Beyond the Desktop: An Introduction to Cloud Computing
In a world that sees new technological trends bloom and fade on almost a daily basis, one new trend promises more longevity. This trend is called cloud computing, and it will change the way you use your computer and the Internet.
Cloud computing portends a major change in how we store information and run applications. Instead of running program sand data on an individual desktop computer, everything is hosted in the ��cloud����a nebulous assemblage of computers and servers accessed via the Internet. Cloud computing lets you access all your applications and documents from anywhere in the world, freeing you from the confines of the desktop and making it easier for group members in different locations to collaborate.
PART 1 Understanding Cloud Computing
The emergence of cloud computing is the computing equivalent of the electricity revolution of a century ago. Before the advent of electrical utilities, every farm and business produced its own electricity from freestanding generators. After the electrical grid was created, farms and businesses shut down their generators and bought electricity from the utilities, at a much lower price (and with much greater reliability) than they could produce on their own.
Look for the same type of revolution to occur as cloud computing takes hold. The desktop-centric notion of computing that we hold today is bound to fall by the wayside as we come to expect the universal access, 24/7 reliability, and ubiquitous collaboration promised by cloud computing. It is the way of the future.
Cloud Computing: What It Is��and What It Isn��t
With traditional desktop computing, you run copies of software programs on each computer you own. The documents you create are stored on the computer on which they were created. Although documents can be accessed from other computers on the network, they can��t be accessed by computers outside the network.
The whole scene is PC-centric.
With cloud computing, the software programs you use aren��t run from your personal computer, but are rather stored on servers accessed via the Internet. If your computer crashes, the software is still available for others to use. Same goes for the documents you create; they��re stored on a collection of servers accessed via the Internet. Anyone with permission can not only access the documents, but can also edit and collaborate on those documents in real time. Unlike traditional computing, this cloud computing model isn��t PC-centric, it��s document-centric. Which PC you use to access a document simply
isn��t important.
But that��s a simplification. Let��s look in more detail at what cloud computing
is��and, just as important, what it isn��t.
What Cloud Computing Isn��t
First, cloud computing isn��t network computing. With network computing, applications/documents are hosted on a single company��s server and accessed over the company��s network. Cloud computing is a lot bigger than that. It encompasses multiple companies, multiple servers, and multiple networks. Plus, unlike network computing, cloud services and storage are accessible from anywhere in the world over an Internet connection; with network computing, access is over the company��s network only.
Cloud computing also isn��t traditional outsourcing, where a company farms out (subcontracts) its computing services to an outside firm. While an outsourcing firm might host a company��s data or applications, those documents and programs are only accessible to the company��s employees via the company��s network, not to the entire world via the Internet.
So, despite superficial similarities, networking computing and outsourcing are not cloud computing.
What Cloud Computing Is
Key to the definition of cloud computing is the ��cloud�� itself. For our purposes, the cloud is a large group of interconnected computers. These computers can be personal computers or network servers; they can be public or private.
For example, Google hosts a cloud that consists of both smallish PCs and larger servers. Google��s cloud is a private one (that is, Google owns it) that is publicly accessible (by Google��s users).
This cloud of computers extends beyond a single company or enterprise. The applications and data served by the cloud are available to broad group of users, cross-enterprise and cross-platform. Access is via the Internet. Any authorized user can access these docs and apps from any computer over any Internet connection. And, to the user, the technology and infrastructure behind the cloud is invisible.
It isn��t apparent (and, in most cases doesn��t matter) whether cloud services are based on HTTP, HTML, XML, JavaScript, or other specific technologies.
_ Cloud computing is user-centric. Once you as a user are connected to the cloud, whatever is stored there��documents, messages, images, applications, whatever��becomes yours. In addition, not only is the data yours, but you can also share it with others. In effect, any device that accesses your data in the cloud also becomes yours.
_ Cloud computing is task-centric. Instead of focusing on the application and what it can do, the focus is on what you need done and how the application can do it for you. Traditional applications��word processing, spreadsheets, email, and so on��are becoming less important than the documents they create.
PART 2 Understanding Cloud Computing
_ Cloud computing is powerful. Connecting hundreds or thousands of computers together in a cloud creates a wealth of computing power impossible with a single desktop PC.
_ Cloud computing is accessible. Because data is stored in the cloud, users can instantly retrieve more information from multiple repositories. You��re not limited to a single source of data, as you are with a desktop PC.
_ Cloud computing is intelligent. With all the various data stored on the computers in a cloud, data mining and analysis are necessary to access that information in an intelligent manner.
_ Cloud computing is programmable. Many of the tasks necessary with cloud computing must be automated. For example, to protect the integrity of the data, information stored on a single computer in the cloud must be replicated on other computers in the cloud. If that one computer goes offline, the cloud��s programming automatically redistributes
that computer��s data to a new computer in the cloud.
All these definitions behind us, what constitutes cloud computing in the real world?
As you��ll learn throughout this book, a raft of web-hosted, Internet-accessible,
Group-collaborative applications are currently available, with many more on the way. Perhaps the best and most popular examples of cloud computing applications today are the Google family of applications��Google Docs & Spreadsheets, Google Calendar, Gmail, Picasa, and the like. All of these applications are hosted on Google��s servers, are accessible to any user with an Internet connection, and can be used for group collaboration from anywhere in the world.
In short, cloud computing enables a shift from the computer to the user, from applications to tasks, and from isolated data to data that can be accessed from anywhere and shared with anyone. The user no longer has to take on the task of data management; he doesn��t even have to remember where the data is. All that matters is that the data is in the cloud, and thus immediately available to that user and to other authorized users.
From Collaboration to the Cloud: A Short History of Cloud Computing
Cloud computing has as its antecedents both client/server computing and peer-to-peer distributed computing. It��s all a matter of how centralized storage facilitates collaboration and how multiple computers work together to increase computing power.
Client/Server Computing: Centralized Applications and Storage
In the antediluvian days of computing (pre-1980 or so), everything operated on the client/server model. All the software applications, all the data, and all the control resided on huge mainframe computers, otherwise known as servers. If a user wanted to access specific data or run a program, he had to connect to the mainframe, gain appropriate access, and then do his business while essentially ��renting�� the program or data from the server.
Users connected to the server via a computer terminal, sometimes called a workstation or client. This computer was sometimes called a dumb terminal because it didn��t have a lot (if any!) memory, storage space, or processing power. It was merely a device that connected the user to and enabled him to use the mainframe computer.
Users accessed the mainframe only when granted permission, and the information technology (IT) staff weren��t in the habit of handing out access casually. Even on a mainframe computer, processing power is limited��and the IT staff were the guardians of that power. Access was not immediate, nor could two users access the same data at the same time.
Beyond that, users pretty much had to take whatever the IT staff gave them��with no variations. Want to customize a report to show only a subset of the normal information? Can��t do it. Want to create a new report to look at some new data? You can��t do it, although the IT staff can��but on their schedule, which might be weeks from now.
The fact is, when multiple people are sharing a single computer, even if that computer is a huge mainframe, you have to wait your turn. Need to rerun a financial report? No problem��if you don��t mind waiting until this afternoon, or tomorrow morning. There isn��t always immediate access in a client/server environment, and seldom is there immediate gratification.
So the client/server model, while providing similar centralized storage, differed
from cloud computing in that it did not have a user-centric focus; with client/server computing, all the control rested with the mainframe��and with the guardians of that single computer. It was not a user-enabling environment.
Peer-to-Peer Computing: Sharing Resources
As you can imagine, accessing a client/server system was kind of a ��hurry up and wait�� experience. The server part of the system also created a huge bottleneck. All communications between computers had to go through the server first, however inefficient that might be.
The obvious need to connect one computer to another without first hitting the server led to the development of peer-to-peer (P2P) computing. P2P computing defines a network architecture in which each computer has equivalent capabilities and responsibilities. This is in contrast to the traditional client/server network architecture, in which one or more computers are dedicated to serving the others. (This relationship is sometimes characterized as a master/slave relationship, with the central server as the master and the client computer as the slave.)
P2P was an equalizing concept. In the P2P environment, every computer is a client and a server; there are no masters and slaves. By recognizing all computers on the network as peers, P2P enables direct exchange of resources and services. There is no need for a central server; because any computer can function in that capacity when called on to do so.
P2P was also a decentralizing concept. Control is decentralized, with all computers functioning as equals. Content is also dispersed among the various peer computers. No centralized server is assigned to host the available resources and services.
Perhaps the most notable implementation of P2P computing is the Internet. Many of today��s users forget (or never knew) that the Internet was initially conceived, under its original ARPAnet guise, as a peer-to-peer system that would share computing resources across the United States. The various ARPAnet sites��and there weren��t many of them��were connected together not as clients and servers, but as equals.
The P2P nature of the early Internet was best exemplified by the Usenet network. Usenet, which was created back in 1979, was a network of computers (accessed via the Internet), each of which hosted the entire contents of the network. Messages were propagated between the peer computers; users connecting to any single Usenet server had access to all (or substantially all) the messages posted to each individual server. Although the users�� connection to the Usenet server was of the traditional client/server nature, the relationship between the Usenet servers was definitely P2P��and presaged the cloud computing of today.
That said, not every part of the Internet is P2P in nature. With the development of the World Wide Web came a shift away from P2P back to the client/server model. On the web, each website is served up by a group of computers, and sites�� visitors use client software (web browsers) to access it. Almost all content is centralized, all control is centralized, and the clients have no autonomy or control in the process.
Distributed Computing: Providing More Computing Power
One of the most important subsets of the P2P model is that of distributed computing, where idle PCs across a network or across the Internet are tapped to provide computing power for large, processor-intensive projects. It��s a simple concept, all about cycle sharing between multiple computers.
A personal computer, running full-out 24 hours a day, 7 days a week, is capable of tremendous computing power. Most people don��t use their computers 24/7, however, so a good portion of a computer��s resources go unused. Distributed computing uses those resources.
When a computer is enlisted for a distributed computing project, software is installed on the machine to run various processing activities during those periods when the PC is typically unused. The results of that spare-time processing are periodically uploaded to the distributed computing network, and combined with similar results from other PCs in the project. The result, if enough computers are involved, simulates the processing power of much larger mainframes and supercomputers��which is necessary for some very large and complex computing projects.
For example, genetic research requires vast amounts of computing power. Left to traditional means, it might take years to solve essential mathematical problems. By connecting together thousands (or millions) of individual PCs, more power is applied to the problem, and the results are obtained that much sooner.
Distributed computing dates back to 1973, when multiple computers were networked together at the Xerox PARC labs and worm software was developed to cruise through the network looking for idle resources. A more practical application of distributed computing appeared in 1988, when researchers at the DEC (Digital Equipment Corporation) System Research Center developed software that distributed the work to factor large numbers among workstations within their laboratory. By 1990, a group of about 100 users, utilizing this software, had factored a 100-digit number. By 1995, this same effort had been expanded to the web to factor a 130-digit number.
It wasn��t long before distributed computing hit the Internet. The first major
Internet-based distributed computing project was distributed.net, launched in 1997, which employed thousands of personal computers to crack encryption codes. Even bigger was SETI@home, launched in May 1999, which linked together millions of individual computers to search for intelligent life in outer space. Many distributed computing projects are conducted within large enterprises, using traditional network connections to form the distributed computing network. Other, larger, projects utilize the computers of everyday Internet users, with the computing typically taking place offline, and then uploaded once a day via traditional consumer Internet connections.
Understanding Cloud Architecture
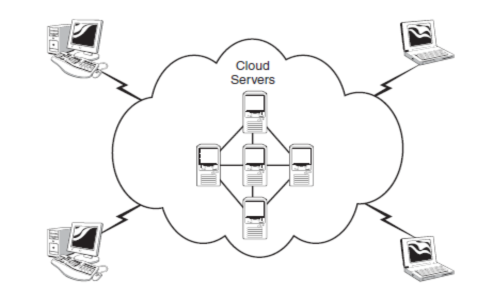
The key to cloud computing is the��cloud����a massive network of servers or even individual PCs interconnected in a grid. These computers run in parallel, combining the resources of each to generate supercomputing-like power.
What, exactly, is the ��cloud��? Put simply, the cloud is a collection of computers and servers that are publicly accessible via the Internet. This hardware is typically owned and operated by a third party on a consolidated basis in one or more data center locations. The machines can run any combination of operating systems; it��s the processing power of the machines that matter, not what their desktops look like.
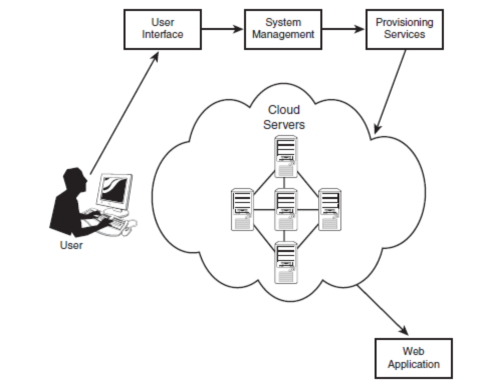
As shown in Figure 1.1, individual users connect to the cloud from their own personal computers or portable devices, over the Internet. To these individual users, the cloud is seen as a single application, device, or document. The hardware in the cloud (and the operating system that manages the hardware connections)is invisible.
This cloud architecture is deceptively simple, although it does require some intelligent management to connect all those computers together and assign task processing to multitudes of users. As you can see in Figure 1.2, it all starts with the front-end interface seen by individual users. This is how users select a task or service (either starting an application or opening a document). The user��s request then gets passed to the system management, which finds the correct resources and then calls the system��s appropriate provisioning services. These services carve out the necessary resources in the cloud, launch the appropriate web application and either creates or opens the requested document. After the web application is launched, the system��s monitoring and metering functions track the usage of the cloud so that resources are apportioned and attributed to the proper user(s).
As you can see, key to the notion of cloud computing is the automation of many management tasks. The system isn��t a cloud if it requires human management to allocate processes to resources. What you have in this instance is merely a twenty-first-century version of old-fashioned data center�Cbased client/server computing. For the system to attain cloud status, manual management must be replaced by automated processes.