基于Java的网络爬虫实时新闻监测分析系统
摘 要
自从大数据的概念被提出后,互联网数据成为了越来越多的科研单位进行数据挖掘的对象。网络新闻数据占据了互联网数据的半壁江山,相比传统媒体,其具有传播迅速、曝光时间短、含有网民舆论等相关特征,其蕴含的价值也愈来愈大。
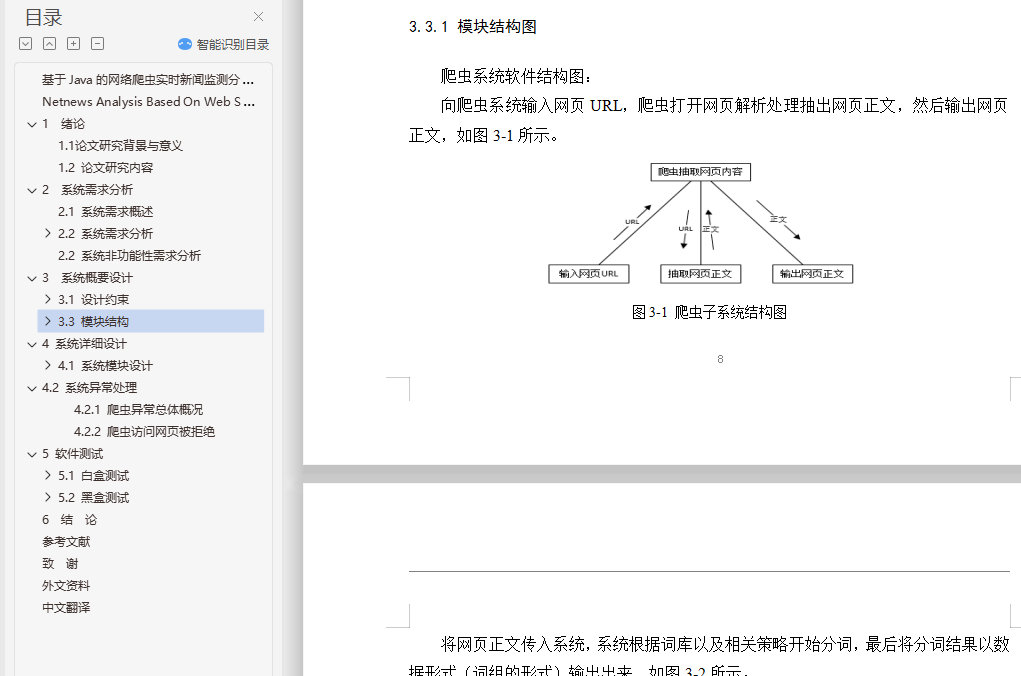
利用相关网络爬虫技术与算法,实现网络媒体新闻数据自动化采集与结构化存储,并利用中文分词算法和中文相似度分析算法进行一些归纳整理,得出相关的新闻发展趋势,体现网络新闻数据的挖掘价值。
如果商业公司能选取其中与自身相关的新闻进行分析,则可以得到许多意想不到的收获,例如是否有幕后黑手故意抹黑、竞争对手情况如何。第一时间掌握与其相关的网络新闻负面效应,动用公关力量,及时修正错误,平息负面新闻,这对当今的企业来说价值是巨大的。
关键词:网络爬虫;网络新闻;数据挖掘
Netnews Analysis Based On Web Spider Technology
Abstract
Since the concept of the big data is put forword, data on the Internet became more and more scientific research units for the object of data mining. Netnews data occupies half of Internet data, compared with traditional media, it has spread rapidly, short exposure time and contains the related characteristics of public opinion.
The related web spider technology and algorithm, to realize the Netnews automatic data collection and structured storage, and summarizes some finishing, draw related news development, reflect the value of Netnews data mining, is the main purpose of this paper.
If a business can choose news which related to their own and to do some professional analysis, they can get many unexpected gains, for example, if there is someone behind deliberately smear, or a competitors. First to master relevant negative effects of Netnews, the use of public power, timely and correct mistakes, to calm the negative news, which is the value of today’s enterprise is enormous.
Key words: web spider; Netnews; data mining