素被分类到皮肤色调中去。
Crowley和Coutaz使用一种在规格化RGB色彩空间中的直方图h(r,g)的(r,g)值得到一个由特殊RGB向量给出的该像素遵循的皮肤〔29〕,〔30〕的获得概率。换句话说,如果h(r,g)>=τ,且τ是从直方图的实例中根据经验选定的一个域值,那么这个像素被分到相应的肤色中。
Saxe和Foulds提出一种迭代的皮肤识别方法,这种方法使用HSV色彩空间〔138〕的直方图交集。肤色像素中的一个初始化的点(blob),被称为控制点(种子),这些点是由用户选择的,且常被用于迭代算法的初始化。为了识别肤色的区域,他们的方法是通过这幅图像中,某一时刻的点移动,且把来自该图像的控制的直方图和当前的直方图的比较关系呈现出来。直方图交集〔155〕被用于对控制的直方图和当前的直方图进行比较。如果匹配值或公共的实例数目(例如交集)比一个域值大,那么当前点被当做肤色来分类。
Kjeldsen和Kender定义一个在HSV色彩空间中用来从背景中区分出皮肤区域的色彩术语〔79〕。相对于上面涉及到的非参数方法,高斯密度函数〔14〕,〔77〕,〔173〕和混合高斯〔66〕,〔67〕,〔174〕常被用于模拟肤色。常常使用可能性大的值来估算单峰高斯分布中的这些参数〔14〕,〔77〕,〔173〕。宁可使用一种混合高斯而不使用一种多模型分布的出发点是基于这样一份(观察)报告,报告表明不同种族背景的有色人种不能构造一种多模型的分布的色彩直方图。使用一种EM算法〔66〕,〔174〕来估算一种混合高斯中的这些参数。
最近,Jones和Rehg在将(从规格化RGB色彩空间中)搜集来的近十亿个被标识的皮肤色调像素中进行一项大比例(级别)的实验。比较直方图的性能和混合模型对皮肤的识别,他们发现直方图模型在正确度和计算代价上更有优势。如果肤色模型能够完全适应于不同光照条件的需要,那么脸色信息是用于识别脸部区域和特殊脸部特征的有效工具。然而,这样的肤色模型在光源变化显著的光谱中是无效的。换句话说,由于背景和前景光照的变化,肤色表现出来的状态经常是不稳定的。虽然通过使用物理学模型〔45〕能明确地表达色彩(恒久不变的)状态(或性质),但是在光照条件变化的情况下使用肤色(识别)还是存在有些问题的。
McKenna et al.提出一个适应性色彩混合模型,用来在光照条件变化的情况下跟踪人脸〔99〕。相对于依赖一个基于色彩(恒久不变的)状态(或状态)的肤色模型,他们使用随机模型来估算一个对象的在线脸色分布,且这个模型能适应观察和光照条件的调和变化。初步结论显示他们的系统能够在一个大范围的光照条件下跟踪人脸。然而,这种方法不能应用在单一人脸图像的人脸识别。
2.2.4多重特征
最近,许多结合了一些脸部特征的检测方法已经被提出来用于定位或检测人脸。它们中的许多方法都利用了例如肤色、大小和形状等前面的特征来查找人脸的候选项,然后使用诸如眉毛、鼻子和毛发等局部的详细的特征来检验这些候选项。在2.2.3部分已经描述了一种基于类皮肤区域识别的典型方法。接下来,用相关成分分析或聚类算法来把类皮肤像素分在一起。如果一个相关区域的形状是椭圆或卵形的,那么它就会变成一个人脸候选项。最后,检验局部特征。其中特征集的定义是可以不同的。
Yachida et al.提出了一种利用模糊理论〔19〕,〔169〕,〔168〕在彩色图像中识别人脸的方法。他们使用两个模糊模型来描述CIE XYZ色彩空间中肤色和毛发的分布。五个主要模型(一个正面、四个侧面的角度)是对图像中人脸外貌的抽象。每个形状模型都是一个二维的图案,图案由m×n个正方形格子组成,每个格子包含了若干个像素。每个格子被赋予了两种性质:皮肤比例和毛发比例,且这两种性质意味着这个格子里面到格子周边的皮肤区域(或毛发区域)的比例。在一幅测试图像中,每一个像素被分类为基于分类模型的毛发,人脸,毛发/人脸和毛发/背景,从而产生了类皮肤和类毛发的区域。然后,把这个主要(形状的)模型与从测试图像中萃取来的类皮肤和类毛发区域进行比较。如果它们是相似的,那么被识别区域就变成了一个人脸候选项。为了进行确认,使用水平边缘线来萃取一个人脸候选项的眼睛-眉毛和鼻子-嘴巴的特征。
Sobottka和Pitas提出了使用形状和脸色〔147〕作为脸部特征萃取物的人脸定位方法。首先,HSV空间中的色彩分割被用于定位类皮肤区域。然后,在低分辨率的区域中测定相关的部分。利用几何力矩为每一个相关的部分计算出最适合它们的椭圆。每个用非常近似的椭圆形选定的相关部分作为一个人脸候选项。随后,通过查找脸部特征内在的相关性部分来检验这些候选项。诸如眼睛和嘴巴这些特征,因为它们比人脸的其他部分的颜色要深,所以能从中萃取出来。在〔159〕,〔160〕中,一个高斯肤色模型被用来对肤色像素进行分类。为了在二进制图像中表现成群的形状,利用傅立叶(Fourier)和光线Mellin变换来计算由11个最低次几何力矩组成的集合。为了检测,利用萃取的几何力矩训练(测试)一个神经网络系统。他们的实验表明:在一个有100幅图像的测试集合中识别率是85%。
这种对称人脸模型也已经被应用在人脸检测中了〔131〕。利用YES色彩空间分类条件的密度函数来实现皮肤/非皮肤的分类,且这个色彩空间是遵循把(分类)产生的邻近区域变平滑的(原则)。接下来,一个椭圆人脸模板被用来测定基于Hausdorff距离的肤色区域的类似处。最后,使用若干代价(成本)的函数来定位眼睛的中心,而这些函数的设计是利用人脸和眼睛的位置具有内在的对称性。然后,利用眼睛中心点间的距离来定位鼻尖和嘴巴的中心。这种方法的一个缺点它仅对单一正面视角的人脸有效,而且人脸的一双眼睛必须都是可见的。在〔151〕中给出了一种利用脸色和局部对称的类似方法。
相对于基于像素的方法,在〔173〕中介绍了基于结构、颜色和几何学的识别方法。首先,使用多(比例)等级分割来萃取一幅图像中的相似区域。使用高斯肤色模型,萃取皮肤色调区域并用椭圆将之分组。如果诸如眼睛和嘴巴这样的脸部特征存在于这些椭圆区域内,那么一张人脸就被识别了。实验结果表明:当存在诸如胡须和眼睛这类不同的脸部特征的情况下,这种方法能识别人脸。
Kauth et al.提出利用描点法(blob representation)来萃取一个紧凑的,结构上有意义的多谱段卫星肖像(multispectral satellite imagery)〔74〕的描述。通过连接这幅像素图像的同等物--像素光谱(或构造上)的成分来形成每个像素中的一个特征向量;然后,用这个特征向量丛生像素,从而形成连贯的相关区域或“点(blob)”。为了识别人脸,每个特征向量由这个图像的同等物和规格化的色度(参考色)组成。例如:X=(x,y, r/(r+g+b),g/(r+g+b))〔149〕,〔105〕。然后用一个连同性的算法产生点(blob),这个做为结果的皮肤(斑)点的大小和形状与被考虑为人脸的规范化人脸的皮肤点(blob)是很接近的。
Kim et al.〔77〕的人脸识别利用了范围和颜色(脸色)。在背景像素具有相同的深度,且它们的数目超过了前景对象,这样的假设下,计算不同的图和从背景中分割对象用不同的直方图。在规格化的RGB色彩可见中使用高斯分布,被分割的类皮肤区域被分类为人脸。在Darrell et al.的人脸识别和跟踪〔33〕中提出了这样一个类似的方法。
2.3模板匹配
在模板匹配中,一个标准人脸模型(大多是正面的)是通过函数手工确定或参数化的。给出一幅输入图像,分别为人脸的轮廓,眼睛,鼻子和嘴巴计算这个标准模型的相关值。一张人脸的存在与否是由这些相关值决定的。这种方法的优点是实现起来简单。然而,这种方法被证明不适合用于人脸识别,因为它不能有效的处理比例,姿态和形状变换的情况。随后,多分辨率,多(比例)等级,子模板和可变形的模板就被提出来了,以此来满足比例和大小可变的情况。
2.3.1预定性模板
在Sakai et al.[132]中提到过在照片中识别正面人脸的一种早期尝试。他们使用若干眼睛,鼻子,嘴巴和人脸轮廓的子模板来模拟人脸。每一个子模板用一个线段的术语定义。基于最大倾斜度的变化,从输入图像中萃取线段,然后把(线段)与子模板进行匹配。首先计算子图像和轮廓模板的相关性,因此识别已定位的那些人脸候选项。然后在候选项的位置处对其他的子模板进行匹配。换句话说,第一阶段测定引人注目的焦点和重要区域,第二阶段测试细节,以此来测定人脸的存在与否。这种以引人注目的焦点和子模板为(主)的思想在后来的有关人脸识别的著作中被采纳。
Craw et al.提出的定位方法是以正面视角的人脸形状模板(例如,人脸的轮廓形状)〔27〕为基础的。首先,用Sobel过滤器萃取边缘线。这些边缘线被一起分组,用来查找有若干约束的人脸模板。当主要的轮廓被定位以后,在不同的(比例)等级下,用相同处理方法来定位诸如眼睛,眉毛和嘴唇这些特征。随后,Craw et al.用由40个模板组成的集合来形容一种定位方法查找脸部特征和用一种管理策略来指导和平均基于该模板的特征识别器〔28〕的效果。
Govindaraju et al.提出一种两步人脸识别法,该方法产生于人脸臆测且在〔52〕,〔52〕,〔51〕中测试。构造一个人脸模型的根据是由边缘线定义的特征。这些特征描述了一个正面人脸的左侧,毛发线和右侧的弯曲度。Marr-Hildreth边缘区分器被用来获得一幅输入图像的边缘图。然后,用过滤器过滤人脸中不象轮廓线的部分。一对轮廓片段连接的基础是它们相近且位置相关。角落的识别是为了分割特征曲线的轮廓线。然后,这些特征曲线通过检查它们的几何性质和相邻间的相对位置得到标识。如果一对特征曲线的属性相容(一致)(例如:如果一对特征曲线出现在同一张人脸上),那么通过边缘线把它们连接起来。一对特征曲线形成边缘线的比率与全部比率相比较,代价被赋值给边缘线。如果以三段特征曲线(具有不同的标识)组成的一个分组的代价很低,那么这个分组就变成了一个假设。当在报纸的文章里识别人脸时,图像中人的个数这一间接信息是从输入图像的附加说明中得到的,并以此选定为最佳的假设〔52〕。他们的系统表明:在一个拥有50张照片的测试集里,识别率近似为70%。然而,被识别的人脸必须是垂直,正面,且没有被遮挡的。通过Venkatraman和Govindaraju〔165〕,相同的方法在微波范围内萃取边缘线方面得到进一步发展。
Tsukamoto et al.提出一种为人脸图案(QMF)〔161〕,〔162〕定性的模型。在QMF中,每一幅做例子的图像被分成一定数量的块,为每一块估算定性的特征。为了用参数表示一个人脸图案,在这个模型中“灵活(轻盈)”和“锋利(edgeness)”被定义为特征。因此,这个块模板被用来计算一幅输入图像中每个位置上的“人脸(faceness)”。如果人脸(faceness)量在前面已经定义的范围之内,那么人脸就被识别出来了。
侧面影象(轮廓)也被当做模板为人脸定位〔134〕服务。在人脸实例中,用主要成分分析(PCA)得到基本的人脸侧面影象(轮廓)的一个集合,且人脸的实例是通过一个比特数组表现出来的侧面影象。然后,这些特征侧面影象用在一个用于定位的无显著特点的关节转换上。在〔150〕中提出了一种基于多模板脸部成分定位方法。他们的方法为可能出现的脸部特征定义了大量的假设。然后,根据利用Dempster-Shafer理论〔34〕得到的面部成分的假设,定义一个人脸存在性的假设集合。给出一幅图像,特征识别器为脸部特征的存在计算确定因素。这些确定因素结合起来以测定人脸存在的可信度和不可信度。他们的系统能定位94幅图像中的88幅图像的人脸。

 (图片5是Sinha方法中为人脸定位的一个14×16像素率的模板。这个模板由16个区域(灰色格子)和23种关系(用箭头表示)组成〔139〕。Sinha使用一个空间图像不变量的小集合来描述人脸模型空间〔143〕,〔144〕。设计这个不变量的关键(insight)是,当侧面影象改变个体的中人脸不同部分(例如眼睛,脸颊,前额)的光照时,这些部分的相对光照仍然是基本不变的。测定一些光照区域的成对率,保持这些比率的“趋势”(例如,某个区域比另一个区域明亮或暗淡)需要健壮的不变量。因而,观察光照的规律性被编码为一个比率模板,该模板是一个人脸的粗糙的空间模板,其中,人脸中包含了一些适当的选定子区域,这些区域中粗略地包含了主要的面部特征,例如眼睛,脸颊和前额。这里光照的约束在于用子区域间的一个明亮-暗淡成对关系的适当集合来捕捉人脸的部分。如果一幅图像满足所有明亮-暗淡成对的约束,那么这个人脸就被定位了。随后,在局部邻近区域使用亮度差的思想被进一步发展,以此为基于微波的步行者、汽车和人脸识别〔109〕服务。Sinha的方法已经被拓展和应用到一个能动遥控视觉系统〔139〕,〔10〕的人脸识别中。图片5给出了包含23中已定义了的关系的增强形模板。这些被定义的关系被进一步分类为11种本质的关系(实箭头)和12种确定的关系(虚箭头)。图片中每一个箭头表示一种关系,箭头的头指向第二个区域(例如:分母的比率)。如果这个比率在两个超越某一作用域的区域间,那么这种关系就满足人脸模板;如果一定数量的本质且确定的关系超越某一作用域,那么人脸即别识别。
(图片5是Sinha方法中为人脸定位的一个14×16像素率的模板。这个模板由16个区域(灰色格子)和23种关系(用箭头表示)组成〔139〕。Sinha使用一个空间图像不变量的小集合来描述人脸模型空间〔143〕,〔144〕。设计这个不变量的关键(insight)是,当侧面影象改变个体的中人脸不同部分(例如眼睛,脸颊,前额)的光照时,这些部分的相对光照仍然是基本不变的。测定一些光照区域的成对率,保持这些比率的“趋势”(例如,某个区域比另一个区域明亮或暗淡)需要健壮的不变量。因而,观察光照的规律性被编码为一个比率模板,该模板是一个人脸的粗糙的空间模板,其中,人脸中包含了一些适当的选定子区域,这些区域中粗略地包含了主要的面部特征,例如眼睛,脸颊和前额。这里光照的约束在于用子区域间的一个明亮-暗淡成对关系的适当集合来捕捉人脸的部分。如果一幅图像满足所有明亮-暗淡成对的约束,那么这个人脸就被定位了。随后,在局部邻近区域使用亮度差的思想被进一步发展,以此为基于微波的步行者、汽车和人脸识别〔109〕服务。Sinha的方法已经被拓展和应用到一个能动遥控视觉系统〔139〕,〔10〕的人脸识别中。图片5给出了包含23中已定义了的关系的增强形模板。这些被定义的关系被进一步分类为11种本质的关系(实箭头)和12种确定的关系(虚箭头)。图片中每一个箭头表示一种关系,箭头的头指向第二个区域(例如:分母的比率)。如果这个比率在两个超越某一作用域的区域间,那么这种关系就满足人脸模板;如果一定数量的本质且确定的关系超越某一作用域,那么人脸即别识别。
在Mial et al.[100]中提出了一种用于人脸识别的分等级模板匹配方法。第一步,把一幅输入的图像以每步旋转5°的进度从-20°转到20°,因此来处理旋转的人脸。一幅多分辨率的图像的层次的构成(见图片1)和边缘线的萃取是用拉普拉斯算子操作。通过六个脸部组件:一对眉毛,一对眼睛,一个鼻子和一张嘴巴,构成这样人脸模板。最后,应用探索来测定人脸的存在性。他们的实验结果表明:包含单一人脸(正面的或旋转的)的图像比包含多个人脸的图像更容易识别。
2.3.2可变模板
Yuille et al.使用可变模板来模拟脸部特征,从而适用于脸部特征(例如眼睛)中在前的(priori)弹性模型。在这种方法中,脸部特征是用参数化的模板来表示的。 定义这样一个能量(energy)函数:在一幅输入图像中把边缘,顶峰和谷底和模板中相应的参数联系起来。通过最小化能量(energy)函数的参数找到了一个最适合的弹性模型。虽然他们的实验结果证明(该方法)在非刚形的特征跟踪中有很好的性能,但是这种方法的一个缺点是可变模板必须用在主要对象很接近的情况下。在〔84〕中,一种基于蛇形汇率波动(snakes)〔73〕,〔79〕的检测方法及其模板得到了发展。首先,用模糊过滤器把一幅图像缠绕起来,然后用形态学的操作增强其边缘。一个改进的n像素(n很小)的波动被用来查找和消除小的曲线分割。每一张人脸用近似椭圆表示,残留小波动的关节转换被用来确定一个显性的椭圆。这样,就得到了由四个参数表示这个椭圆的集合,并把这个图样做为人脸定位的候选项。对于每一个候选项,用类似于可变模板〔180〕的方法寻找详细的特征。如果找到固定数量的脸部特征,且它们的比例满足人脸模板的测试比例,那么这个人脸被识别。Lam和Yan也使用波动及最小化能量(energy)函数中的贪婪算法来定位主要的边界线。
Lanitis et al.用形状和亮度信息〔86〕来描述一种表现人脸的方法。他们的从训练图像的集合开始着手,其中这些图像中的实例,诸如眼睛的边界,鼻子,下巴/脸颊,是手工标识的,且实例点的每个向量被用来表示一个形状。他们用一个点分布模型(PDM)来表现基于全部个体的形状向量的特征,与Kirby和Sirovich的方法类似,这种方法用来表现规范化形状的亮度外观。一个脸形点分布模型(PMD)通过使用活动形状模型搜寻来估计人脸定位和形状参数,可以用来定位新图像中的人脸。然后,人脸碎片转换为均匀的形状和被萃取的亮度参数。这个形状和这些亮度参数可以一起被用于分类。Cootes和Taylor应用类似的方法定位一幅图像〔25〕中的人脸。首先,他们定义包含主要特征的实例的图像的矩形区域。然后,应用要素分析来匹配这些训练特征和得到一个分布函数。如果概率量超过一个作用域的范围,且用活动形状模(ASM)检验,那么特征候选项被测定。使用40幅图像来测试这个方法,该方法能够在40幅测试图像中定位35张人脸。用Kalman过滤器使这个活动形状模型(ASM)方法得到进一步拓展,并以此估计无形状的亮度参数和跟踪顺序图像中的人脸〔39〕。
2.4基于外貌的(人脸识别)方法
相对于模板被专家预先定义的模板匹配方法,基于外貌的“模板”(检测)方法是从图像实例中研究出来的。一般来说,基于外貌的(人脸识别)方法依赖于统计分析和机械学习的技术,从而找出人脸和非人脸图像的有关特性。这种学术上的特性是以分布式模型或用于人脸识别的判别式函数的形式(呈现的)。同时,因为计算效率和势必效率的缘故,要经常(执行)减少维度。
许多基于外貌的(人脸检测)方法能够在一个概率框架中被理解。一幅图像或来源于图像的特征向量被看做是一个随机变换量x,且这个随机变换量是对通过分类条件密度函数p(x/face)和p(x/nonface)计算的人脸和非人脸特性的表示。贝叶斯分类或最大相似度可以用来对人脸和非人脸的候选图像定位进行分类。不幸的是,由于x的高维度,贝叶斯分类的简单执行是不可行的,因为p(x/face)和p(x/nonface)是多模型的,而且如果给p(x/face)和p(x/nonface)赋一些简单的参数,那么它(这种方法)就不能理解了。因此,许多介绍基于外貌(的人脸识别)方法的文章中涉及的有关p(x/face)和p(x/nonface)的参数和非参数都是以经验为主的近似值。
基于外貌的(人脸识别)方法的另一种实现是找出在人脸和非人脸类间的一个判别函数(例如,坚定的外表,分开的超平面,极限函数)。按照管理,图像模型设计的目的是为低空间服务的,然后为分类〔163〕形成一个判别函数(一般是基于距离的韵律学),或者用多层神经系统网络〔128〕也可以形成一个非线性的坚定外表。最近,支持向量的机器和其他核心的方法已经被提出了。为了一个较高的空间,这些方法含蓄地设计模型,然后,形成一个在被设计的人脸和分人脸模型〔107〕间的坚定外表。
2.4.1特征脸
早期使用特征脸的一个实例出现在Kohonen〔80〕写的人脸识别中,其中的一个简单神经系统网络被用来示范进行排列和规格化的人脸图像中的人脸识别。这个神经系统网络通过图像自相关矩阵的特征向量的近似值来计算一个人脸的描述。这些特征向量随后被确认为特征脸。
(图片6:Sung和Poggio〔154〕使用人脸和非人脸群。他们的方法是使用一个高斯集合来估算人脸和非人脸模型的密度函数。这些高斯的中心点显示在图右(感谢K.-K.Sung和T.Poggio)。)

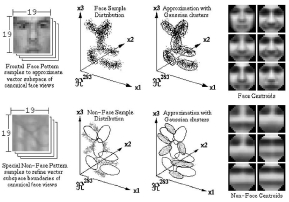 Turk和Pentland应用主要成分分析来识别和检测人脸〔163〕。类似于〔78〕,主要成分分析是在一个人脸图像的训练集中进行的,且产生了横跨图像空间的一个子空间(称之为人脸空间)的特征图(这里称之为特征脸)。人脸图像的是在这个子空间中设计(生成)的,(然后)成类。同样的,非人脸训练图像也在相同的子空间里设计(生成),(然后)成类。人脸图像在人脸空间中设计(生成)时没有什么本质上的变化,但是非人脸的设计(生成)则很不一样。为了探测一个场景中人脸的存在性,要计算图像中所有位置中图像区域和人脸空间之间的距离。来自人脸空间的距离被用来当做一个“人脸(faceness)”的度量值,计算人脸空间的距离的结果被当做一幅“人脸地图”。然后,一张人脸就能从这幅人脸地图的局部最小值处探测(识别)出来了。许多有关人脸探测、识别和特征萃取的文章中都采纳了特征向量分解和聚类的思想。
Turk和Pentland应用主要成分分析来识别和检测人脸〔163〕。类似于〔78〕,主要成分分析是在一个人脸图像的训练集中进行的,且产生了横跨图像空间的一个子空间(称之为人脸空间)的特征图(这里称之为特征脸)。人脸图像的是在这个子空间中设计(生成)的,(然后)成类。同样的,非人脸训练图像也在相同的子空间里设计(生成),(然后)成类。人脸图像在人脸空间中设计(生成)时没有什么本质上的变化,但是非人脸的设计(生成)则很不一样。为了探测一个场景中人脸的存在性,要计算图像中所有位置中图像区域和人脸空间之间的距离。来自人脸空间的距离被用来当做一个“人脸(faceness)”的度量值,计算人脸空间的距离的结果被当做一幅“人脸地图”。然后,一张人脸就能从这幅人脸地图的局部最小值处探测(识别)出来了。许多有关人脸探测、识别和特征萃取的文章中都采纳了特征向量分解和聚类的思想。
2.4.2分类(人脸检测)方法
Sung和Poggio提出(发展or研究)了一种分类系统来检测(识别)人脸〔152〕,〔154〕,该系统示范了:从一个对象类中得到的图像模型分类如何从这个类的阳性或阴性实例(例如图像)中区分出来。他们的系统由两部分组成,人脸和非人脸图案的分类模型,以及一个多层感知分类器。 首先,把每一个人脸和非人脸的实例规格化,处理成一幅19×19像素的图像,再加工成一个361维度的向量或图案。接下来,用一个改良的k步(k-mean)算法把这些图案分成六个人脸和六个非人脸的群(类),详见图片6。每一个群(类)用一个多空间高斯函数来表示为一幅平均图像和一个协方差矩阵。 图片7展示了他们这个方法的距离度量。在一幅输入图像的图案和原型群(类)间计算两段距离(distance metrics)。第一段距离的构成是位于这个测试图案和这个群(类)质心间的规格化的Mahalanobis距离,它的度量是通过一个横跨该群(类)75个最大特征向量的低维度的子空间实现的。第二段距离的构成是位于这个测试图案和它在75维度子空间的投影之间欧几里得(Euclidean)距离。这段距离的构成说明通过第一段距离的构成不能捕捉图案的差异。最后一步是使用一个多层感知网络(MLP),及每一个人脸和非人脸群(类)的12对距离,从非人脸图案中把人脸窗口图案区分出来。这个分类器是使用来自于47316个窗口图案的标准背传播来训练的。这里有4150个人脸图案的阳性实例,剩下的是非人脸图案。注意:搜集具有代表性的(典型的)简单人脸图案是容易的,但是要找到典型的非人脸图案则是相当困难的。通过一种解靴带的方法可以把问题简化些,这个方法是选择性地添加一些图像到训练集中去进行训练处理。从这个训练集得计一个非人脸实例的小集合开始,用机器语言程序(MLP)分类器对这个实例数据库进行训练。然后,他们在一个随机图像次序集中移动人脸探测器,搜集所有被当前系统错误地分类为人脸那些非人脸图案。然后,把这些假阳性(图案)做为新的非人脸实例添加到训练数据库中去。这种解靴带的方法避免了一个明确搜集非人脸图案的典型实例的问题,也被用在后来的文章〔107〕,〔128〕中。
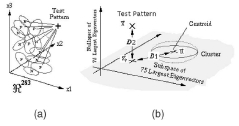
 (图片7,使用Sung和Poggio〔154〕测量这段距离。在一幅输入图像的图案和原型群(类)间计算两段(distance metrics)。(a)给出一幅测试图案,计算位于图像图案和每个群(类)之间的距离。由12段位于这个测试图案和这个模型的12类质心之间的距离组成的一个集合。(b)每一段位于这个测试图案和一类质心之间的距离,它的度量单位是一个二值的(distance metrics)。D1表示一个Mahalanobis距离,它位于该测试图案的投影和在横跨该类75个最大特征向量的子空间中的这个类质心之间。D2表示欧级里得(Euclidean)距离,它位于该测试图案和它在子空间里的投影之间。因此,一个包含24个值的距离向量的形成是为每个测试图案服务的,并通过一个多层投影得到使用,从而测定这幅输入图案是否属于人脸类(感谢K.-K.Sung和T.Poggio)。)
(图片7,使用Sung和Poggio〔154〕测量这段距离。在一幅输入图像的图案和原型群(类)间计算两段(distance metrics)。(a)给出一幅测试图案,计算位于图像图案和每个群(类)之间的距离。由12段位于这个测试图案和这个模型的12类质心之间的距离组成的一个集合。(b)每一段位于这个测试图案和一类质心之间的距离,它的度量单位是一个二值的(distance metrics)。D1表示一个Mahalanobis距离,它位于该测试图案的投影和在横跨该类75个最大特征向量的子空间中的这个类质心之间。D2表示欧级里得(Euclidean)距离,它位于该测试图案和它在子空间里的投影之间。因此,一个包含24个值的距离向量的形成是为每个测试图案服务的,并通过一个多层投影得到使用,从而测定这幅输入图案是否属于人脸类(感谢K.-K.Sung和T.Poggio)。)
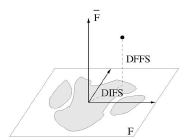
Moghaddam和Pentland〔103〕提出了一种概率可视的研究方法,该方法在一个高维度空间的密度估算中使用特征空间分解。主要成分分析(PCA)被用来定义最能表现一个人脸图案集合的子空间。这些主要成分保持了数据中主要的线性相关性,丢弃了次要的部分。这种方法把向量空间分解为两个互斥互补的子空间:这个主要空间(或特征空间)和它的直交补角。因此,这个对象的密度被分解为两个部分:主要子空间的密度(横跨主要部分)和它直交的部分(就是标准PAC丢弃的部分)(详见图片8)。一个多元高斯和一个混合高斯被用来研究人脸局部特征的统计。然后,使用这些概率密度来识别基于最大可能性估计的对象。这种被提出的方法已经应用在人脸定位、译码和识别中。与典型的特征脸(识别)方法〔163〕相比,这次提到的方法体现了(它)在人脸识别中具有更好的效能。在人脸势必领域,这种技术也仅限于探测的论证。可详见〔76〕。
(图片8,一幅人脸图像空间为分解为任意密度的主要子空间F和它的直交部分(-:位于F上面)F。每个数据点x分解成两个部分:在特征空间里的距离(DIFS)和来自特征空间的距离(DFFS)〔103〕(感谢B.Moghaddam和A.Pentland)。)

 在〔175〕中,提出了一种基于混合要素分析的探测方法。要素分析(FA)是一种统计学的方法,用少量潜在变量来模拟高维度数据的协方差结构。要素分析(FA)在某些方面类似于主要成分分析(PCA)。但是,主要成分分析(PCA),不象要素分析(FA),没有为数据定义一个适当的密度模型,即使对一个数据点译码的代价相对于任何一处的沿主要成分的子空间(例如:在这些方向上没有规格化的密度。)。此外:即使主要成分最大化输入数据的变量值,主要成分分析(PAC)在特征数据有独立干扰时(仍)显得不太健壮,因此,要保留多余的变量。在〔36〕,〔37〕,〔9〕,〔7〕中那些综合实例表明:从PCA子空间的不同类中投影的例子也常常被抹去。在一些有特定结构的实例的情况中,PCA不是标准点分类的最佳方法。Hinton et al.已经应用FA进行数字识别,他们还比较了PCA和FA模型的性能〔61〕。最近,人脸分析器的混合模型被拓展〔49〕和应用在人脸识别〔46〕。所有的研究显示FA在数字和人脸识别上的执行比PCA好。因为姿态、方位、表情和光照影响到人脸的外观,所以图像空间中人脸的分类通过一个多模型密度的模型能更好的实现,其中这个模型的每个形态是从特定人脸外貌的特定特征中捕捉的。他们提出了一种概率(识别)方法,该方法使用一个混合的要素分析器(MFA)来探测大变化下的人脸。使用EM算法估算这个混合模型的参数。
在〔175〕中,提出了一种基于混合要素分析的探测方法。要素分析(FA)是一种统计学的方法,用少量潜在变量来模拟高维度数据的协方差结构。要素分析(FA)在某些方面类似于主要成分分析(PCA)。但是,主要成分分析(PCA),不象要素分析(FA),没有为数据定义一个适当的密度模型,即使对一个数据点译码的代价相对于任何一处的沿主要成分的子空间(例如:在这些方向上没有规格化的密度。)。此外:即使主要成分最大化输入数据的变量值,主要成分分析(PAC)在特征数据有独立干扰时(仍)显得不太健壮,因此,要保留多余的变量。在〔36〕,〔37〕,〔9〕,〔7〕中那些综合实例表明:从PCA子空间的不同类中投影的例子也常常被抹去。在一些有特定结构的实例的情况中,PCA不是标准点分类的最佳方法。Hinton et al.已经应用FA进行数字识别,他们还比较了PCA和FA模型的性能〔61〕。最近,人脸分析器的混合模型被拓展〔49〕和应用在人脸识别〔46〕。所有的研究显示FA在数字和人脸识别上的执行比PCA好。因为姿态、方位、表情和光照影响到人脸的外观,所以图像空间中人脸的分类通过一个多模型密度的模型能更好的实现,其中这个模型的每个形态是从特定人脸外貌的特定特征中捕捉的。他们提出了一种概率(识别)方法,该方法使用一个混合的要素分析器(MFA)来探测大变化下的人脸。使用EM算法估算这个混合模型的参数。
在〔175〕中的另一个(识别)方法是用Fisher的线性判别(FLD)来投影从高维度图像空间到较低维度的特征空间的实例。最近,在线性判别分析的基础上的Fisher人脸(识别)方法〔7〕和其他的方法〔156〕比在若干数据集中人脸识别中比广泛应用的特征脸(识别)方法要好,其中特征脸(识别)方法还包括由光照条件变化下得到的人脸图像组成的Yale人脸数据库。一种可能的解释是与PCA相比,FLD为图案分类提供了更好的投影,即使它的目的是找出最多判别投影的方向。因此,在被投影的子空间中的分类的结果可能比其他方法优越。(详见〔97〕中有关训练集大小的讨论。)在提到的另一个方法中,他们使用Kohonen自组织图(SOM)〔80〕分解若干子累中的这些用于训练的人脸和非人脸的实例。图片9显示了每一个人脸类的模型。根据这些重新用标签表明的例子,计算里面的类和两边的类的稀疏矩阵,因此产生基于FLD的最佳投影。对于每个子类,它的密度被模拟为一个高斯(?函数),该高斯的参数是用最大相似度〔36〕来估算的。为了探测人脸,每一幅输入图像用一个计算类概率的矩形窗口进行扫描。最大相似度的判定标准被用来测定是否探测到人脸。〔175〕中的两种方法已经用〔128〕,〔154〕中由包含619张人脸的225服图像所构成的数据库来测试,实验结果显示:两种方法中MFA的探测率是92.3%,对基于FLD的方法的探测率是96.3%。
(图片9:Yang et al.在〔175〕中使用Kohonen的SOM来得到每个人脸类的原型。每一个原型相当于一个群(类)的中心。)
2.4.3神经系统网络
神经系统网络在许多图案识别问题上都有成功的应用,例如光学特征识别,对象识别和自治式机械操纵。虽然人脸检测可以被当做一个两类图案的识别问题来处理,但是多样神经系统网络体系机构也被提了出来。使用神经系统网络来检测人脸的优点是训练(测试)一个为了捕捉复杂条件中的人脸图案密度的系统的可行性。但是,(它的)一个缺点是这个网络体系结构必须被广泛地接受(多层,多点,研究率等等)从而到达突出的性能。

 Agui et al.在[1]中提出了使用分等级的神经系统网络的一种早期的(识别)方法。第一阶段由两个平行的子网组成,子网的输入值是一幅原始图像的亮度值,且该亮度值是用一个3×3的Sobel过滤器过滤图像得到的。在第二阶段的网络的输入值是由来自子网和萃取到的特征值(例如标准偏差的输入图案的像素值)的输出值组成的,一定量的白色像素的比率达到一个窗口几何力矩中二进制像素的总量。第二阶段的一个输出值意味着输入区域中人脸的存在。实验结果表明:如果测试图像中的所有人脸具有相同的大小,那么这种方法就能探测到人脸。Propp和Samal发展(研究)了一种最早的用于人脸探测的神经系统网络〔117〕。他们的网络由包含1024个输入单元的四层组成,256个单元在第一层隐藏层里,8个单元在第二层的隐藏层里,还有2个输出单元。随后,一个类似的等级神经系统网络在〔70〕中被提了出来。Soulie et al.[148]里的提到的这种早期的方法是使用一种时延神经系统网络〔166〕(用25×25像素的一块能被接纳的区域)来扫描输入图像,检测人脸。为了处理大小的变化,用微波转换来分解这幅输入图像。他们从一个包含120幅图像的测试集中得到如下结果:假阴性率2.7%,假阳性率0.5%。在〔164〕中,Vaillant et al.使用盘旋(convolutional)神经系统网络来探测图像中的人脸。首先,创建20×20像素的人脸和非人脸图像的实例。训练(测试)一个神经系统网络来查找相同比例下人脸的近似定位。训练(测试)另一个网络来测定相同比例下人脸的精确位置。通过第一个网络,给出一幅范围包含选定人脸的图像,做为人脸候选项。这些候选项通过第二个网络来验证。Burel和Carel〔12〕提出了一种人脸检测的神经系统网络,该网络使用Kohonen 的SOM算法〔80〕把大量人脸和非人脸的训练实例压缩成更少的实例。使用一个多层感知器来研究这些人脸/背景分类的实例。检测的阶段包括扫描每一幅不同分辨率的图像。为了每个位置和扫描窗口的大小,用一个标准尺寸来规格化这些内容,且测量亮度平均数和变化的目的是减少光照条件的影响。然后,用一个MLP把每一个规格化的窗口分类。Feraud和Bernier提出了一种使用自联合神经系统网络〔43〕,〔42〕,〔44〕的检测方法。这种思想的基础是〔83〕:使用能执行非线性主要成分分析的五层自联合网络。使用一个自联合网络来检测那么相对于正面视角而言向左和向右转动60°的人脸。也可以利用一个门控网络来为全部处于自联合网络的正面和侧转的人脸探测器分配比重(weights)。在一个由42幅图像组成的小测试集中,他们得到的检测率于〔126〕中的相似。这种方法也被用在LISTEN[23]和MULTRAK[8]。
Agui et al.在[1]中提出了使用分等级的神经系统网络的一种早期的(识别)方法。第一阶段由两个平行的子网组成,子网的输入值是一幅原始图像的亮度值,且该亮度值是用一个3×3的Sobel过滤器过滤图像得到的。在第二阶段的网络的输入值是由来自子网和萃取到的特征值(例如标准偏差的输入图案的像素值)的输出值组成的,一定量的白色像素的比率达到一个窗口几何力矩中二进制像素的总量。第二阶段的一个输出值意味着输入区域中人脸的存在。实验结果表明:如果测试图像中的所有人脸具有相同的大小,那么这种方法就能探测到人脸。Propp和Samal发展(研究)了一种最早的用于人脸探测的神经系统网络〔117〕。他们的网络由包含1024个输入单元的四层组成,256个单元在第一层隐藏层里,8个单元在第二层的隐藏层里,还有2个输出单元。随后,一个类似的等级神经系统网络在〔70〕中被提了出来。Soulie et al.[148]里的提到的这种早期的方法是使用一种时延神经系统网络〔166〕(用25×25像素的一块能被接纳的区域)来扫描输入图像,检测人脸。为了处理大小的变化,用微波转换来分解这幅输入图像。他们从一个包含120幅图像的测试集中得到如下结果:假阴性率2.7%,假阳性率0.5%。在〔164〕中,Vaillant et al.使用盘旋(convolutional)神经系统网络来探测图像中的人脸。首先,创建20×20像素的人脸和非人脸图像的实例。训练(测试)一个神经系统网络来查找相同比例下人脸的近似定位。训练(测试)另一个网络来测定相同比例下人脸的精确位置。通过第一个网络,给出一幅范围包含选定人脸的图像,做为人脸候选项。这些候选项通过第二个网络来验证。Burel和Carel〔12〕提出了一种人脸检测的神经系统网络,该网络使用Kohonen 的SOM算法〔80〕把大量人脸和非人脸的训练实例压缩成更少的实例。使用一个多层感知器来研究这些人脸/背景分类的实例。检测的阶段包括扫描每一幅不同分辨率的图像。为了每个位置和扫描窗口的大小,用一个标准尺寸来规格化这些内容,且测量亮度平均数和变化的目的是减少光照条件的影响。然后,用一个MLP把每一个规格化的窗口分类。Feraud和Bernier提出了一种使用自联合神经系统网络〔43〕,〔42〕,〔44〕的检测方法。这种思想的基础是〔83〕:使用能执行非线性主要成分分析的五层自联合网络。使用一个自联合网络来检测那么相对于正面视角而言向左和向右转动60°的人脸。也可以利用一个门控网络来为全部处于自联合网络的正面和侧转的人脸探测器分配比重(weights)。在一个由42幅图像组成的小测试集中,他们得到的检测率于〔126〕中的相似。这种方法也被用在LISTEN[23]和MULTRAK[8]。
Lin et al.使用由概率决定的神经系统网络(PDBNN)〔91〕来提出了一种人脸检测系统。这种PDBNN的体系结构与一个使用改进的研究(learning)标准和概率说明的光线基本函数(RBF)的网络相似。与神经系统网络把整幅人脸图像转变成一组训练向量的亮度值不同,他们首先一包含眉毛、眼睛和鼻子的人脸区域中的亮度和边缘信息为基础,萃取特征向量。萃取的两个特征向量被流入两个PDBNN(网络),混合输入值测定分类的结果。Sung和Poggio〔154〕使用一个包含23幅图像的集合,他们的实验结果表明:(该系统)于其他主要的基于神经系统网络的人脸检测器〔154〕,〔128〕具有可比的性能。
在所有使用神经系统网络的人脸检测方法,Rowley et al.〔127〕,〔126〕,〔128〕对最有意义的文章进行了论证。尽管Sung〔152〕使用一个神经系统网络来查找用于对使用距离度量器的人脸和非人脸图案分类的判别式函数,一个多层神经系统网络被用来研究人脸和非人脸图案,这些图案来自于人脸/非人脸图像(例如,亮度和空间相关的像素)。他们也使用多样的神经系统网络和若干仲裁方法来改进性能,而Burel和Carel〔12〕使用一个简单的网络,Vaillant et al.〔164〕使用两个用于分类的网络。这里有两个主要部分:多样的神经系统网络(用于探测人脸图案)和一个仲裁(判断)模块(用来从多样探测结果中提炼最后的判断结果)。如图片10所示,该方法的第一个部分是一个接收20×20像素图像的区域,且输出值的范围在-1到1之间的神经系统网络。给出一个测试图案,这个被训练(测试)的神经系统网络的输出值就表示了一个非人脸(输出值接近-1)或人脸图案(输出值接近1)。为了探测出图像中任何位置的人脸,这个神经系统网络被应用到图像的所有位置上了。为了探测大于20×20像素的人脸,输入图像被重复抽样,且在每个范围中都要用到这个网络。使用将近1050个不同尺寸、方位、姿势和亮度的人脸实例来训练(测试)这个网络。在每一幅训练(测试)图像中,眼睛,鼻尖,角落和嘴巴中央都被手工地标识了,且被用来规格化,使人脸具有相同的尺寸、方位和姿势。这个网络的第二个不符是合并重叠探测和对多样网络的输出值进行判断。简单判断方案例如逻辑判断(与/或)和投票,以此改进性能。以一个包含144张人脸的24幅图像所组成的测试集为基础,Rowley et al.〔127〕报告了用不同的判断方案实现的若干系统,它们比Sung和Poggio的系统减少了计算代价,且具有更高的识别率。

(图片10,Rowley方法〔128〕的系统图表。每一张人脸在流入一个全面的神经系统网络前被预处理。若干仲裁方法被用来测定基于这些网络的输出值的人脸是否存在(感谢H.Rowley,S.Baluja和T.Kanade)。)
Rowley〔127〕和Sung〔152〕提出的一个限制算法是他们能仅仅探测竖直的正面的人脸。最近,Rowley et al.〔129〕使用一个路由网络来拓展了这个方法,以此探测旋转的人脸,其中这个网络能处理每一个测定可能的人脸方位的输入窗口,然后是该窗口旋转到规定的方位;这个旋转窗口出现在上面描述的神经系统网络。尽管如此,这个新的系统在竖直人脸方面的探测率比竖直探测器的探测率低。不过,在包含少量假阳性(人脸)的两个大测试集中,该系统仍能识别79.6%的人脸。
2.4.4支持向量(矢量)机
在Osuna et al.〔107〕中,支持向量(矢量)机(SVMs)被用来进行人脸检测。支持向量(矢量)机可以被看做是一种用来训练(测试)多项式函数,神经系统网络和光线基本函数(RBF)分类器的新范例。而许多训练(测试)分类器的方法(例如,贝叶斯定理,神经系统网络和BRF)都是基于最小化训练(测试)错误的,也就是,冒着经验主义的危险,支持向量(矢量)机(SVMs)运行器在另一种归纳法则中被称为结构风险最小限度,它的目标是最小化被预料到的普遍性错误的最大限度。一个支持向量(矢量)机(SVMs)分类器是一个线性的分类器,它在分开的超平面被选定时用来最小化那些看不见的测试图案中被预料到的分类错误。最佳超平面是用包含训练(测试)向量的一个小子集的有利联合体来定义的,称之为支持向量。估算这个最佳超平面相当于解决一个棘手的线性二次编程问题。不管用何种方法,计算都要时间和存储空间的加强器。在〔107〕中,Osuna et al.发展(提出)了一种有效的方法来训练(测试)有关大比例问题的SVM,并把该方法应用到人脸探测中。以由10000000幅19×19像素的测试图案组成的两个测试集为基础,他们的系统具有及低的错误率,且运行的时间被Sung和Poggio〔153〕的系统要快将近30倍。SVMs也已经被用来在微波领域〔106〕,〔108〕,〔109〕中探测人脸和步行者。
2.4.5稀疏的扬谷器网络(SNoW)
Yang et al.提出了一种方法是使用稀疏的扬谷器网络学科体系结构〔125〕,〔16〕来检测具有不同特征和表情,不同姿态和不同光照条件下〔176〕的人脸。他们也研究了简单和多范围特征的影响。SNoW(稀疏的扬谷器网络)是一种利用扬谷器更新规律〔92〕得到线性函数的稀疏网络 。为了在(参与判断的有潜在(可能)数目的特征很大)的领域进行研究,它被剪裁得很特殊,但可能是未知的(priori)。该学科体系结构中有些特征是:它的关系稀疏的单元,所有在一个受驱策的数据线路中分配的特征和链接,判定机制和对一个有效更新规律的利用。在训练(探测)基于SNoW的人脸探测器中,来自Olivetti〔136〕,UMIST〔56〕,Harvard〔57〕,Yale〔7〕和FERET〔115〕数据库的1681幅人脸图像被用来捕捉人脸图案的变化。为了比较其他不同的方法,他们用两个容易利用的包含619张人脸的225幅图像所组成的数据集〔128〕来报告结果。执行这种技术和其他在〔128〕数据集1上估算的方法(包括这些使用神经系统网络〔128〕,Kullback相关信息〔24〕,简单贝叶斯分类器〔140〕和支持向量(矢量)机),有5.9%的错误率,而计算率更有效了。
2.4.6简单的贝叶斯分类器
相对于〔107〕,〔128〕,〔154〕中那些模拟完整人脸外貌的方法,Schneiderman和Kanade描述了一种简单贝叶斯分类器来估算局部外貌的连接概率和在多分辨率中人脸图案(人脸的子区域)的位置〔140〕。他们强调局部的外貌,因为一个对象的一些局部图案比其他的要更独特;眼睛周围的亮度图案比脸颊周围的亮度图案要特殊很多。有两个原因使用一个简单贝叶斯分类器(也就是在子区域间的没有统计依赖)。首先,它规定了这些子区域中的条件密度函数的更好的估算。第二,一个简单贝叶斯分类器规定了这样一项其次概率(posterior probability)的功能:该功能是捕捉局部外貌的连接统计和对象的位置。在每一级中,人脸图像被分解成四个矩形的子区域。然后,使用PCA把这些子空间被投影到一个低维度的空间,且把一个有限的图案集量子化,每一个被投影的子区域的统计是从被投影的实例中估算的,以此对局部外貌进行编码。在这样的明确表达下,他们的方法判定:当相似度比预料的概率大时,人脸存在。在〔128〕的数据集1中有93.0%的错误率,被提出的贝叶斯方法具有可比的性能,且能探测一些旋转和侧面的人脸。随后,Schneiderman和Kanade使用微波表现手法(wavelet representations)发展了这种方法,以此检测侧面人脸和汽车〔141〕。
Richert et al.〔124〕利用局部特征的连接统计模型发展了一个相关方法。对于输入的图像,利用多比例和多分辨率的过滤器来萃取局部特征。通过聚类数据,估算这些特征向量(也就是过滤结果)的分类,然后构成一个混合高斯函数。在模型被研究和进一步改进后,利用计算于该模型有关的特征向量的相似度来对测试图像进行分类。它们对人脸和汽车检测的实验结果是一个有意义的好结果。

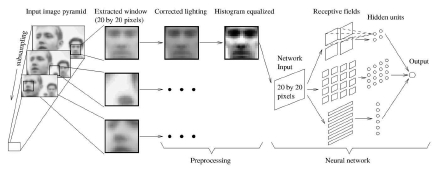
(图片11,用于人脸定位的隐马尔可夫模型(a)观察向量:为了训练(测试)一个HMM,每个人脸实例被转变为一系列观察向量。从一个W×L像素的窗口构造观察向量。通过利用P个重叠的像素来垂直地扫描这个窗口,构造一个观察序列。(b)隐藏的状态:当一个隐马尔可夫模型包含五种被有序观察向量训练(测试)的状态,(b)〔136〕中显示了状态间的分界线。)
2.4.7隐马尔可夫模型
隐马尔可夫模型(HMM)的潜在假设是图案可以被刻画为一个参(变)量的随机处理,且这个处理的参数可以用一种精确的说明详细的方法计算得到。为图案识别问题而发展了隐马尔可夫模型,首先需要把大量隐藏状态判定下来,以此形成一个模型。然后,这个(模型)能训练(测试)HMM来研究位于这些实例的状态间的变化概率,其中,每个实例都是用一有序观察(向量)表示的。训练(测试)一个隐马尔可夫模型的目的是最佳化观察到的训练(测试)数据的概率。,其中这些数据是通过调整用标准Viterbi分割法和Baum-Welch算法〔122〕实现的隐马尔可夫模型的参数得到的。这个隐马尔可夫模型被训练(测试)后,观察到的这个输出概率决定了它所属的这个类。
直观地,一幅人脸图案可以被分成若干诸如前额、眼睛、鼻子、嘴巴和下巴这些区域。然后,人脸图案可以通过一种处理被识别,其中这种处理是用一适当的次序(从上到下,从左到右)观察这些区域。与依赖精确队列的模板匹配或基于外貌的识别方法(这些方法中,例如眼睛和鼻子这样的脸部特征需要依据参考点来很好的排列)不同,这种方法的目的是把脸部区域和一个连续密度的隐马尔可夫模型的状态联系起来。基于隐马尔可夫模型的方法经常把人脸图案处理为一有序观察向量,且每一个向量是一条像素带,如图片11所示。在训练和测试的过程中,用一定的次序(经常是从上到下)扫描一幅图像,且把得到的观察(结果)用一个像素块来表示,如图片11(a)所示。在人脸图案中,利用状态间可能的转变来表示像素带的边界线,如图片11(b)所示,且用一个多元高斯分类模拟这幅图像的一个区域里的数据。一个观察序列由每个块里所有的亮度值构成。输出状态相当于观察(向量)所属的这些类。在这个HMM被训练(测试)后,观察(向量)的输出概率决定了它所属的这个类。HMMs已经被应用在人脸识别和人脸定位方面。Samaria〔136〕显示:HMM的状态训练(测试)相当于脸部区域,如见图片11(b)。换句话说,一种可靠的状态是用来刻画人的前额的观察向量,另一种可靠的状态是用来刻画人的眼睛的观察向量。为了定位人脸,训练(测试)一种HMM来实现从一个大人脸图案集中得到人脸的一般模型。如果从图像的每一个矩形图案中得到的人脸相似度超过某一作用域,则人脸被定位。
Samaria和Young应用1D和假(伪)2DHMMs来进行人脸特征萃取和人脸识别〔135〕,〔136〕。他们的HMMs使用人脸结构来强化状态转换的约束力。即使是象毛发,前额,眼睛,鼻子和嘴巴这些从上到下自然排列的重要脸部区域,它们中的每个区域都被分配给一个在一维连续HMM里的某个状态。图片11显示了这五种隐藏状态。为了训练(测试),每一幅图像一律被从上到下分割为五种状态(也就是,每一幅图像被分成五个不相重叠的大小一样的区域)。然后,同样的分割用Viterbi分割代替,HMM中的这些参数用Buam-Welch重新估算。入图片11(a)所示,每一幅人脸图像的宽度W和长度H被分成长L,宽K的重叠块。在连续块的垂直方向上有P行交迭。从图像的观察序列中得出的这些块,和被训练(测试)的HMM被用来判定输出状态。类似于〔135〕,Nefian和Hayes应用HMMs和Karhunen Loeve转换(KLT)来实现人脸定位和识别〔104〕。与使用为处理的亮度值不同,这些观察向量由(KLT)系数组成,从输入向量计算得到。他们在人脸识别方面的实验结果表明该方法的识别率比〔135〕中的好。在MIT数据库中,包含了432幅单一人脸的图像,这些假(伪)2DHMM系统有90%的(识别)成功率。
Rajagopalan et al.提出两种概率方法用来检测人脸〔123〕。相对于〔154〕,该方法使用一个由多元高斯组成集合来模拟人脸图案的分类,〔123〕中的第一种方法使用高次统计(HOS)来估算密度。类似于〔154〕,使用基于高次统计的图案的六个密度函数来聚类所有人脸和非人脸的未知分类。如〔152〕,一个被用来分类的多层感知器和输入向量,其中该输入向量是由12段位于图像图案之间的间距量(也就是log probability)和12个模型类构成的。在〔123〕中的第二种方法是
