|
1 立题依据
1.1项目背景
农业作为我国的第一产业。世界粮食需求对世界人口增长的要求越来越高[1]。近几年,为促进农业现代化对农村经济的快速发展,国家持续出台相关方针政策,以规范我国农业平稳运行,而农产品价格波动导致市场供需发展不均,从而制约农业持续发展[2]。而农产品的价格波动更多的是因为在某一个地区某一个季节,某一种蔬菜的价格突然因为一些外在的因素而提高。而这样就导致了很多的人跟风,而这一情况必然导致下一季度这种蔬菜的价格必然出现下跌,这样就会出现很多的农户或者商家赚不到钱。加上 现在越来越多的人都注重身体的健康问题,所以无公害农产品现在也越来越受欢迎。所以随着这些的出现,近些年来的无公害农产品(蔬菜)价格是涨了不少。农业是一个有风险的行业。作物生产取决于气候、地理、生物、政治和经济因素。由于这些因素,存在一些风险,可以应用适当的数学或统计方法加以量化。准确地掌握作物历史产量的性质是建模输入的重要依据,有助于农民和政府组织决策过程中制定适当的政策。在计算和信息存储的数据提供了一个最广阔的进展。面临的挑战是从原始数据中提取知识,这就导致了新的方法和技术,如数据挖掘,可以将数据的知识与作物估产结合起来。
1.2项目来源
数据挖掘技术的研究工作,随着近年来数据量的不断增加,并随着社会的迅速发展,获得了不少的研究成果,可以预见数据挖掘技术在农产品价格预测中将会有很大的潜力[3]。
中国在农产品领域的快速发展,甚至超过欧洲、美国等一些发达国家。目前,农业与互联网的运营模式还是以需求侧为主,通常以B2C模式比较常见,近期一些公司率先进入O2O的电子商务模式阶段,也面临着很多问题,还需要不断的探索[4]。农产品价格的波动将如何向非农业部门传导,最终对物价总水平产生影响?基于这些问题,本文以农产品价格波动为核心进行研究,尝试构建一个以特征和影响为维度的农产品价格波动的分析框架[5]。
1.3国内外研究进展
数据挖掘在国内外的农产品方面有许多的应用,很多人都用数据挖掘来预测农产品的价格走向、旅游与现代农业示范园的规划和一些关于推销农产品业务的系统。在这些观点中,都是关于农产品的未来一些发展,运用了数据挖掘技术在农产品的网站上去挖掘需要的数据,从而实现预期的目标。
2 研究的主要内容及预期目标
2.1 数据挖掘技术简述及优点
数据挖掘是指从大量的数据中抽取隐含的、不为人知的、有用的信息。数据挖掘是发现以前未知和潜在有趣的过程,在大数据集的模式(Piatetsky Shapiro和Frawley,1991)。“开采”信息,通常表示为数据集的语义结构的模型,其中模型可用于预测或分类的新数据[6]。数据挖掘也能被描述为试图创建一个数据库中描述的复杂世界的简单的模型,因而我们也可以说数据挖掘是处理大量信息的方法,并且它有助于比人更快的速度发现有用的信息[7]。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现数据挖掘[8]。
2.2 程序设计思路
在农产品(蔬菜)的数据挖掘数据处理中,我们首先要寻找到足够的大量的农产品相关的数据信息的来源,因为拥有大量的数据信息是数据挖掘和数据处理的基础。其次是我们要做一些数据的准备:选择数据,就是确定待挖掘的数据的目标;数据预处理:研究数据的质量,确定将要进行的数据类型;数据转换:就是转换成一个分析模型。然后进行数据的挖掘:选择合适的挖掘算法。最后就是结果分析,主要是对提取的数据信息的可靠性、有效性等进行评估。如图1所示。
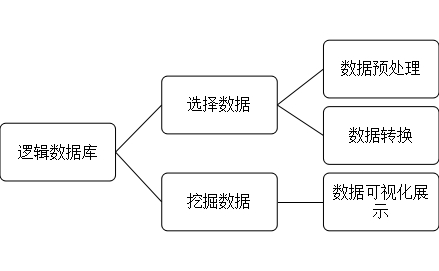 
图1 设计思路
2.3 节点布置方案
一般来说,抓取系统需要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往需要多个抓取程序一起来处理。一般来说抓取系统往往是一个分布式的三层结构。如图2所示:

图2 抓取系统的分布式的三层结构
在对开源工具Python爬虫系统进行研究的基础上,对Python中爬虫模块进行改造,设计并实现了具有更高可配置性、分布式的爬虫程序,根据农村信息化领域特色制定筛选条件,进行涉农网页信息爬取[10]。
2.4 预期目标
基于爬虫技术是利用数据挖掘在网站中爬取到的大量的数据信息,实时的进行数据采集,通过统计信息将数据进行传输、处理,呈现出来,然后将数据以及发送时间存入后台数据库中,进行数据的预处理操作,把处理过的数据进行分类和预测。
3 研究方案
3.1 分析与设计
数据信息模块当中的各种不同农产品数据的类型的数据采集环境中的数据来自农产品网站,然后再把数据信息模块中的数据经过Python工具进行处理,再把模块上的处理过的数据,通过组建的爬虫网络进行数据传输,将数据发送给用户;用户模块接收Python工具模块发送过来的数据,并将这些数据进行处理、分析、整合,由结果分析模块把处理出来的数据经过结果分析模块将数据显示出来;结果分析模块通过建立的后台数据库将数据进行存储。设计的总体结构图如图3所示。



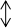
  
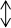 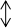
 
图3 总体结构图
3.2 技术路线
3.2.1使用工具
(1)Python编程语言
(2)再用Hadoop处理数据
(3)MySQL数据库
(4)Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架
3.2.2时间序列短期预测方法及模型
随着计量经济建模理论的发展与完善, 时间序列分析与预测得到了广泛应用。目前, 常用的时间序列短期预测方法与模型主要有时间趋势外推
法、季节分解法、指数平滑法和 Box Jenkins 法。
趋势外推法。当时间序列具有某种上升或下降的趋势, 并且无明显的季节波动时, 通常采用简单趋势外推预测模型, 主要包括多项式曲线预测模型、指数曲线预测模型、对数曲线预测模型、生长曲线预测模型等 4种。当既有某种上升或下降趋势, 又存在季节性波动时, 需要加入季节虚拟变量。常用方法有截距变动模型、斜率变动模型、截距和斜率同时变动模型。
季节分解法。将影响时间序列变化的因素分为 4 种: 长期趋势因素( trend, T ) , 表示随着时间变化按照某种规律稳步上升、下降或保持在某一水平上; 季节变动因素( seasonal, S) , 表示在 1 个年度内依一定周期规律性变化; 循环变动因素( circle, C) , 表示以若干年为周期的变动变化; 不规则变动因素 ( irregular, I) , 表示不可控的偶然因素, 如地震、水灾、恶劣天气、罢工和意外事故等。季节分解常用模型有: 乘法模型( Y = T SCI ) 和加法模型( Y =T + S + C+ I) 。
指数平滑法。以本期实际数和本期预测数为基础, 引入 1 个简化加权因子( 平滑系数) 的一种指数平滑预测法。
Box Jenkins 法。如果时间序列是非平稳的, 先将序列变成平稳序列, 变化后的新序列仍保持原时间序列的随机性。主要模型包括: 自回归模型( AR) 、移动平均模型( M A) 、自回归移动平均模型( ARMA) 或差分自回归移动平均模型( ARIM A 或SARIM A) 。
3.2.3数据采集模块
数据采集模块主要由数据采集、数据清洗、数据挖掘、智能分析、可视化展示,如图4所示。
    

  
图4 数据采集模块结构图
节点-链接可以清晰明确地体现层次结构,利用节点表达信息单元,连线表达父子关系,简单易懂[11]。
数据来源:惠农网、农产品网、中国农产品网。
数据清洗:去掉“脏”数据。
数据挖掘:利用Python工具挖掘我们需要的数据。
可视化展示:利用Bootstrap做成一个网站,然后用图表的形式展现。
3.2.4功能实现模块
在功能这一块,我大致做的有以下功能。如图5所示。


   
     
图5 功能模块展示图
3.3数据仓库的组建
Python模块的主要功能是建立、维持和管理网络中爬虫爬下来的数据,并能接收、处理、整合、传输数据;数据采集模块作为主要模块,Python模块根据数据采集模块的功能需要进行代码程序的编写,与数据采集模块相似,然后把这些数据放在一个数据仓库中。
以蔬菜市场为主,用蔬菜指标为度量,从时间、种类、价格、地区等多个维度,采用星型模式构建蔬菜产品的数据仓库DW。如图6所示。数据仓库的主要数据来源于农产品网站。
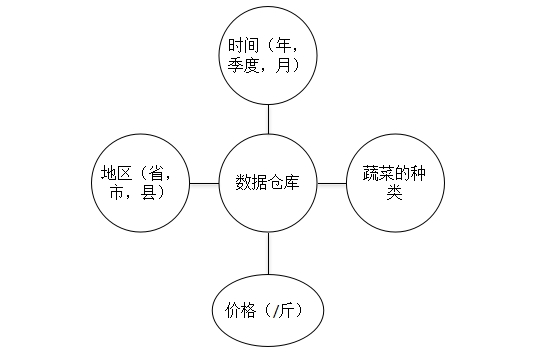
图6 数据仓库的星型拓扑结构
4 论文进度安排
(1)2018.03 -2018.04:了解相关知识,进行开题答辩的编写,完成开题答辩,学习Python的知识。
(2)2018.05 -2018.06: 学习Python数据挖掘技术的基础操作与Python数据挖掘技术的结构算法。
(3)2018.07 -2018.09:完成数据库知识的学习,学习构建SQL数据库。
(4)2018.10 -2018.12:选择好程序所需要的工具,并尝试构建程序模型。
(5)2019.01 -2019.04:准备毕业论文,完成程序模型。
(6)2019.05 -2019.06:进行毕业答辩。
参考文献
[1] International Journal of Advance Research in.Computer Science and Management Studies[J].
Volume 2, Issue 9, September 2014. Available online at: www.ijarcsms.com.
[2] 李诚.农产品价格预测研究[D]. 湖南农业大学. 2014: 224.
[3] 李洋.基于数据挖掘的农产品价格预测研究[D]. 合肥工业大学.2013: TP183.
[4] 吴宇轩.互联网+背景下农产品流通新模式构建研究[D].首都经济贸易大学.2017: F326.
[5] 顾蕊.我国农产品价格波动及其影响研究[D]. 中国农业大学.2013.
[6] Sally Jo Cunningham and Geoffrey Holmes .Developing innovative applications in agriculture using data mining.Department of Computer Science[J].University of Waikato.Hamilton, New Zealand.email: {sallyjo, geoff}@cs.waikato.ac.nz.
[7] 夏春艳.数据挖掘技术与应用[M].冶金工业出版社.2014.8:ISBN 978-7-5024-6768-9.
[8] 百度百科.数据挖掘[OL].计算机科学.
[9] 徐建鹏.程文杰.吴然等.“千企万户”信息服务系统[J].安徽省农村综合经济信息中心.
[10] 张鑫跃.层次数据的关联可视化分析方法研究[D].北京工商大学.2015.TS207.53.
|
